1. 受限玻尔兹曼机RBM
首先我们要了解一下什么是受限玻尔兹曼机(RBM,Restricted Boltzmann machine)。玻尔兹曼机是一大类的神经网络模型,但是在实际应用中使用最多的则是受限玻尔兹曼机(RBM)。
受限玻尔兹曼机是由多伦多大学的Hinton等人提出的一个随机神经网络,它是一种可以用于降维、分类、回归、协同过滤、特征学习以及主题建模的算法。
它包含一层可视层和一层隐藏层。在同一层的神经元之间是相互独立的,而在不同的网络层之间的神经元是相互连接的(双向连接)。也就是说,不存在层内通信,这就是 RBM 中的限制所在。
在网络进行训练以及使用时信息会在两个方向上流动,而且两个方向上的权值是相同的。但是偏置值是不同的(偏置值的个数是和神经元的个数相同的)。
RBM中的隐单元和可见单元可以为任意的指数族单元,如softmax单元、高斯单元、泊松单元等等。这里,为了讨论方便起见,我们假设所有的可见单元和隐单元均为二值变量。于是受限玻尔兹曼机的结构如下:
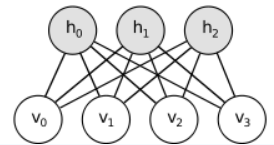
如上图所示:下面的四个圆圈叫做可视层,上面三个叫做隐藏层。可视层其实说白了就是输入层,将原始数据给输入进去就行。隐含层是啥意思,就是说我通过一个公式,把可视层的数据给算成隐含数据。
所以它是怎么计算的呢?首先介绍一个概念叫做权值,权值就是值每个小圆圈之间的连线的加权数。比如下面有4个圈圈,上面有3个圈圈,那么一共就有12个权值,我们用Wij表示,i指下面圆圈的编号,j是上面的。另一个概念叫做偏置量,怎么理解呢,一次函数写作y=kx+b,权值Wij就是k,那么偏置量就是b。
接着说怎么计算,那可多了,神马tansig,sigmoid,pureline等等。我们先不管这些,举个最简单的栗子便于理解,计算方式很简单,用可视层x1~x4四个数据与权值相乘,然后加和,之后再把偏置量b1加上,就完事儿了。其公式可以写作:y1=x1 * w11 + x2 * w21 + x3 * w31 + x4 * w41 + b1。按照这个方法,即可把3个隐藏层圆圈的值都算出来。
算完之后,我们通过算出来的y1,y2,y3在回求一遍x1 ~ x4,回求的值我们叫做x’1 ~ x’4。公式写作x1 = y1 * w11 + y2 * w12 + y3 * w13 + a1。然后,通过x’1 ~ x’4再对隐含层再次求一遍值,得到y’1 ~ y’3的值。
因为 RBM 的权重是随机初始化的,所以,重建结果和原始输入的差距通常会比较大。你可以将x’1 ~ x’4和x1 ~ x4之间的差值看做重建误差,然后这个误差会沿着 RBM 的权重反向传播,以一个迭代学习的过程不断反向传播,直到达到某个误差最小值。所以它就在一直循环,直到最后近乎相等为止,这样一个RBM模型就建立好了。
2. 深度信念网络DBN
深度信念网络,它的英文名叫作Deep Belief Network。
应用:物体识别,语音识别。
组成:多层无监督的受限玻尔兹曼机(RBM)网络和一层有监督的反向传播(BP)网络组成。
训练:预训练(pre-training)+微调(fine-tuning)
预训练:采用逐层(layerwise)训练;低一层的作为上一层的输入。
微调:有监督;对最后一层的·BP网络进行训练;结果比较产生的误差逐层向后传播,对整体权值进行微调。
预训练过程可看做BP网络权值的初始化,这里代替了之前BP网络权值随机初始化,进而避免了训练时间过长以及陷入局部极小值得问题。
它具体是个是东西呢?通俗的来讲,就是把RBM堆叠在一块,然后形成一大串连接的RBM,最后在顶端加入一个输出层,就完了。
有人说只有一个隐藏层的 DBN 就是一个 RBM。

这个图是怎么运行的呢,我来说一下,很简单,就是把原始数据输入到最下面的RBM可视层中,然后训练RBM1,训练完成之后把RBM1的隐含层作为RBM2的可视层,继续训练RBM2,接下来把RBM2的隐含层做为RBM3的可视层,直到训练完成为止。
RBM的最后一隐含层层与输出层连接,计算方法就是OUT1=f(IN1w11+IN2w21+IN3w31+IN4w41+b1)。然后干啥,做反向传播,传播的方法很简单,首先是通过一个目标函数,一般为均方差函数,算出一个值E,然后用这个E乘以该层计算输出层时候公式的导数,比如是更新权值w11,那么就计算该层第一个神经元的计算方法,若计算方法是OUT1=f(IN1w11+IN2w21+IN3w31+IN4w41+b1),那么导数就是IN1*f’(x)。求完这个导数之后乘上E1,再把这个导数乘上一个系数alpha,叫做学习速率,然后再把得到的值加到w11中。同理把所有的wij都算完,算完之后计算偏置量b1的导数,这个导数就是f’(x),完事儿乘上学习速率加到b1上面,同理把bj都给算完。我们算完之后,得到了w和b,但还有一个隐藏的东西,就是导数乘以学习速率我们叫做梯度下降值,写作▽w,▽b,这个东西我们作为跟上一层的E一样的东西,然后依次的往下算,直到最后一层的权值w和偏置量b全都更新完成为止。更新完之后,我们就要重新正向的算一遍,然后求E,然后再反向传播,直到E变得很小很小为止。于是模型就算建立好了。
- 一个Matlab实例
用数字识别训练一个手写数字识别的深度神经网络。
网络结构采用 784,400,200,100,50,20,10的网络结构。
function aGetDeepNet()
clc
clear all
%得到训练数据
load('adata.mat','train_digitdata','train_targets');
X = train_digitdata;
Y = train_targets;
%输入数据初始化
Xmin = min(X);
Xmax = max(X);
X = bsxfun(@rdivide,bsxfun(@minus,X,Xmin),(Xmax-Xmin));
%RBM训练得到第一隐层的网络参数,rbm输入为图片数据
rbm1 = rbm([784,400]);
rbm1 = checkrbmtrain(@rbmtrain1,rbm1,X,50,0.1);
net_rbm1 = rbm2nnet(rbm1,'up');
h1 = nnetfw(net_rbm1,X);
%RBM训练得到第二隐层的网络参数,输入为第一隐层的输出
rbm2 = rbm([400,200]);
rbm2 = checkrbmtrain(@rbmtrain1,rbm2,h1,50,0.1);
net_rbm2 = rbm2nnet(rbm2,'up');
h2 = nnetfw(net_rbm2,h1);
%RBM训练得到第三隐层的网络参数,输入为第二隐层的输出
rbm3 = rbm([200,100]);
rbm3 = checkrbmtrain(@rbmtrain1,rbm3,h2,50,0.1);
net_rbm3 = rbm2nnet(rbm3,'up');
h3 = nnetfw(net_rbm3,h2);
%RBM训练得到第四隐层的网络参数,输入为第三隐层的输出
rbm4 = rbm([100,50]);
rbm4 = checkrbmtrain(@rbmtrain1,rbm4,h3,50,0.1);
net_rbm4 = rbm2nnet(rbm4,'up');
h4 = nnetfw(net_rbm4,h3);
%RBM训练得到第五隐层的网络参数,输入为第四隐层的输出
rbm5 = rbm([50,20]);
rbm5 = checkrbmtrain(@rbmtrain1,rbm5,h4,50,0.1);
net_rbm5 = rbm2nnet(rbm5,'up');
h5 = nnetfw(net_rbm5,h4);
%构建深度网络,并初始化参数为rbm训练出的参数。
net1 = nnet([784,400,200,100,50,20,10],'softmax');
net1.w{1} = net_rbm1.w{1};
net1.w{2} = net_rbm2.w{1};
net1.w{3} = net_rbm3.w{1};
net1.w{4} = net_rbm4.w{1};
net1.w{5} = net_rbm5.w{1};
%对深度网络进行BP训练
net2 = nnettrain(net1,X,Y,1000);
%用训练好的深度网络net2分类识别
y = nnetfw(net2,X);
3. 深度玻尔兹曼机DBM
Deep Boltzmann Machine 是另一种深度生成模型。与深度信念网络(DBN)不同的是,它是一个完全无向的模型。与 RBM 不同的是,DBM 有几层潜变量(RBM 只有一层)。但是像 RBM 一样,每一层内的每个变量是相互独立的,并条件于相邻层中的变量。深度玻尔兹曼机已经被应用于各种任务。
其实 DBM就是玻尔兹曼机,只不过它有好多层啊!
给出一个DBM和DBN的区别比较图:


可以看出DBN是有向图,DBM是无向图。
广义的来看
DBN是含有多个连接层的隐含变量的sigmoid belief networks
DBM是含有多个连接层的隐含变量的Markov random fields
两者都是概率图模型,都是由RBMs堆叠起来的,主要的不同是来自他们的连接方式。
DBN连接两个层是有方向的,在RBM中是无向的,在外部的连接是有向的,
DBM连接所有的层是无向的,每一层都是RBM。
在DBNs中的训练也是调用RBM,是以RBM为单元进行的逐层的训练。感觉跟DBM没有太大去分。
DBM在其中每一层捕获前一层的隐含的神经元之间复杂的,高阶的相关性,可以潜在的去学习一些复杂的内部表示,与DBN不同的是其可以自上而下的调节其反馈调节,具有更好的鲁棒性,但是计算复杂。
4. 判别受限玻尔兹曼机DRBM
RBM是Hinton提出的一种无向生成模型,是目前研究较热的深度学习算法模型的基础模型,主要充当其他分类算法的特征提取器,而不是直接充当分类器。
而判别受限玻尔兹曼机(DRBM)模型可以直接充当分类器,相当于一个深度学习模型的最后一层,目前DRBM模型已经被成功应用在数字识别、文本分类和邮件分类中。
我们用二进制形式的隐藏单元对由二进制像素组成的图像进行建模,用受限玻尔兹曼机对要分类的样本和样本相应的类标签进行训练,就像Hinton提出的深度信念网络的最后一层的训练一样,我们把这样的一个受限玻尔兹曼机称为判别式受限玻尔兹曼机。

相关论文请查看中国知网