(一)IK分词器的认识
ES默认对英文文本的分词器支持较好,但和lucene一样,如果需要对中文进行全文检索,那么需要使用中文分词器,同lucene一样,在使用中文全文检索前,需要集成IK分词器。
ES的IK分词器插件源码地址:https://github.com/medcl/elasticsearch-analysis-ik
① Maven打包IK插件
② 解压target/releases/elasticsearch-analysis-ik-5.2.2.zip文件
并将其内容放置于ES根目录/plugins/ik
③ 配置插件:
插件配置:plugin-descriptor.properties
④ 分词器(可默认)
词典配置:config/IKAnalyzer.cfg.xml
⑤ 重启ES
⑥ 测试分词器
POST _analyze
{
“analyzer”:“ik_smart”,
“text”:“中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首”
}
注意:IK分词器有两种类型,分别是ik_smart分词器和ik_max_word分词器。
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
提示:也可以直接使用已集成好各种插件的elasticsearch-rtf-master.zip中文发行版,但ES版本为5.1.1。
(二)类型文档映射
-
什么是文档映射
ES的文档映射(mapping)机制用于进行字段类型或分词器确认,将每个字段匹配为一种确定的数据类型。-就相当于在设计表的时候为字段指定类型. -
ES支持哪些数据类型
① 基本字段类型
字符串:text(分词),keyword(不分词) StringField(不分词文本),TextFiled(要分词文本)
text默认为全文文本,keyword默认为非全文文本
数字:long,integer,short,double,float
日期:date
逻辑:boolean
② 复杂数据类型
对象类型:object
数组类型:array
地理位置:geo_point,geo_shape -
默认映射
正常来说应该先为文档类型(相当于数据库中标)指定里面字段类型.但是,原来我们操作的时候没有先指定?为什么呢?因为会走默认映射机制.
ES在没有配置Mapping的情况下新增文档,ES会尝试对字段类型进行猜测,并动态生成字段和类型的映射关系。
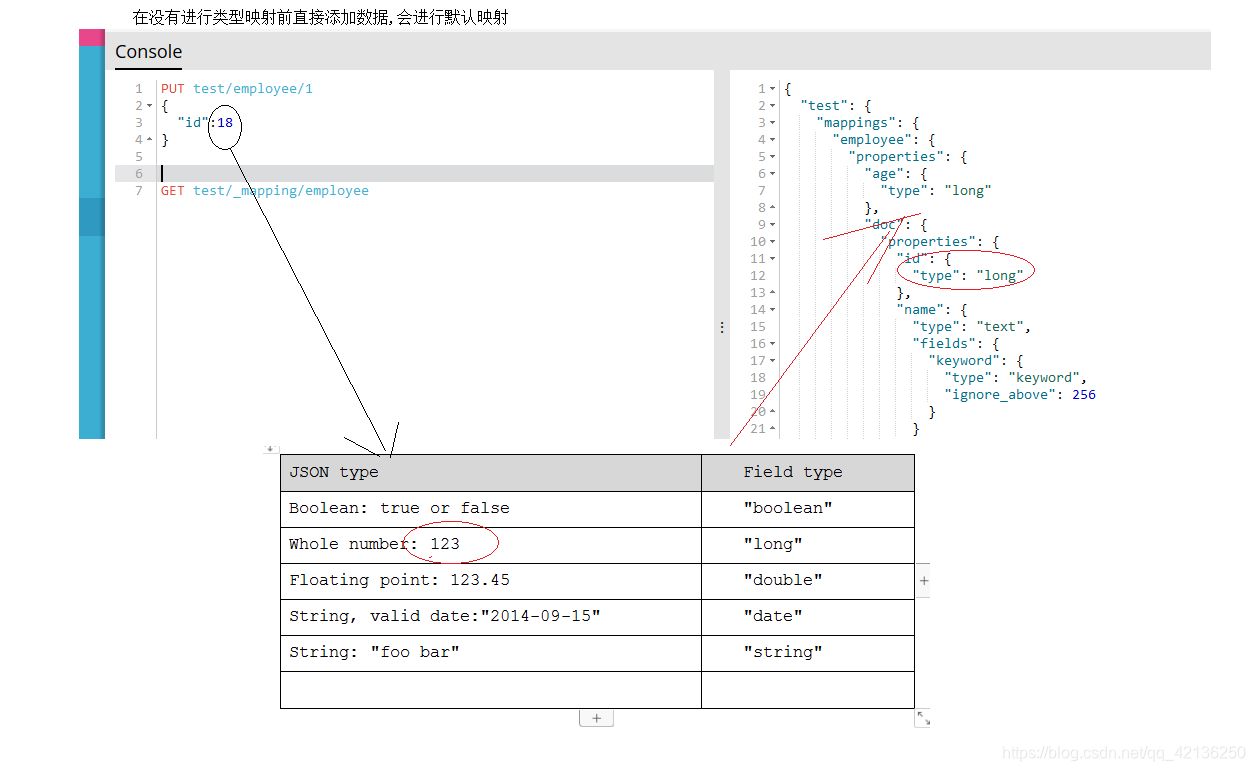
-
自定义映射

-
测试映射
如果已经有数据,不能直接做映射,先删除掉,在添加映射,再添加数据
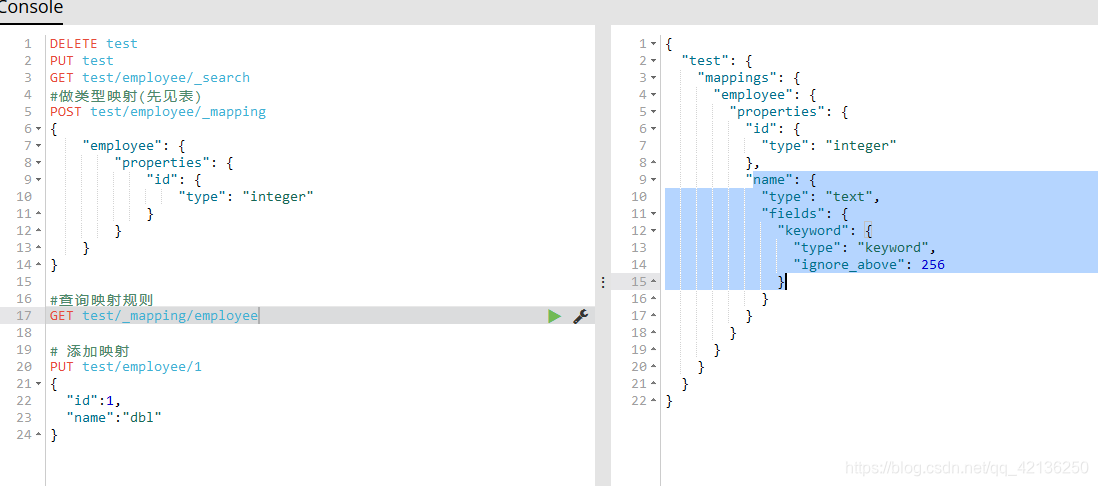
-
映射细节
1)基础类型
直接写
2)对象类型

3)数组
基础类型数组-只需映射里面内容的类型
 对象数组:里面所有对象字段的类型是一样的,映射一个就ok了
对象数组:里面所有对象字段的类型是一样的,映射一个就ok了

-
全局映射
场景:员工类型的id要改为integer,而且部门类型的也要改为integer,甚至所有的都要改.这时每个都去修改非常麻烦.可以设置全局映射.
① 修改默认
一般用来设置_all不要了

② 动态模板:dynamic_templates
PUT _template/global_template //创建名为global_template的模板
{
"template": "*", //匹配所有索引库
"settings": { "number_of_shards": 1 }, //匹配到的索引库只创建1个主分片
"mappings": {
"_default_": {
"_all": {
"enabled": false //关闭所有类型的_all字段
},
"dynamic_templates": [
{
"string_as_text": {
"match_mapping_type": "string",//匹配类型string
"match": "*_text", //匹配字段名字以_text结尾
"mapping": {
"type": "text",//将类型为string的字段映射为text类型
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
{
"string_as_keyword": {
"match_mapping_type": "string",//匹配类型string
"mapping": {
"type": "keyword"//将类型为string的字段映射为keyword类型
}
}
}
]
}
}}