本人最近在学习DBN(Deep Belief Net,深度信念网络),通过学习才知道有RBM这个东西。因为我所要用到的DBN是有RBM通过累加堆叠组成的,要学习DBN就要弄明白RBM的原理。我就在此说一下我自己对RBM的认识和了解,同时也希望对别人有些帮助。
所谓受限玻尔兹曼机就是对玻尔兹曼机进行简化,使玻尔兹曼机更容易更简单地使用,原本玻尔兹曼机的隐元和显元之间是全连接的,而且隐元和隐元之间也是全连接的,这样增加了计算量和计算难度,使用困难。而RBM则是对BM进行一些限制,使隐元之间没有连接,这样就使得计算量大大减小,使用起来也就方便了很多。
RBM应用到了能量学上的一些知识:在能量最少的时候,物质最稳定。应用到RBM就是,在能量最少的时候,网络最稳定,也就是网络最优。
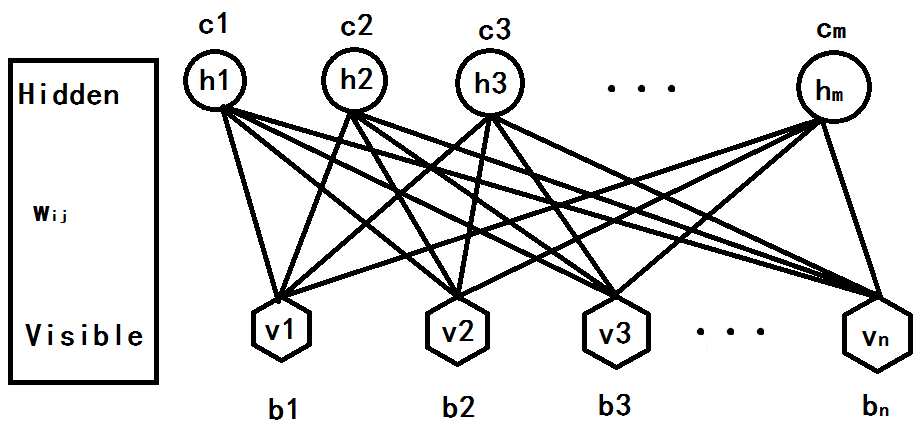
RBM有几个参数,一个是可视节点与隐藏节点直接的权重矩阵Wij,一个是可视节点的偏移量b = (b1,b2,...,bnb1,b2,...,bn),一个是隐藏节点的偏移量c = (c1,c2,...,cmc1,c2,...,cm).这几个参数决定了RBM网络将一个n维的样本编码成一个什么样的m维的样本。
下面为了方便,我们使用一个二进制的RBM来说一下原理吧。所谓二进制也就是隐元和显元的状态只能取1或0.这样它的能量函数为:
E(v,h)=−∑i=1n∑j=1mwijvihj−∑i=1nbivi−∑j=1mcjhjE(v,h)=−∑i=1n∑j=1mwijvihj−∑i=1nbivi−∑j=1mcjhj
在这个网络中,我们根据吉布斯(Gibbs)分布:p(v,h)=1Ze−E(v,h)p(v,h)=1Ze−E(v,h)和上面的能量函数建立模型的联合概率分布.
这是一张我自己画的一层RBM,这个网络有n个可视节点和m个隐藏节点,其中每个可视节点都只与m个隐藏节点相关,其它可视化节点相互独立,也就是这个可视节点的状态只受m个隐藏节点的影响,同理可知,对于每个隐藏节点也是如此,只受n个可视节点影响。也就是:
p(h|v)=∏i=1mp(hi|v)和p(v|h)=∏i=1np(vi|h)p(h|v)=∏i=1mp(hi|v)和p(v|h)=∏i=1np(vi|h)
由于隐元之间缺少连接,则边缘分布就变的容易计算了:
p(v)=1Z∑hp(v,h)=1Z∏i=1nebivi∏j=1m(1+ecj+∑ni=1wijvi)p(v)=1Z∑hp(v,h)=1Z∏i=1nebivi∏j=1m(1+ecj+∑i=1nwijvi)
同理p(h)p(h)也可以计算出来,这儿就不写了。
根据贝叶斯原理,知道联合概率和边缘概率,条件概率就很容易计算出来了:
p(hj=1|v)=ϕ(∑i=1nwijvi+cj)p(hj=1|v)=ϕ(∑i=1nwijvi+cj)
p(vi=1|h)=ϕ(∑j=1mwijhj+bi)p(vi=1|h)=ϕ(∑j=1mwijhj+bi)
这儿ϕϕ是sigmoid函数。这样基本上就是RBM的全部原理了,除了训练过程没有写(这个稍后我会给出)。这儿的条件概率就是根据隐元(显元)的状态、权重WW、偏差b(c)b(c)来确定显元(隐元)的状态。
接下来给出条件概率的推导过程:
先设
αl(h)=−∑j=1mwjlhj−blαl(h)=−∑j=1mwjlhj−bl
和
β(v−l,h)=−∑i=1,i≠ln∑j=1mwijvihj−∑i=1,i≠lnbivi−∑j=1mcjhjβ(v−l,h)=−∑i=1,i≠ln∑j=1mwijvihj−∑i=1,i≠lnbivi−∑j=1mcjhj
则
E(v,h)=vlαl(h)+β(v−l,h)E(v,h)=vlαl(h)+β(v−l,h)
p(vl=1|h)=p(vl=1|v−l,h)=p(vl,v−l,h)p(v−l,h)p(vl=1|h)=p(vl=1|v−l,h)=p(vl,v−l,h)p(v−l,h)
=e−E(vl=1,v−l,h)e−E(vl=1,v−l,h)+e−E(vl=0,v−l,h)=e−E(vl=1,v−l,h)e−E(vl=1,v−l,h)+e−E(vl=0,v−l,h)
=e−β(v−l,h)−1×αl(h)e−β(v−l,h)−1×αl(h)+e−β(v−l,h)−0×αl(h)=e−β(v−l,h)−1×αl(h)e−β(v−l,h)−1×αl(h)+e−β(v−l,h)−0×αl(h)
=e−β(v−l,h)⋅e−αl(h)e−β(v−l,h)⋅(e−αl(h)+1)=e−αl(h)e−αl(h)+1=e−β(v−l,h)⋅e−αl(h)e−β(v−l,h)⋅(e−αl(h)+1)=e−αl(h)e−αl(h)+1
=11+eαl(h)=ϕ(−αl(h))=ϕ(∑j=1mwjlhj+bl)=11+eαl(h)=ϕ(−αl(h))=ϕ(∑j=1mwjlhj+bl)
OK,大功告成,这样整个推导过程就完成了。
至于训练过程,我在网易博客里看到一个人写的非常好,我就不再详细地写了,我就直接引用他的一张图就可以了。
图片来自http://blog.163.com/silence_ellen/blog/static/176104222201431710264087/这个博客,博主:路过天堂_ellen。
参考文献:《A Introduction to Restricted Boltzmann Machines》作者Asja Fischer and Christian Igel.

转自:https://blog.csdn.net/u014487025/article/details/51722324