一、Lenet5
Lenet5由七层网络组成,三个卷积层和两个下采样层以及两个全连接层所组成,各个层的结构分别如下:

conv1:输入32x32大小的图片,六个5x5大小的卷积核,填充为0,步长为1,最后输出28*28*6大小的图片。
pool1:6个2x2大小的卷积核最后输出大小为14*14*6的图片。
conv2:16个5x5大小的卷积核,填充为0,步长为1,最后输出大小为10x10x16。
pool2:16个2x2大小的卷积核做最大池化,得到5x5x16的大小。
conv3:120个大小为5x5的卷积核,填充为0,步长为5,输出大小为120。
fc1:输入120,输出84。
fc2:输入84,输出10。
pytorch版本的网络具体实现如下:
class LeNet_5(nn.Module):
def __init__(self):
super(LeNet_5,self).__init__()
self.conv1 = nn.Conv2d(3,6,5)
self.pool1 = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(6,16,5)
self.pool2 = nn.MaxPool2d(2,2)
self.conv3 = nn.Conv2d(16,120,5)
self.fc1 = nn.Linear(120,84)
self.fc2 = nn.Linear(84,10)
def forward(self,x):
x = F.relu(self.conv1(x))
x = F.relu(self.pool1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.pool2(x))
x = F.relu(self.conv3(x))
x = x.reshape([-1,120])
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return x二、AlexNet
AlexNet网络有八层组成,分别有5个卷积层和3个全连接层,网络结构如下:

conv1:由两个GPU分别进行,一共是96个大小为11x11大小的卷积核,填充为0,步长为4,使用3x3大小的池化窗口,步长为2,输出大小为27x27x96。
conv2:用256大小的卷积核,步长为1,分在两块GPU上进行训练,池化窗口为3x3,步长为2,输出大小为13x13x256。
conv3:这一层不加池化层,用384个3x3大小的卷积核,填充为0,步长为1,最后输出大小为13x13x384。
conv4:这一层也不加池化层,结构与conv3相同。
conv5:采用256个3x3大小的卷积核,填充为0,步长为1,池化窗口为3x3,步长为2,最后输出大小为6x6x256。
fc1:输入6x6x256,输出4096个神经元,并使用dropout。
fc2:与fc1结构相同。
fc3:使用softmax得到1000个类别数。
总的来说,第三、四个卷积层不使用池化,池化窗口都是3x3,步长都是2。只有第一层的卷积步长是4,其它都为1,而且都没有填充。除了最后一个全连接层使用softmax以外,其余层的激活函数都使用relu,卷积核大小分别为11,5,3,3,5。
最后再附上一张各个层的祥图:

下面给出pytorch版本的代码:
class AlexNet(nn.Module):
def __init__(self, classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x三、ZF-Net
ZF-Net在AlexNet的基础之上,将第一层的卷积核从11x11变成了7x7的大小,步长从4变成了2,将两块GPU变成了在一块GPU上训练。
四、VGG
VGG用的比较多的是16层和19层,其中19层性能最好,16层用得最多,它由13个卷积层核3个全连接层所组成。VGG整个网络都使用的是3x3的卷积核,它使用多个3x3的卷积核来代替7x7和5x5的卷积核,这种操作的目的是在达到同样效果的情况下降低参数量,比如一个5x5的卷积所需要的参数为5x5=25,而2个3x3的卷积核所需要的参数为2x3x3=18个。池化窗口都是2x2的。
VGG-16pytorch代码实现:
class VGG_16(nn.Module):
def __init__(self):
super(VGG_16, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3,64,3,stride=1,padding=1),
nn.Conv2d(64,64,3,stride=1,padding=1),
nn.MaxPool2d(2,2),
nn.ReLU(True),
nn.Conv2d(64,128,3,stride=1,padding=1),
nn.Conv2d(128,128,3,stride=1,padding=1),
nn.MaxPool2d(2,2),
nn.ReLU(True),
nn.Conv2d(128,256,3,stride=1,padding=1),
nn.Conv2d(256,256,3,stride=1,padding=1),
nn.Conv2d(256, 256, 3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.ReLU(True),
nn.Conv2d(256, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.ReLU(True),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.ReLU(True)
)
self.fc = nn.Sequential(
nn.Dropout(),
nn.Linear(7*7*512,4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096,1000),
nn.Softmax()
)VGG-19的pytorch代码:
class VGG_19(nn.Module):
def __init__(self):
super(VGG_19, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3,64,3,stride=1,padding=1),
nn.Conv2d(64,64,3,stride=1,padding=1),
nn.MaxPool2d(2,2),
nn.ReLU(True),
nn.Conv2d(64,128,3,stride=1,padding=1),
nn.Conv2d(128,128,3,stride=1,padding=1),
nn.MaxPool2d(2,2),
nn.ReLU(True),
nn.Conv2d(128,256,3,stride=1,padding=1),
nn.Conv2d(256,256,3,stride=1,padding=1),
nn.Conv2d(256, 256, 3, stride=1, padding=1),
nn.Conv2d(256, 256, 3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.ReLU(True),
nn.Conv2d(256, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.ReLU(True),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.Conv2d(512, 512, 3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.ReLU(True)
)
self.fc = nn.Sequential(
nn.Dropout(),
nn.Linear(7*7*512,4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096,1000),
nn.Softmax()
)五、GoogLeNet
它的主要特点是采用跟深跟宽的网络结构,一共是22层,并且相对于VGG而言参数量跟少。它主要是由9个Inception模块组成,并且每个卷积都采用relu去激活包括用于降维的1x1卷积,使用1x1卷积的目的就是为了降低在多个卷积核同时卷积后和起来的太高的维度,除了最后一个平均池化没有使用1x1卷积以外其余每个池化以后都要使用1x1的卷积,而且对于池化层而言要得到最终分类的时候使用的都是平均池化,其它的都是最大池化。网络结构如下:

1、输入卷积层


对于一张输入尺寸为224x224大小的图片首先采用7x7的卷积核,步长为2,填充为2,输出通道为64,得到112x112x64大小的输出,然后用3x3步长为2的池化窗口的最大池化得到56x56x64 ,最后对于输出采用局部归一化LRN(因为在生物学上活跃的神经元具有抑制相邻神经元的机制,这种机制叫做侧抑制,为了避免这种现象,所以使用LRN,它可以对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其它反馈较小的神经元,以此来增强模型的泛化能力。)。
然后分别采用1x1步长为1的卷积和3x3步长和填充都为1的卷积核得到56x56x192的大小。
2、inception3a模块

a模块的特点是输入的必须是经过最大池化以后的。

通过最大池化得到28x28x192的输出,然后分为4路,一路是直接经过1x1的卷积然后去合并,还有两路是经过1x1卷积以后分别经过3x3和5x5的卷积以后再合并,还有一路是经过3x3步长为1的最大池化后经过1x1卷积然后合并,最终的输出就是64+128+32+32=256 。
3、inception3b模块

b、c、d、e模块的特点是输入不需要经过最大池化,直接将上一层合并后的拿来分为四路。

4、inception4a模块


5、inception4b模块
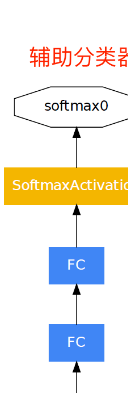


这一个模块的特别之处就在于对于上一层合并的输出分为了五路,新增了一个辅助分类器,首先对于上一层的输出采用5x5步长为3的平均池化,然后用1x1的卷积将维度降到4x4x128,然后经过两个1024Dropout为0.7的全连接层最后使用Softmax得到1000个类别。
6、inception4c模块


7、inception4d模块


8、inception4e模块



9、inception5a模块


10、inception5b模块


11、最终输出层
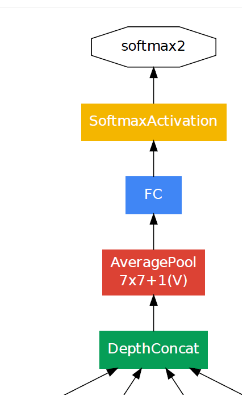

最终对于上一层的输出通过7x7步长为1的平均池化得到7x7x1024的大小,然后经过Dropout为0.4的全连接层,采用relu激活函数最后使用softmax得到1000个类别。
对于inception模块还有许多改进版本,其中inceptionv2的基本结构如下:

它主要是仿照VGG将5x5的卷积改为了两个3x3卷积,然后在输入的时候加入了BN层,用以加快收敛,并且减少了dropout的使用。
inceptionv3:

inceptionv3主要是将一个nxn卷积用1xn和nx1的卷积来代替,即将一个较大的二维卷积拆分为两个较小的一维卷积,它的好处是降低参数,减轻了过拟合并且增加了一层非线性扩展模型的表达能力。
pytorch实现的v1代码如下:
import numpy as np
import torch
from torch import nn
from torch.autograd import Variable
from torch import optim
import torchvision
from torchvision import transforms
from datetime import datetime
#自己定义一个transform,效果和torchvision.transforms等价用于对图片进行变换
def transform(x):
x = x.resize((224,224),2)#将图片放大到224*224
#对图像进行预处理和标准化
x = np.array(x,dtype=np.float32)/255
x = (x-0.5)/0.5
x = x.transpose((2,0,1))#将图片的维度转换为pytorch的输入方式
x = torch.from_numpy(x)#将图片转换为torch.Tensor的数据
return x
#加载数据集
trainsets = torchvision.datasets.CIFAR10(root='data',train=True,transform=transform,download=False)
trainloaders = torch.utils.data.DataLoader(trainsets,batch_size=64,shuffle=True)
testsets = torchvision.datasets.CIFAR10(root='data',train=False,download=False,transform=transform)
testloaders = torch.utils.data.DataLoader(testsets,batch_size=128,shuffle=False)
#定义一个包含卷积层和BN层以及relu激活的层结构提高代码复用率
def Conv_2D(in_channels,out_channels,k,s=1,p=0):
return nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=k,stride=s,padding=p),
nn.BatchNorm2d(out_channels,eps=1e-3),#ϵ设置为0.001
nn.ReLU(True)
)
"""
功能:
inceptionv1的一个基本模块
参数:
out1_1:第一条线路的1x1卷积的输出通道
out2_1:第二条线路的1x1卷积的输出通道
out2_3:第二条线路的3x3卷积的输出通道
out3_1:第三条线路的1x1卷积的输出通道
out3_5:第三条线路的5x5卷积的输出通道
out4_1:第四条线路的1x1卷积的输出通道
返回值:
将各条线路的输出连接之后作为返回
"""
class Inception_v1(nn.Module):
def __init__(self,in_channels,out1_1,out2_1,out2_3,out3_1,out3_5,out4_1):
super(Inception_v1, self).__init__()
self.branch1 = Conv_2D(in_channels,out1_1,1)
self.branch2 = nn.Sequential(
Conv_2D(in_channels,out2_1,1,),
Conv_2D(out2_1,out2_3,3,p=1)
)
self.branch3 = nn.Sequential(
Conv_2D(in_channels,out3_1,1),
Conv_2D(out3_1,out3_5,5,p=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(3,stride=1),
Conv_2D(in_channels,out4_1,1,p=1)
)
def forward(self,x):
f1 = self.branch1(x)
f2 = self.branch2(x)
f3 = self.branch3(x)
f4 = self.branch4(x)
output = torch.cat((f1,f2,f3,f4),dim=1)
return output
class GoogleNet(nn.Module):
def __init__(self):
super(GoogleNet, self).__init__()
self.layers = nn.Sequential(
Conv_2D(3,64,7,p=2,s=2),
nn.MaxPool2d(3,stride=2),
Conv_2D(64,64,1),
Conv_2D(64,192,3,p=1),
nn.MaxPool2d(3,2)
)
self.inception_3a = Inception_v1(192,64,96,128,16,32,32)
self.inception_3b = Inception_v1(256,128,128,192,32,96,64)
self.inception_4a = Inception_v1(480,192,96,208,16,48,64)
self.inception_4b = Inception_v1(512,160,112,224,24,64,64)
self.inception_4c = Inception_v1(512,128,128,256,24,64,64)
self.inception_4d = Inception_v1(512,112,144,288,32,64,64)
self.inception_4e = Inception_v1(528,256,160,320,32,128,128)
self.inception_5a = Inception_v1(832,256,160,320,32,128,128)
self.inception_5b = Inception_v1(832,384,192,384,48,128,128)
self.fc = nn.Sequential(
nn.AvgPool2d(7,1),
nn.Linear(1024,1024),
nn.ReLU(True),
nn.Dropout(0.4),
nn.Linear(1024,1000),
nn.Softmax()
)
def forward(self,x):
x = self.layers(x)
x = self.inception_3a(x)
x = self.inception_3b(x)
x = self.inception_4a(x)
x = self.inception_4b(x)
x = self.inception_4c(x)
x = self.inception_4d(x)
x = self.inception_4e(x)
x = self.inception_5a(x)
x = self.inception_5b(x)
return self.fc(x)
def acc(output,lable):
#拿到总共多少张图片(批次)
total = output.shape[0]
#取出输出one-hot向量中输出最大概率值的索引作为类别
_,predict = output.max(1)
corect = (predict==lable).sum().item()
return corect/total
if __name__ == '__main__':
net = GoogleNet()
optimizer = optim.Adam(net.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
if torch.cuda.is_available():
net = net.cuda()
#记录当前时间
prev_time = datetime.now()
#开始训练
for epoch in range(20):
print('开始训练')
train_loss = 0
train_acc = 0
# net = net.train()
for img,lable in trainloaders:
print('加载数据')
if torch.cuda.is_available():
img = Variable(img.cuda())
lable = Variable(lable.cuda())
else:
img = Variable(img)
lable = Variable(lable)
print('输出前')
print(type(img))
output = net(img)
print('输出后')
loss = criterion(output,lable)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.data.item()
Acc = acc(output,lable)
print(Acc)
train_acc += Acc
curent_time = datetime.now()
#将时间进行转化
h, remainder = divmod((curent_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
time_str = "Time %02d:%02d:%02d" % (h, m, s)
test_loss = 0
test_acc = 0
net = net.eval()
for img,lable in testloaders:
if torch.cuda.is_available():
img = Variable(img.cuda(),volatile=True)
lable = Variable(lable.cuda(),volatile=True)
else:
img = Variable(img,volatile=True)
lable = Variable(lable,volatile=True)
output = net(img)
loss = criterion(output,lable)
test_loss += loss
test_acc += acc(output,lable)
print('第{}次训练,训练误差为:{},训练准确率:{},测试误差:{},测试准确率:{},训练耗时:'.format(epoch+1,train_loss,train_acc,test_loss,test_acc)+time_str)六、ResNet
由于网络的加深会导致梯度消失或梯度暴涨的问题,为了解决这个问题Resnet引入了残差块:
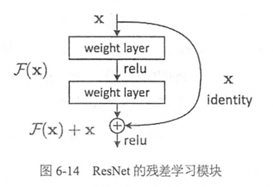
网络主要由这些残差模块堆叠而成:

对于输入的数据先用7x7的卷积和2x2的最大池化,然后分别输入6个模块的64个输出通道的模块和8个、12个、6个其它通道的模块组成。
它每一个的输出H(x)=F(x)+x,那为什么这样比较好呢?举个例子来说:
例如H(x)=5.1,H(x')=5.2,这时候输出增加了0.1/5.1=2%,而H(x)=5+0.1=F(x)+x,x=5,F(x)=0.1,当H(x)=5.2时,F(x)=0.2,输出增加了0.1/0.1=100%,也就是说输出的变化对权重的调整作用更大。
常用的层数有18/34/50/101/152层
有关网络的设计参看:https://blog.csdn.net/fortilz/article/details/80851251
ResNet的tensorflow实现:
MNIST_train.pyimport tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import ResNet_infernece
import DATA_set
import os
import numpy as np
#定义损失函数、学习率、滑动平均操作#基础范围,本文不加以阐释
def train_op_data(mnist,lables,output,moving_average_decay,learning_rate_base,batch_size,learning_rate_daecay,global_step):
#采用滑动平均的方法更新参数
variable_averages =tf.train.ExponentialMovingAverage(moving_average_decay,global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=output,labels=tf.argmax(lables, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
#随着训练的进行逐步降低学习率。该函数需要`global_step`值来计算衰减的学习速率。该函数返回衰减后的学习率。
learning_rate = tf.train.exponential_decay( learning_rate_base,global_step,mnist.train.num_examples / batch_size,learning_rate_daecay, staircase=True)
#设置自适应学习率
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):#指定某些操作执行的依赖关系,让在这个上下文环境中的操作都在 control_inputs 执行
#下面的操作依赖于[train_step, variables_averages_op]操作
train_op = tf.no_op(name='train')
return train_op , loss
def train(mnist):
# 定义数据入口和标注
input = tf.placeholder(tf.float32,[ DATA_set.BATCH_SIZE, DATA_set.IMAGE_SIZE,DATA_set.IMAGE_SIZE, DATA_set.IMAGE_COLOR_DEPH],name='input')
y_ = tf.placeholder(tf.float32,[None, DATA_set.NUM_LABELS],name='y-input')
#L2正则
regularizer = tf.contrib.layers.l2_regularizer(DATA_set.REGULARIZATION_RATE)
#获取结果
y = ResNet_infernece.inference(input, False, regularizer)
#全局行为
global_step = tf.Variable(0, trainable=False)
#进行模型优化
train_op , loss = train_op_data(mnist,y_,y,DATA_set.MOVING_AVERAGE_DECAY,DATA_set.LEARNING_RATE_BASE,DATA_set.BATCH_SIZE,DATA_set.LEARNING_RATE_DECAY,global_step)
# 初始化TensorFlow持久化类,并对模型进行训练
saver = tf.train.Saver()
write = tf.summary.FileWriter(DATA_set.LOG_PATH,tf.get_default_graph())
write.close()
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(DATA_set.TRAINING_STEPS):
xs, ys = mnist.train.next_batch(DATA_set.BATCH_SIZE)
reshaped_xs = np.reshape(xs, ( DATA_set. BATCH_SIZE,DATA_set.IMAGE_SIZE,DATA_set.IMAGE_SIZE,DATA_set.IMAGE_COLOR_DEPH))
_, loss_value, step = sess.run([train_op, loss, global_step],feed_dict={input: reshaped_xs, y_: ys})
print("After %d training step(s), loss on training batch is %g."% (step, loss_value))
if i % 100 == 0:saver.save(sess, os.path.join(DATA_set.MODEL_SAVE_PATH,DATA_set.MODEL_NAME),global_step=global_step)
def main(argv=None):
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run(main)#将自己写的main函数作为程序的入口ResNet_infernece.pyimport tensorflow as tf
import tensorflow.contrib.slim as slim
import DATA_set
#双层残差模块
def res_layer2d(input_tensor,kshape = [5,5],deph = 64,conv_stride = 1,padding='SAME'):
data = input_tensor
#模块内部第一层卷积
data = slim.conv2d(data,num_outputs=deph,kernel_size=kshape,stride=conv_stride,padding=padding)
#模块内部第二层卷积
data = slim.conv2d(data,num_outputs=deph,kernel_size=kshape,stride=conv_stride,padding=padding,activation_fn=None)
#对输入和输出数据进行相加
#在相加之前先将维度变得一致
#获得输入数据的通道数
output_deep = input_tensor.get_shape().as_list()[3]
#当输出深度和输入深度不相同时,进行对输入深度的全零填充
if output_deep != deph:
input_tensor = tf.pad(input_tensor,[[0, 0], [0, 0], [0, 0],[abs(deph-output_deep)//2,abs(deph-output_deep)//2] ])
data = tf.add(data,input_tensor)
data = tf.nn.relu(data)
return data
#模型在增加深度的同时,为了减少计算量进行的xy轴降维(下采样),#这里用卷积1*1,步长为2。当然也可以用max_pool进行下采样,效果是一样的
def get_half(input_tensor,deph):
data = input_tensor
data = slim.conv2d(data,deph//2,1,stride = 2)
return data
#组合同类残差模块
def res_block(input_tensor,kshape,deph,layer = 0,half = False,name = None):
data = input_tensor
with tf.variable_scope(name):
if half:data = get_half(data,deph//2)
for i in range(layer//2):
data = res_layer2d(input_tensor = data,deph = deph,kshape = kshape)
return data
#定义模型传递流程
def inference(input_tensor, train = False, regularizer = None):
with slim.arg_scope([slim.conv2d,slim.max_pool2d],stride = 1,padding = 'SAME'):#为slim.conv2d,slim.max_pool2d两个函数设置默认参数
with tf.variable_scope("layer1-initconv"):
data = slim.conv2d(input_tensor,DATA_set.CONV_DEEP , [7, 7])
data = slim.max_pool2d(data,[2,2],stride=2)
with tf.variable_scope("resnet_layer"):
data = res_block(input_tensor = data,kshape = [DATA_set.CONV_SIZE,DATA_set.CONV_SIZE],deph = DATA_set.CONV_DEEP,layer = 6,half = False,name = "layer4-9-conv")
data = res_block(input_tensor = data,kshape = [DATA_set.CONV_SIZE,DATA_set.CONV_SIZE],deph = DATA_set.CONV_DEEP * 2,layer = 8,half = True,name = "layer10-15-conv")
data = res_block(input_tensor = data,kshape = [DATA_set.CONV_SIZE,DATA_set.CONV_SIZE],deph = DATA_set.CONV_DEEP * 4,layer = 12,half = True,name = "layer16-27-conv")
data = res_block(input_tensor = data,kshape = [DATA_set.CONV_SIZE,DATA_set.CONV_SIZE],deph = DATA_set.CONV_DEEP * 8,layer = 6,half = True,name = "layer28-33-conv")
data = slim.avg_pool2d(data,[2,2],stride=2)
#得到输出信息的维度,用于全连接层的输入
data_shape = data.get_shape().as_list()
nodes = data_shape[1] * data_shape[2] * data_shape[3]
reshaped = tf.reshape(data, [data_shape[0], nodes])
#最后全连接层
with tf.variable_scope('layer34-fc'):
fc_weights = tf.get_variable("weight", [nodes, DATA_set.NUM_LABELS],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses', regularizer(fc_weights))
fc_biases = tf.get_variable("bias", [DATA_set.NUM_LABELS],initializer=tf.constant_initializer(0.1))
fc = tf.nn.relu(tf.matmul(reshaped, fc_weights) + fc_biases)
if train:
fc = tf.nn.dropout(fc, 0.5)
return fcDATA_set.pyNUM_LABELS = 10 #对比标签数量(模型输出通道)
# #卷积参数
CONV_SIZE = 3
CONV_DEEP = 64
#学习优化参数
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.03
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 8000
MOVING_AVERAGE_DECAY = 0.99
#图片信息
IMAGE_SIZE = 28
IMAGE_COLOR_DEPH = 1
#模型保存位置
MODEL_SAVE_PATH="MNIST_model/"
MODEL_NAME="mnist_model"
#日志路径
LOG_PATH = "log"pytorch版本:
resnet.pyimport torch
import torch.nn as nn
import torch.nn.functional as F
class ResidualBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
def forward(self, x):
out = self.left(x)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, ResidualBlock, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2)
self.fc = nn.Linear(512, num_classes)
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) #strides=[1,1]
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def ResNet18():
return ResNet(ResidualBlock)main.pyimport torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
from resnet import ResNet18
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 参数设置,使得我们能够手动输入命令行参数,就是让风格变得和Linux命令行差不多
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints') #输出结果保存路径
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)") #恢复训练时的模型路径
args = parser.parse_args()
# 超参数设置
EPOCH = 135 #遍历数据集次数
pre_epoch = 0 # 定义已经遍历数据集的次数
BATCH_SIZE = 128 #批处理尺寸(batch_size)
LR = 0.1 #学习率
# 准备数据集并预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), #先四周填充0,在吧图像随机裁剪成32*32
transforms.RandomHorizontalFlip(), #图像一半的概率翻转,一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), #R,G,B每层的归一化用到的均值和方差
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=False, transform=transform_train) #训练数据集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2) #生成一个个batch进行批训练,组成batch的时候顺序打乱取
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# Cifar-10的标签
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss() #损失函数为交叉熵,多用于多分类问题
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4) #优化方式为mini-batch momentum-SGD,并采用L2正则化(权重衰减)
# 训练
if __name__ == "__main__":
best_acc = 85 #2 初始化best test accuracy
print("Start Training, Resnet-18!") # 定义遍历数据集的次数
with open("acc.txt", "w") as f:
with open("log.txt", "w")as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
# 准备数据
length = len(trainloader)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每训练1个batch打印一次loss和准确率
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
# 每训练完一个epoch测试一下准确率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
# 取得分最高的那个类 (outputs.data的索引号)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('测试分类准确率为:%.3f%%' % (100 * correct / total))
acc = 100. * correct / total
# 将每次测试结果实时写入acc.txt文件中
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
# 记录最佳测试分类准确率并写入best_acc.txt文件中
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)