Definitions
Let's define HTB's goal formaly. Some definitions first:
- Class has associated assured rate AR, ceil rate CR, priority P, level and quantum Q. It can has parent. We also know value of actual rate or R. It is rate of packet flow leaving the class and is measured over small period. For inner classes it is Rsum of all descendant leaves.
- Leaf is class which has no children. Only leaf can hold packet queue.
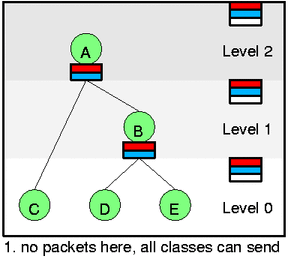
- Level of class determines its position in hierarchy. Leaves has level 0, root classes LEVEL_COUNT-1 and each inner class has level one less than its parent. See pictures below (LEVEL_COUNT=3 there).
- Mode of class is artifical value which can be computed from R,AR,CR. Possible modes are
- Red: R > CR
- Yellow: R <= CR and R > AR
- Green otherwise
- D(c) is list of all backlogged leaves which are descentants of c and where all classes between such leaf (and including it) and c are yellow. In other words D(c) is list of all leaves which would want to borrow from c.
Link sharing goal
Now we can define link sharing goal as definition for R. For each class c it should hold
Rc = min(CRc, ARc + Bc) [eq1]
where Bc is rate borrowed from ancestors and is defined as
Qc Rp
Bc = ----------------------------- iff min[Pi over D(p)]>=Pc [eq2]
sum[Qi over D(p) where Pi=Pc]
Bc = 0 otherwise [eq3]
where p is c's parent class. If there is no p then Bc = 0. Two definitions for Bc above reflects priority queuing - when there are backlogged descendants with numericaly lower prio in D(p) then these should be served, not us. Fraction above shows us that excess rate (Rp) is divided between all leaves on the same priority according to Q values. Because Rp in [2] is defined again by [1] the formulas are recursive.
In more human way we can say that AR's of all classes are maintained if there is demand and no CR's are exceeded. Excess bw is subdivided between backlogged descendant leaves with highest priority according to Q ratios.
Auxiliary delay goal
We also want to ensure class isolation. So that changes in rate of one class should not affect delay in other class unless both are actualy borrowing from the same ancestor. Also hi-prio class should has lower delays than lo-prio assuming they are both borrowing from the same level.
CBQ note
If you look at [1] you will see that our goals are more restricted subset of CBQ goals. So that if we can satisfy HTB goals than we also satisfy CBQ's one. Thus HTB is kind of CBQ.
HTB scheduler
Here I will often put Linux implementation specific function or variable names into parens. It will help you to read source code.
There is tree of classes (struct htb_class) in HTB scheduler (struct htb_sched). There is also global so called self feed list (htb_sched::row). It is the rightmost column on pictures. The self feed is comprised of self slots. There is one slot per priority per level. So that there are six self slots on the example (ignore while slot now). Each self slot holds list of classes - the list is depicted by colored line going from the slot to class(es). All classes in slot has the same level and priority as slot has.
The self slot contains list of all green classes whose have demand (are in D(c) set).
Each inner (non-leaf) class has inner feed slots (htb_class::inner.feed). Again there is one inner feed slot per priority (red-high, blue-low) and per inner class. As with self slots there is list of classes with the same priority as slot has and the classes must be slot owner's children.
Again the \ninner slot holds list of yellow children which are in D(c).
The white slot on self feed doesn't really belong there but it was more convenient to draw it as such. It is wait queue per level (htb_sched::wait_pq, htb_class::pq_node). It hold list of all classes on that level which are either red or yellow. Classes ar sorted by wall time (htb_class::pq_key) at which they will change color (htb_class::mode). It is because the color change is asynchronous.
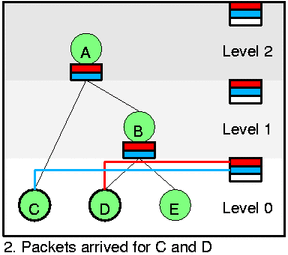
Probably you already see that if we are able to keep all cleasses on correct lists then selecting of next packet do dequeue is very simple. Just look at the self feed list and select the nonempty slot (one with a line) with lowest level and highest prio. There is no such one at pict 1. so that no packet can be send. On 2. it is red slot at level 0 thus class D can send now.
Let's look closely at the first two pictures. At 1. there is no backlogged leaf (all such leaves are drawn by thin circle) so that there is nothing to do. At 2. packets arrived for both C and D. Thus we need to activate these classes (htb_activate) and because they are both green we add them directly to their appropriate self slots. Dequeue would select D now and continue to C if it can't drain packet from C (unlikely).
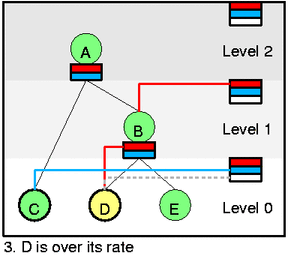
Let's assume that packet was dequeued (htb_dequeue) from D (htb_dequeue_tree) and we charged the packet size to leaky bucket (htb_charge_class). It forced D to go over its rate and changes color to yellow. As part of this change (htb_change_class_mode) we need to remove it from self feed (htb_deactivate_prios and htb_remove_class_from_row) and add to B's inner feed (htb_activate_prios). It also recursively adds B to self feed (htb_add_class_to_row). Because D will return to green state after some time we add it to priority event queue (htb_add_to_wait_tree) at its level (0).
Dequeue would now select class C even if it is lower prio than D. It is because C is at lower level and to compute [eq2] correctly we have to serve lower levels first. It is also intuitively ok - why to borrow if someone can send without it.
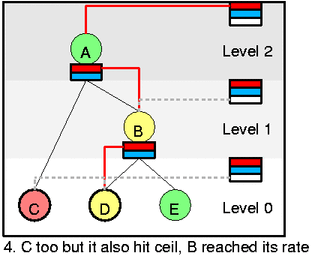
Let's assume that we dequeued C now and it changed state to red (ceil was reached). In this state C can't even borrow. Also assume that some packets was then drained from D and thus B changed to yellow. Now you should be able to explain all steps: remove B from self list, add it to wait and add A to self. Add B to A's inner feed. Add C to wait.
Now you can clearly see how self and inner feed list creates path for borrowing. It is the line at pict 4. going from the top self slot down to D. And yes, D is now the only one who can send.
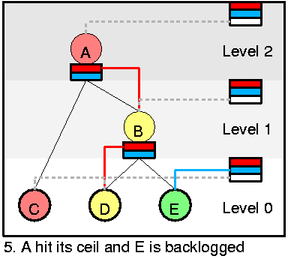
Let's complicate it more. A hits its ceil and E starts to be backlogged. C returned to green. Changes are trivial only you can see that inner feeds are maintained even if the are not used. Look at the red feed which ends at A ... This picture also shows that more than one class can be on the same feed. E and C can be dequeued at the same time. To ensure correct distribution by Q as requested in [eq2] then as long as this state persist we have to apply DRR and cycle over both classes. It is simpler to say but harder to do. Let's look closer at it.
The class lists attached to inner or self feeds are rb-trees in reality. Hence each such list is sorted by its classid. Classid is constant for hiven hierarchy. We remember for each self slot active class from the list (htb_sched::ptr). Then it is fast to find leaf to dequeue - just follow (htb_lookup_leaf) ptrs from self feed thru inner feeds (htb_class::inner.ptr) to a leaf. When DRR decides that its quantum was exhausted (htb_dequeue_tree) we increment ptr (htb_next_rb_node) which led us to the leaf. The next tree traversal (htb_lookup_leaf) will propagate the change to the upper levels.
You can ask why the list should be sorted by classid. It is simple - DRR theory assumes that backlogged class remain on the same position. Only then DRR properties hold. In HTB the class migrates between lists too often and this would adversely affect precision of ratios.
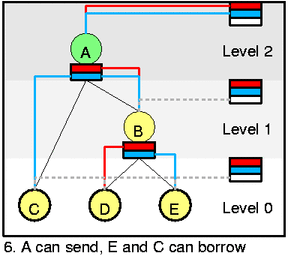
The last and very interesting picture. Three classes changed, A can send E and C are yellow now. The important thing here is to understand that inner class can be active for more priorities (htb_class::prio_activity) while leaf only for one (htb_class::aprio). So that you can see red/blue pair going from self feed to A and B and forking to D and E. Also you can see the same as at 5. but with inner feed now. A serves both C and B (and thus E) at blue/low prio. If there were not D active we would have to dequeue C and E using DRR.
Implementation details
Paragraph above should be enough to understand the code. Only a few notes. There are htb_sched::row_mask[level] which tells us which prios are active on single level. For picture 6 the row_mask = { 0,0,3 }, for pict 3 it would be { 2,1,0 }. It allows for faster eligible level lookup.
The htb_dequeue code applies all pending changes in even queue for the level which is going to dequeue. It is also reason why event queue is split per level - we need not to apply changes to level 1 or 2 classes as in picture 5 when it is enough to apply only those from level 0 and then dequeue level 0. It is because of fact that on higher level prio queue can be no event which would prevent lower level from having green classes.
There is short-circuit for event existence test. Because we often need to test whether there is event for this time I added htb_sched::near_ev_cache per level which holds time of nearest event in jiffies. Fast test is then enough. Typicaly 10-30% speedup.
Color is called mode in the code. Corelation is 0=Red=HTB_CANT_SEND, 1=Yellow=HTB_MAY_BORROW, 2=Green=HTB_CAN_SEND. It is computed in htb_class_mode as leaky bucket [2]. Note the there is globaly defined HTB_HYSTERESIS which adds hysteresis of "burst" size to the mode computation. It means that there is less mode changes and I measured 15% speedup.
Waitlist presence rule. The class is on its waitlist everytime when class mode is not HTB_CAN_SEND (Green).
Linux qdisc should support explicit drop request. It is very hard to do it here so that I have to add special htb_class::leaf.drop_list along with htb_sched::drops list per priority. These holds all active classes for given level. During drop I select the first one from lowest prio active list.
HTB uses "real" DRR as defined in [4]. CBQ in Linux uses one where the quantum can be lower than MTU - it is more generic but it is also no longer O(1) complexity. It also means that you have to use right scale for rate->quantum conversion so that all quantums are larger than MTU.
Acknowledments
I'd like to say thanks to numerous people from Linux world who helped and motivated me a lot.
[1] Link-sharing and Resource Management models for Packet Networks, Sally Floyd and Van Jacobson, 1995
[2] Leaky Bucket, J. Turner, IEEE vol 24 1986
[3] HTB for Linux, http://luxik.cdi.cz/~devik/qos/htb
分层令牌桶理论
Martin Devera又名devik([email protected])
最后更改:5.5.2002
定义
让我们形成HTB的目标。一些定义首先:
- 类具有相关联的保证率AR,小区速率CR,优先P,水平和量子Q。它可以有父母。我们也知道实际费率或R的价值。离开班级的数据包流量是在很短的时间内测量的。对于内部类,它是所有后代叶的R和。
- 叶是没有孩子的班级。只有leaf才能保存数据包队列。
- 等级类决定了它在层次中的位置。叶子的级别为0,根级别为LEVEL_COUNT-1,每个内部级别的级别比其父级别小1。见下面的图片(LEVEL_COUNT = 3)。
- 类的模式是人工价值,可以从R,AR,CR计算 。可能的模式是
- 红色:R > CR
- 黄色:R <= CR且R > AR
- 否则为 绿色
- D(c)是所有积压的叶子的列表,它们是c的下降,并且这种叶子(包括它)和c之间的所有类别都是黄色的。换句话说,D(c)是想要从c借用的所有叶子的列表。
链接共享目标
现在我们可以将链接共享目标定义为R的定义。对于每个类c,它应该成立
Rc = min(CRc,ARc + Bc)[eq1]
其中Bc是从祖先借来的利率,定义为
Qc Rp
Bc = ----------------------------- iff min [Pi over D(p)]> = Pc [eq2]
sum [
奇数超过D(p),其中Pi = Pc] Bc = 0否则[eq3]
其中p是c的父类。如果没有p,那么Bc = 0.上面Bc的两个定义反映了优先级排队 - 当D(p)中存在具有数值较低prio的积压后代时,则应该提供这些,而不是我们。上面的分数向我们显示,根据Q值,在相同优先级的所有叶子之间划分超额率(Rp)。因为[2]中的Rp再次由[1]定义,所以公式是递归的。
以更人性化的方式,我们可以说如果有需求并且没有超过CR,则维持所有类别的AR。根据Q比率,过多的bw在具有最高优先级的积压后代叶子之间细分。
辅助延迟目标
我们还希望确保类隔离。因此,一个班级的比率变化不应该影响其他班级的延迟,除非两者都是从同一祖先借用的。此外,如果他们都是从同一级别借用,那么hi-prio类应该具有比lo-prio更低的延迟。
CBQ备注
如果你看一下[1],你会发现我们的目标是更有限的CBQ目标子集。因此,如果我们能够满足HTB目标,那么我们也会满足CBQ的目标。因此,HTB是一种CBQ。
HTB调度程序
在这里,我经常将Linux实现特定的函数或变量名称放入parens中。它将帮助您阅读源代码。
HTB调度程序(struct htb_sched)中有类树(struct htb_class)。还有全球所谓的自助饲料清单(htb_sched :: row)。这是图片上最右边的一栏。自馈由自槽组成。每个级别每个优先级有一个插槽。因此示例中有六个自我插槽(现在忽略插槽)。每个自助槽都包含类列表 - 列表由从插槽到类的彩色线描绘。插槽中的所有类都具有与插槽相同的级别和优先级。
该自插槽包含了所有的名单绿色类,它们有需求(在d(c)设置)。
每个内部(非叶)类都有内部进给槽(htb_class :: inner.feed)。同样,每个优先级(红 - 高,蓝 - 低)和每个内部类都有一个内部进给槽。与自己的插槽一样,有一个与插槽具有相同优先级的类列表,类必须是插槽所有者的子节点。
同样,\ ninner槽中包含D(c)中的黄色子项列表。
自动送纸上 的白色插槽并不真正属于那里,但绘制它本身更方便。它是每个级别的等待队列(htb_sched :: wait_pq,htb_class :: pq_node)。它包含该级别上所有类别的列表, 红色或黄色。类按照墙时间(htb_class :: pq_key)排序,它们将在其中更改颜色(htb_class :: mode)。这是因为颜色变化是异步的。
可能你已经看到,如果我们能够将所有的清单保存在正确的列表上,那么选择下一个数据包确实是非常简单的。只需查看自助列表,然后选择具有最低级别和最高prio的非空插槽(一个带有一行)。图1中没有这样的,因此不能发送数据包。在2.它是0级的红色插槽,因此D级现在可以发送。
让我们仔细看看前两张图片。在1处,没有积压的叶子(所有这些叶子都是由细圆圈绘制的),因此无所事事。在2. C和D都到达的数据包。因此我们需要激活这些类(htb_activate),因为它们都是绿色的,我们将它们直接添加到适当的自我插槽中。Dequeue将立即选择D并继续到C,如果它不能从C中排出数据包(不太可能)。
假设数据包从D(htb_dequeue_tree)出列(htb_dequeue),我们将数据包大小计入漏桶(htb_charge_class)。它迫使D超过其速率并将颜色变为黄色。由于这种变化(htb_change_class_mode)的一部分,我们需要从自我饲料(htb_deactivate_prios和htb_remove_class_from_row)将其删除,并添加到B的内部供(htb_activate_prios)。它还递归地将B添加到自我馈送(htb_add_class_to_row)。因为D将在一段时间后返回到绿色状态,我们将其添加到其级别(0)的优先级事件队列(htb_add_to_wait_tree)。
Dequeue现在会选择C类,即使它是低于D的prio。这是因为C处于较低的水平并且正确地计算[eq2]我们必须首先服务于较低的水平。它也很直观 - 如果有人可以在没有它的情况下发送,为什么要借用它。
让我们假设我们现在将C队列化,并将状态改为红色(达到了ceil)。在这种状态下C甚至无法借用。还假设一些数据包随后从D中排出,因此B变为黄色。现在您应该能够解释所有步骤:从自我列表中删除B,将其添加到等待并将A添加到自己。将B添加到A的内部Feed中。添加C等待。
现在,您可以清楚地看到自我和内部订阅源列表如何创建借用路径。它是图4中的线。从顶部自我槽向下到D.是的,D现在是唯一可以发送的人。
让我们更复杂一点。击中它的ceil,E开始积压。C回到绿色。变化是微不足道的,只有你可以看到即使不使用内部提要也会保持。查看以A结尾的红色Feed ...此图片还显示多个类可以在同一个Feed上。E和C可以同时出列。为了确保按照[eq2]的要求按Q正确分配,只要这个状态持续存在,我们就必须应用DRR并在两个类上循环。说起来更简单但更难做到。让我们仔细看看吧。
附加到内部或自我馈送的类列表实际上是rb-tree。因此,每个这样的列表按其classid排序。Classid对于hiven层次结构是常量。我们记得列表中的每个自我槽活动类(htb_sched :: ptr)。然后快速找到要出队的叶子 - 只需跟随(htb_lookup_leaf)ptrs从自我馈送到内部提要(htb_class :: inner.ptr)到叶子。当DRR决定其量子耗尽时(htb_dequeue_tree),我们增加ptr(htb_next_rb_node),这导致我们进入叶子。下一个树遍历(htb_lookup_leaf)会将更改传播到上层。
你可以问为什么列表应该按classid排序。这很简单 - DRR理论假设积压的类保持在同一位置。只有DRR属性才有效。在HTB中,类经常在列表之间迁移,这会对比率的精确度产生不利影响。
最后也是非常有趣的图片。三个班级改变了,A可以发E和C现在是黄色。这里重要的是要理解内部类可以激活更多的优先级(htb_class :: prio_activity),而叶子只有一个(htb_class :: aprio)。因此,您可以看到红色/蓝色对从自动进给到A和B并且分叉到D和E.此外,您可以看到与5相同,但现在使用内部进给。A在蓝色/低prio下同时为C和B(以及因此E)提供服务。如果没有D活动,我们将不得不使用DRR将C和E出列。
实施细节
上面的段落应该足以理解代码。只有几个笔记。有htb_sched :: row_mask [level]告诉我们哪个prios在单个级别上是活动的。对于图6,row_mask = {0,0,3},对于图3,它将是{2,1,0}。它允许更快的符合条件的级别查找。
htb_dequeue代码将偶数队列中的所有挂起更改应用于将要出列的级别。这也是为什么每个级别拆分事件队列的原因 - 我们不需要将更改应用到级别1或2级别,如图5所示,当它足以仅应用级别0然后出列级别0时。这是因为事实在更高级别的prio队列中,没有任何事件会阻止较低级别的绿色类。
事件存在测试存在短路。因为我们经常需要测试此时是否有事件,所以我在每个级别添加了htb_sched :: near_ev_cache,它在jiffies中保存了最近事件的时间。那么快速测试就足够了。典型的10-30%加速。
颜色在代码中称为模式。核心化为0 =红色= HTB_CANT_SEND,1 =黄色= HTB_MAY_BORROW,2 =绿色= HTB_CAN_SEND。它在htb_class_mode中计算为漏桶[2]。注意有全局定义的HTB_HYSTERESIS,它为模式计算增加了“突发”大小的滞后。这意味着模式变化较少,我测量了15%的加速。
等候名单存在规则。每当班级模式不是HTB_CAN_SEND(绿色)时,班级就会在等候名单上。
Linux qdisc应该支持显式丢弃请求。这里很难做到这一点,所以我必须为每个优先级添加特殊的htb_class :: leaf.drop_list以及htb_sched :: drops列表。这些包含给定级别的所有活动类。在删除期间,我从最低prio活动列表中选择第一个。
HTB使用[4]中定义的“真实”DRR。Linux中的CBQ使用量子可以低于MTU的CBQ - 它更通用但它也不再是O(1)复杂度。这也意味着您必须使用正确的比例进行速率 - >量子转换,以便所有量子都大于MTU。
Acknowledments
我要感谢来自Linux世界的许多人,他们帮助并激励了我很多。
[1]分组网络的链路共享和资源管理模型,Sally Floyd和Van Jacobson,1995
[2] Leaky Bucket,
J。Turner ,IEEE vol 24 1986 [3] HTB for Linux,http://luxik.cdi。 CZ /〜devik / QOS / HTB
[4]的有效的公平排队使用差额轮询,M. Shreedhar和G. Varghese表示
[5] WF2Q:最坏情况下的公平加权公平排队,JCR Bennet和辉张
[4] Efficient Fair Queuing using Deficit Round Robin, M. Shreedhar and G. Varghese
[5] WF2Q: Worst-case Fair Weighted Fair Queuing, J.C.R. Bennet and Hui Zhang