背景:
原来Trie树我学得是这么烂。
: 树
字典树:单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
——摘自《百度百科》
这都不重要了。
具体来说,你是这么存储:
实际来说,你只需要将每一条边的权值存在儿子节点上即可。
这样做,你的空间和时间复杂度都降低了。
代码还是很好实现的。
代码:
: 树的经典应用
:
求
个字符串的第
小字符串。
这不是后缀数组模板吗?
显然后缀数组可以完美解决,但是是否存在代码更好的实现方式。
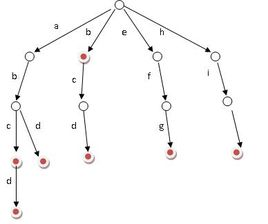
仔细看看上面的图,从上至下,从左至右来看你发现如果一个点有
标记(某个字符串的末尾),那么字符串的就是升序的。
当然,如果有多组询问你就要离线来搞了(
升序什么的)。
代码:
:
求
个字符串,求某两个字符串的最长公共前缀。
找到两个字符串的
位置,在
一下不就可以了吗。
代码:
:
最大异或和