一、手势识别的分类
若按照摄像头的种类(2D摄像头、深度摄像头)来分,可分为两类,1)基于2D摄像头的二维手势识别 和 2)基于3D摄像头(如微软的kinnect)三维手势识别。早期的手势识别识别是基于二维彩色图像的识别技术,所谓的二维彩色图像是指通过普通摄像头拍出场景后,得到二维的静态图像,然后再通过计算机图形算法进行图像中内容的识别。二维的手型识别的只能识别出几个静态的手势动作,而且这些动作必须要提前进行预设好。相比较二维手势识别,三维手势识别增加了一个Z轴的信息,它可以识别各种手型、手势和动作。三维手势识别也是现在手势识别发展的主要方向。不过这种包含一定深度信息的手势识别,需要特别的硬件来实现。常见的有通过传感器和光学摄像头来完成。 手势识别中最关键的包括对手势动作的跟踪以及后续的计算机数据处理。关于手势动作捕捉主要是通过光学和传感器两种方式来实现。手势识别推测的算法,包括模板匹配技术(二维手势识别技术使用的)、通过统计样本特征以及深度学习神经网络技术。本文着重于2D摄像头的手势识别。
二、基于2D摄像头的手势识别
1. 2D摄像头的手势识别分类
2D摄像头的手势识别分类又分为:1)静态手势识别(手型识别)也称静态二维手势识别,识别的是手势中最简单的一类。只能识别出几个静态的手势动作,比如握拳或者五指张开,这种技术只能识别手势的“状态”,而不能感知手势的“持续变化”。说到底是一种模式匹配技术,通过计算机视觉算法分析图像,和预设的图像模式进行比对,从而理解这种手势的含义。因此,二维手型识别技术只可以识别预设好的状态,拓展性差,控制感很弱,用户只能实现最基础的人机交互功能。其代表公司是被Google收购的Flutter。使用他家的软件之后,用户可以用几个手型来控制播放器。2)动态手势识别,仍不含深度信息,停留在二维的层面上。这种技术比起二维手型识别来说稍复杂一些,不仅可以识别手型,还可以识别一些简单的二维手势动作,比如对着摄像头挥挥手。二维手势识别拥有了动态的特征,可以追踪手势的运动,进而识别将手势和手部运动结合在一起的复杂动作。这种技术虽然在硬件要求上和二维手型识别并无区别,但是得益于更加先进的计算机视觉算法,可以获得更加丰富的人机交互内容。在使用体验上也提高了一个档次,从纯粹的状态控制,变成了比较丰富的平面控制。其代表公司是来自以色列的PointGrab,EyeSight和ExtremeReality。
2. 2D摄像头的手势识别的原理
手势有三个主要特征:手型,方向,运动轨迹,一个基于视觉手势识别系统的构成应包括:图像的采集,预处理,特征提取和选择,分类器的设计,以及手势识别。其流程大致如下:
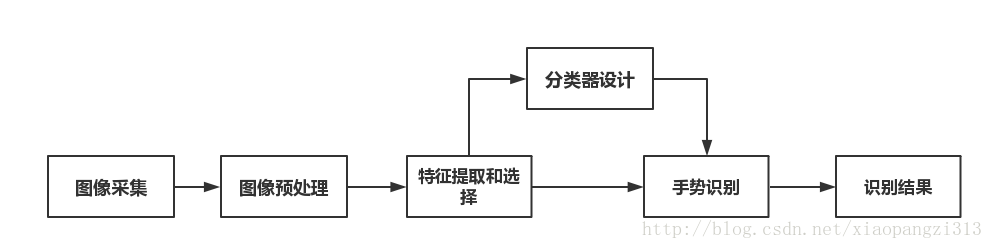
其中有三个步骤是识别系统的关键,分别是预处理时手势的分割,特征提取和选择,手势跟踪,以及手势识别算法。不管是手势检测,或者手势跟踪,识别,特征提取和选择是关键:手势本身具有丰富的形变,运动以及纹理特征,选取合理的特征对于手势的识别至关重要。目前 常用的手势特征有:轮廓、边缘、图像矩、图像特征向量以及区域直方图特征等等。其中,手势检测(手势分割),主要受复杂背景,遮挡,直接光源的亮度变化,外部反射等,常见手部检测特征选取有基于肤色,基于表观,基于模型三种手部检测。手势跟踪,主要受快速运动,双手遮挡,非刚体,非线性,非高斯,多模态。通俗的讲,就是 手势非刚体运动,受到缩放,形变,缺少,模糊,旋转,亮度,视角等因素影响,建议使用基于肤色的SIFT+肤色(ROI)+HOG,粒子滤波,MeanShift,基于Sift特征,基于EKF,基于SVM,基于模板匹配等。手势识别,受尺度,角度,光照,同一手势每次演示的差异。目前基于2D视觉的静态手势识别技术主要有三大类,第一类为模板匹配技术,这是一种最简单的识别技术;第二类为统计分析技术,这是一种通过统计样本特征向量来确定分类器的基于概率统计理论的分类方法;第三类为神经网络技术,这种技术具有自组织和自学习能力,具有分布性特点,能有效的抗噪声和处理不完整模式以及具有模式推广能力。基于2D视觉的动态手势识别技术,主要有基于神经网络,基于HMMs,CRFs等。
3.基于神经网络2D摄像头静态手势识别实现
本文主要实现基于2D摄像头的静态手势识别系统,由于是静态所以不用考虑手势追踪,重点关注手势分割、手势识别两部分。其中手势分割采用局部自适应阈值的图像二值化和高斯肤色模型算法提取手掌轮廓;手势识别采用CNN网络进行分类。
3.1 手势分割算法实现
局部自适应阈值的图像二值化
def binaryMask(self, frame, x0, y0, width, height):
# print('use binaryMask model ...')
minValue = 70
# 创建矩形框
cv2.rectangle(frame, (x0, y0), (x0 + width, y0 + height), (0, 255, 0), 1)
roi = frame[y0:y0 + height, x0:x0 + width]
# 获取灰度图像
gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
# 高斯模糊:高斯滤波器中像素的权重与其距中心像素的距离成比例
blur = cv2.GaussianBlur(gray, (5, 5), 2)
# 图像的二值化提取目标,动态自适应的调整属于自己像素点的阈值,而不是整幅图像都用一个阈值
th3 = cv2.adaptiveThreshold(blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 2)
ret, res = cv2.threshold(th3, minValue, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
return res高斯肤色模型
def skinMask(self, frame, x0, y0, width, height):
print('use skin model ...')
# HSV values
low_range = np.array([0, 50, 80])
upper_range = np.array([30, 200, 255])
cv2.rectangle(frame, (x0, y0), (x0 + width, y0 + height), (0, 255, 0), 1)
roi = frame[y0:y0 + height, x0:x0 + width]
hsv = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
# 设阈值,去除背景部分,低于这个lower_red的值,图像值变为0,高于这个upper_red的值,图像值变为0
mask = cv2.inRange(hsv, low_range, upper_range)
#腐蚀操作,减少整幅图像的白色区域
mask = cv2.erode(mask, skinkernel, iterations=1)
#膨胀操作,增加图像中的白色区域
mask = cv2.dilate(mask, skinkernel, iterations=1)
# 用高斯分布权值矩阵与原始图像矩阵做卷积运算
mask = cv2.GaussianBlur(mask, (15, 15), 1)
# cv2.imshow("Blur", mask)
# 图像与运算
res = cv2.bitwise_and(roi, roi, mask=mask)
# color to grayscale
res = cv2.cvtColor(res, cv2.COLOR_BGR2GRAY)
return res3.2 手势识别CNN神经网络实现
将上面图像分割出来的手势图像进行CNN训练,得到比较稳定的网络,然后输入新的图像进行分类输出即可。基于keras的CNN网络模型搭建如训练流程如下:
网络搭建实现
def createCNNModel(self):
self.model = Sequential()
self.model.add(Conv2D(nb_filters, (nb_conv, nb_conv),
padding='valid',
# input_shape=( img_rows, img_cols,img_channels)))
input_shape=(img_channels, img_rows, img_cols))) # theano
convout1 = Activation('relu')
self.model.add(convout1)
self.model.add(Conv2D(nb_filters, (nb_conv, nb_conv)))
convout2 = Activation('relu')
self.model.add(convout2)
self.model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
self.model.add(Dropout(0.5))
self.model.add(Flatten())
self.model.add(Dense(128))
self.model.add(Activation('relu'))
self.model.add(Dropout(0.5))
#11个手势输出,1,2,3,4,5,6,7,8,9,10
self.model.add(Dense(nb_classes))
self.model.add(Activation('softmax'))
# sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
self.model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
# Model summary
self.model.summary()
# Model conig details
self.model.get_config()
from keras.utils import plot_model
plot_model(self.model, to_file='my_model.png', show_shapes=True)
return self.model训练流程实现
def trainModel(self, train_set_path, weight_name):
self.model = self.createCNNModel()
imlist = []
self.getImgListPath(train_set_path, imlist)
image1 = np.array(Image.open(imlist[0]))
m, n = image1.shape[0:2]
total_images = len(imlist)
img_ndarry_list = []
label_list = np.ones((total_images,), dtype=int)
for index, img_file in enumerate(imlist):
single_img_label =label_dict[os.path.basename(img_file).split('_')[0]]
single_img_array = np.array(Image.open(img_file).convert('L')).flatten()
img_ndarry_list.insert(index, single_img_array)
label_list[index] = single_img_label
img_matrix = np.array(img_ndarry_list, dtype='f')
data, label = shuffle(img_matrix, label_list, random_state=2)
train_data = [data, label]
(X, y) = (train_data[0], train_data[1])
# Split X and y into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=4)
X_train = X_train.reshape(X_train.shape[0], img_channels, img_rows, img_cols)
X_test = X_test.reshape(X_test.shape[0], img_channels, img_rows, img_cols)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# normalize
X_train /= 255
X_test /= 255
# convert integers to dummy variables (one hot encoding)
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
# print ( X_train, X_test, Y_train, Y_test)
# print (img_matrix)
hist = self.model.fit(X_train, Y_train, batch_size=batch_size, epochs=nb_epoch,
verbose=1, validation_split=0.2)
# 保存模型的权重
self.model.save(weight_name)
print('train model success!')4.效果展示
为了方便演示,添加了pyqt4的UI界面,能够方便实现性能和测试和调优,整体效果入下:
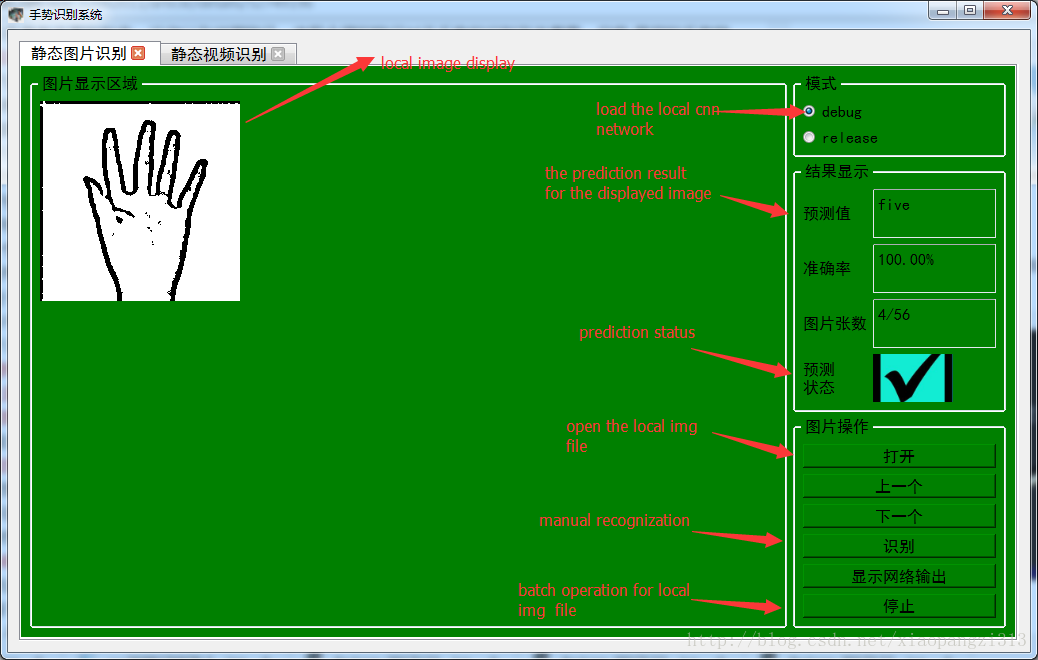
上面这个部分可以用来测试本地数据集的识别率,以下这个部分实现对视频手势的实时识别,效果如下:
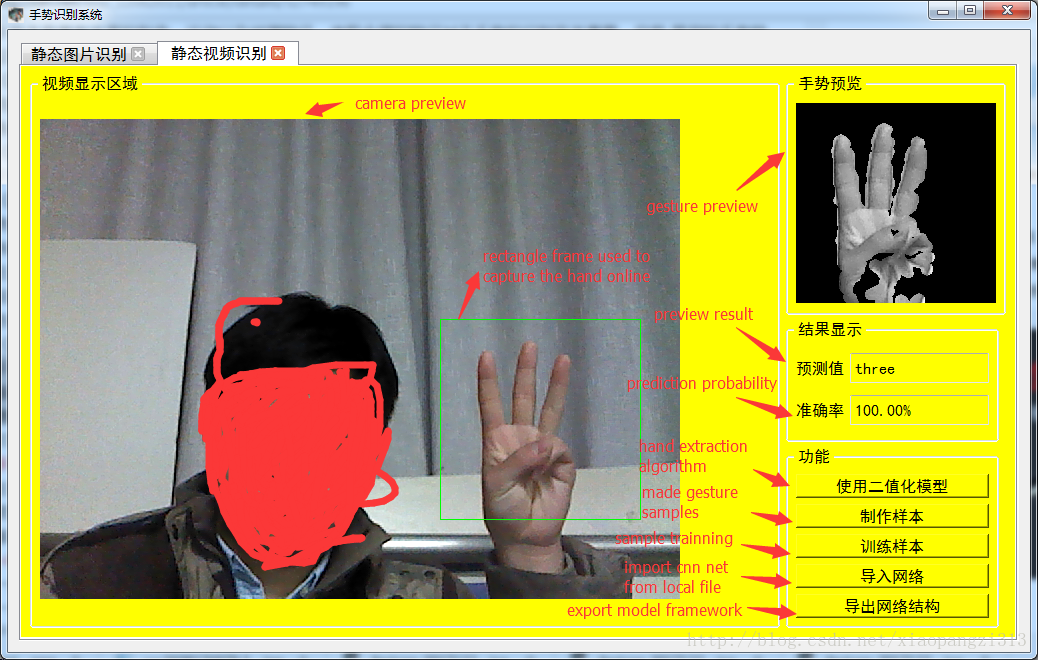
这个UI界面可以实现本地数据集的录制,手掌分割方法选择,样本的训练,还有直接导入训练好的本地网络等功能。
1.代码路径的链接
2.本地训练好的网络链接
参考文献:
1.Gesture recognition via CNN neural network implemented in Keras + Tensorflow + OpenCV