概述
在计算机网络这门课中,往往是将各层协议拆开一章一章的讲,每层协议是干嘛的,都各种怎么工作的。但如果有人问,这些协议之间怎么协调工作,有什么关系,往往处于懵逼状态。
网络分层
网络为什么分层,其实理解很简单,复杂的东西都要分层。就像写代码,有Controller层,service层,dao层等,如果这个代码很复杂,都写在一个类里里,不利于你后期维护(可能过两天你自己都看不懂了),和同事之间的交流沟通也不方便。所以复杂的程序都要分层,这是基本的程序设计要求。

这是一次用户发起的请求,浏览器用http协议打包用户的请求,然后传给下一层,调用下一层函数,这个函数会在这个网络包里加上一个TCP头,记录下源端口号,目的端口号,然后在调用下一层的函数,这个函数会加一个IP的头,记录源IP地址和目标IP的地址,然后在调用下一次函数,这个函数又加了一个本机器的MAC地址和目标MAC地址。这个数据包完整后,就可以从网口发出去。
网卡检测到这个网络包的目的地址是指向自己的,把这个数据包拿进来调用一段函数来处理这个网络包,把属于这层的东西剥离出去,然后调用另一层的一个函数(process_layer3())来处理这个网络包。这一层检测一下,目标IP是不是对上自己的IP,如果IP对不上,就转发出去,若是对上IP,取下属于这层的IP头,在调用下一层的函数来处理。那是调用TCP函数还是UDP的函数处理哪,这个就得看协议字段,我这次请求是TCP的,就调用TCP的函数取下TCP头,然后查看这是一个发起,还是应答,或者是一个正常数据包,如果是发起或者应答,还需要发送一个回复包,若是一个正常数据包,根据端口号就直接交给应用去处理,然后浏览器解析html,用户现实界面。
网络上跑的包,都是完整的,可以有下层没上层,绝对不可能有上层没下层。这有点类似于俄罗斯套娃,一层连着一层,一开始是个很小的套娃,套一层又套一层,套完后就是一个完整的套娃。网络世界中也是一样的,http层数据包,在套上TCP层,在套上IP层,又套上MAC层,所有机制都得运行一遍才能成功从网口发出去。
IP
不管学没学过计算机,一定都会听到的词===>IP。有没有想过,MAC地址就可以标识电脑了,还要IP干嘛,我刚开始也模糊,后面才逐渐有点头绪(但现在也不知道理解是否全对,毕竟计算机网络小白)。MAC地址与设备是一 一对应在局域网内是唯一的,如果在局域网内,MAC地址直接通信是没有问题的,每次有消息的时候,各个主机都接收一下,对照下是不是自己的MAC地址,如果不是,就直接丢弃,对上就接收并处理。但是每次有消息都得接收和处理有点费事,于是出现了交换机,交换机记录所有与之连接的MAC地址并与端口一一对应,现在A主机发消息给B主机并带上B主机的MAC地址,现在先到交换机这里,交换机查下记录的MAC对照表,哦,原来你要找B主机,就按照这个端口发给B主机。为什么会有IP哪,以太网MAC地址就可以通信了,但后来有了互联网,兼容以前的模式才有了IP + MAC的通信模式,长春这边的局域网有台A主机要与北京的局域网一台B主机通信。长春的交换机记录了A主机的MAC地址,可能还记录了北京交换机的MAC地址,北京交换机记录了要通信的B主机MAC地址。现在A给交换机发消息,我要找B主机,很遗憾,交换机找不到B主机,因为不是一个局域网内,交换机没记录这个MAC地址,没法通信。
MAC地址是硬件提供商写在网卡中的,MAC地址是唯一,但没办法表示我在互联网的位置,除非维护一个超级大的MAC地址对应表,那寻址效率必定爆炸,而且获取MAC地址是ARP协议完成的,只用MAC地址通信广播风暴就是很难克服的问题,但IP地址解决了这个问题,IP地址是网络提供商给的,你在哪里整个网络都是知道的(类似于定位功能),找到你这个网络,在这个网络环境找到你的MAC就显得容易得多。但是IP地址不总是唯一的,可能我今天在长春这个网络环境,我下线了,我这个IP就会动态分配给别的设备,明天到了北京,又动态分了一个IP地址,然而我的MAC地址总是固定且唯一的,通过这个我网络IP地址和MAC地址就很容易找到我。
ip addr
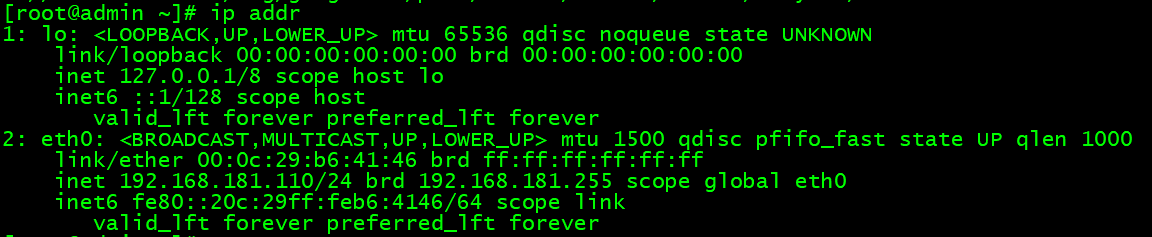
查看ip地址,192.168.181.110就是一个IP地址,总共有四个部分,每部分有8位,总共有32位,理论上可以有42.9亿个IP地址,然而这些显然不能满足日益增长的计算机IP需求,因为不够用,所以有了IPV6,也就是我们的 fe80::20c:29ff:feb6:4146/64,这个有128位,有生之年都不可能分配完,据说可以给地球的每粒沙子分配一个IP,就可以想象有多少IP地址了。IP地址是一个网卡在网络世界的通讯地址,也相当于现实世界的门牌号码,所以不能重复,它包括两个标识码(网络ID + 主机ID)。在同一个物理网络上的所有主机都使用同一个网络ID,网络上的主机(路由器,服务器等)有一个主机ID与其对应,早期IP地址为了便于寻址和层次化构造网络,把IP分为5种类型,即A,B,C,D,E类地址。

A类
A类的地址,8位网络地址,和24位的主机地址组成。地址范围 1.0.0.0 -> 126.255.255.255,A类网络有127个,每个网络能容纳16777214的主机。
B类
B类的地址,16位网络地址,和16位的主机地址组成,地址范围128.0.0.0 -> 191.255.255.255,B类网络有16382个,每个网络可以有六万多主机
C类
C类的地址,24位的网络地址,和8位的主机号,地址范围 192.0.0.0 -> 223.255.255.0,C类网络有209万个,每个网络只能有可怜的254个主机
D类
D类的地址,从图中就可以看到,不分网络地址和主机地址,被称为广播地址,供特殊协议向选定节点发送消息时用,第一个字节是固定的1110,地址范围 224.0.0.0 ->239.255.255.255
E类
E类的地址,保留将来使用。240.0.0.0 -> 255.255.255.254
特殊地址
大家在使用本地测试访问经常用到的 127.0.0.1 表示主机本身,是一个回环测试地址。
在阿里云服务器使用监听地址 0.0.0.0 会有这样的设置,他在IPV4表示的是无效的目标地址,但在服务器端上它表示本机上所有的IPV4网段都能访问该服务
在A,B,C类地址中,各自保留一个区域作为私有地址
- A类:10.0.0.0 -> 10.255.255.255
- B类:172.16.0.0 -> 172.31.255.255
- C类:192.168.0.0 -> 192.168.255.255
CIDR
在一个网吧用C类的IP地址,恐怕地址都不够,但是若是用B类地址,又是一种浪费。于是出现一个折中的办法,那就是无类域间路由,简称CIDR。给某个网络分配3个C类地址,然后适当的方法分配地址,使得3个地址能够聚合成一个地址。如果没有CIDR技术,ISP(地址网络提供商)的路由表就会有三条路由条目,但如果有了CIDR技术,就可以把这三个网段 198.168.1.0 198.168.2.0 198.168.3.0 汇聚成一条路由 198.168.0.0/16,这样ISP的路由表就只记录了一条198.168.0.0/16这一条路由,减少了路由表的条目,但若是ISP连接了一个172.168.1.0的网段,这些网络路由就没办法汇聚。CIRD节省了存储空间加快了查询速度。所以,现在都是用CIDR表示,为此引入子网掩码的概念,就是说网络位的个数可以任意指定,同时也兼容早期IP划分的方法。它将某个IP地址划分成网络地址和主机地址两部分,子网掩码是一个32位地址,用于屏蔽IP地址的一部分,它不能单独存在,必须结合IP地址一起使用,198.168.0.0/16 这个16就是指网络位有多少,在二进制格式中的网络位全为1,然后将二进制格式的子网掩码和二进制的IP地址进行 ‘与’ 运算,就可以得出该IP的网络位。
IP地址:192.168.181.111 二进制:11000000 10101000 10110101 01101110
子网掩码:255.255.255.0 二进制:11111111 11111111 11111111 00000000
运算: & 11000000 10101000 10110101 00000000
结果:192.168.181.0
这就是网络号了
总结
简单的总结合和回忆了对ip的理解,虽然是基础知识,但是lz真的是计算机网络小白,也不知道是否理解准确,有大神有这方面的知识储备,是否可留言讲解下IP。
参考:https://www.jianshu.com/p/e7989a7a0e96