一,io流的概念:是一个连接起点和终点的一个通道
就是把文本文件(记事本),二进制文件(图片,视频)进行数据转移,即下载上传等
二,流的分类
1:按单位分:
字符流(每次操作的最小单位是一个字符char)
字节流(每次操作的最小单位是一个字节byte)
2:按方向分:
输出流(从程序里到外部文件就是输出流)
例如用Writer给记事本里面写东西
输入流(从外部文件到程序里就是输入流)
例如用Reader读取记事本里面的东西
3:按功能分:
节点流 (直接链接起点和终点的流)
过滤流 (不直接链接起点和终点,链接的是一个节点流)
流总共有60多种,但是这四个类都是抽象类,这四个类都是所有io流类的父类

三,学习Writer和Reader
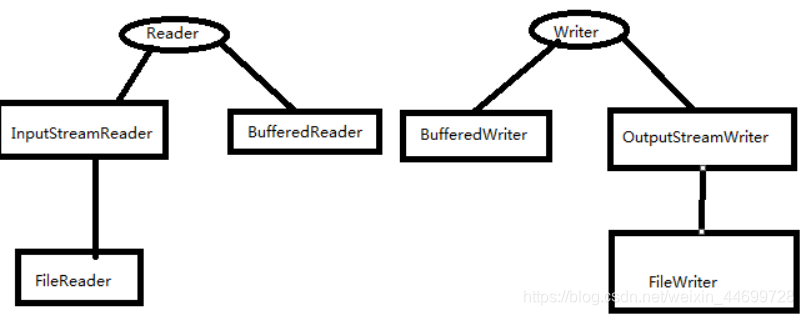
Reader–字符输入流(抽象类)
Writer–字符输出流(抽象类)
对应的子类:
InputStreamReader–字符输入转换流
OutputStreamWriter–字符输出转换流
FileReader–文件字符输入流
FileWriter–文件字符输出流
BufferedReader–带有缓冲区字符输入流
BufferedWriter–带有缓冲区字符输出流
缓冲区默认大小是8192个字符,即1024*8,即8KB
1,一个简单的io流例子:
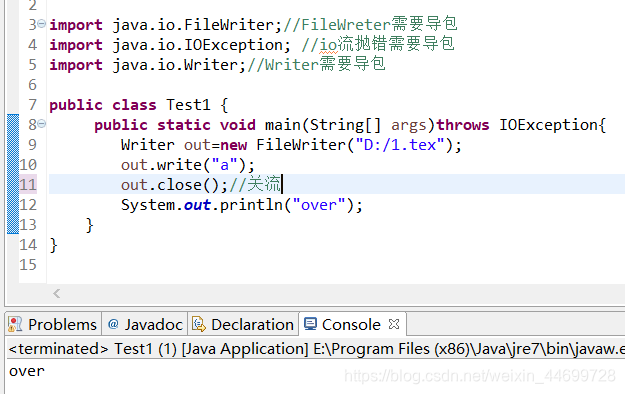
运行时,在D盘生成一个文件名为1.tex的记事本文件,打开记事本,可以看见程序把a写入了记事本。

我试了下,好像这个文件不能放在桌面上
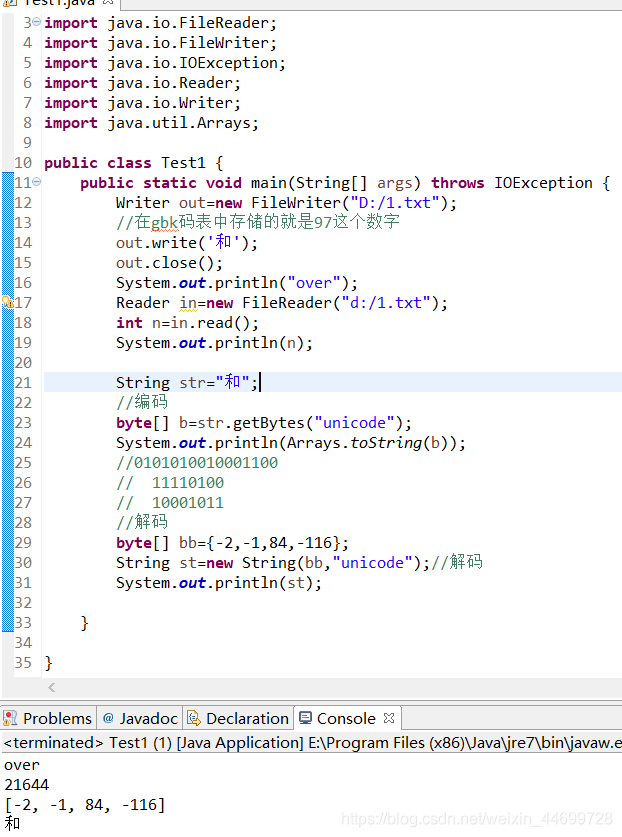
2,编码和解码:
编码:比如给记事本文件里写了一个和,他是如何编码的?
不同的码表对应的数字不同,计算机只存储二进制文件,字符先转化成数字,数字能转换成二进制,java和记事本默认的码表不一样,记事本用的码表是gbk,java用的码表是unicode。
以什么码表编码,就以什么码表解码,否则就出现乱码。
###和字用unicode编码后得到:[-2,-1,84,-116](数组前面用-2,-1开头的就是用unicode编码的)84代表编码的高八位,-116代表编码的低八位
先将84和-116转化成二进制补码
84:01010100
-116:10001011
编码:0101010010001011,然后转10进制就是21644
解码的时候在unicode中,char中21644对应的字符就是“和”。
如果不用unicode码表,而是用默认的gbk,就会出现乱码
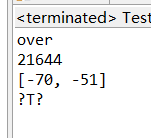
再比如:

所以Writer的时候步骤是:java中写字符就是写数字,unicode先对数字解码成字符,再将字符以gbk码表编码成gbk中对应的数字,打开记事本的时候,再以gbk码表解码成字符
Reader的时候反过来,先将记事本中的字符(就是数字)解码成字符,再将字符以unicode码表编译成unicode对应的数字,然后在unicode码表编译成字符显示出来
注意:编写字符串的时候,是把字符串拆成字符,一个一个编的
缓冲区:字符流天生自带缓冲区,当流没关的时候,发现数据没有直接写入目的地,原因是数据先积攒到了缓冲区里,当缓冲区积攒的数据够8KB时,再统一传过去
缓冲区默认8KB
缓冲区的作用就是用来提高读写速度,就是一个积攒数据的地方
out.flush();
//强制清空缓冲区,此时就把缓冲区里面的数据发送到目的地
out.close();
//在关闭流之前先自动清空了缓冲区
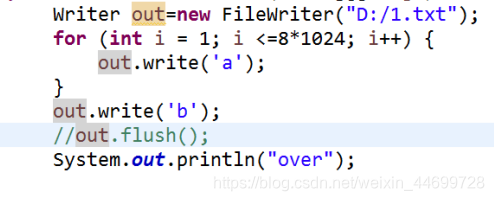
此程序没有关流,也没有清空缓冲区,所以当数据到达8KB时先送过去,即记事本写了8KB的a,而b在缓冲区
Writer类:
按单位分是字符流
按方向分是输出流
按功能分是节点流
二,Reader:
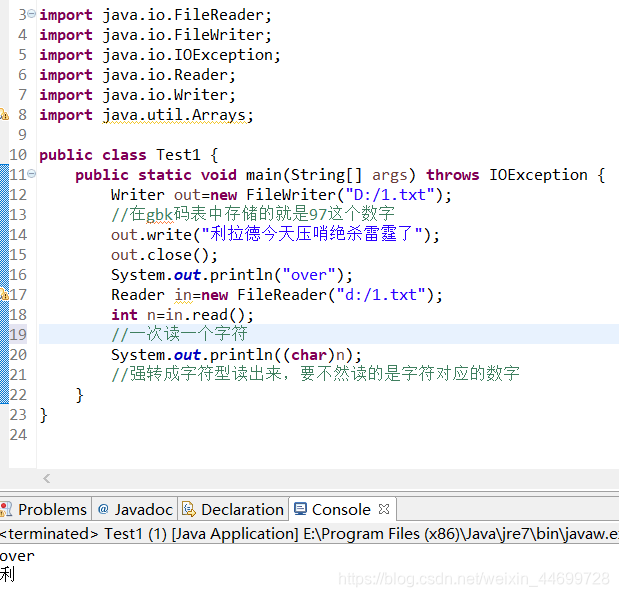
1,读一个字符:
2,每次读取一个数组的长度:
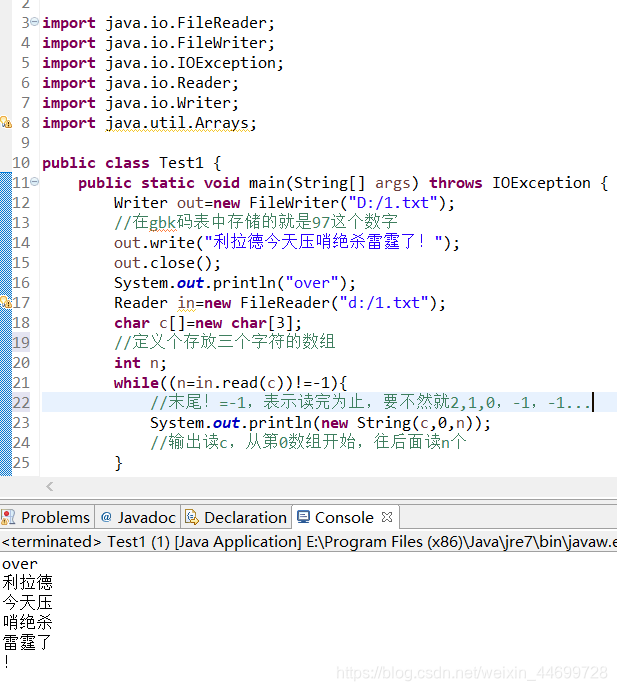
但是他在数组是怎么读的?
假如有abcdefg
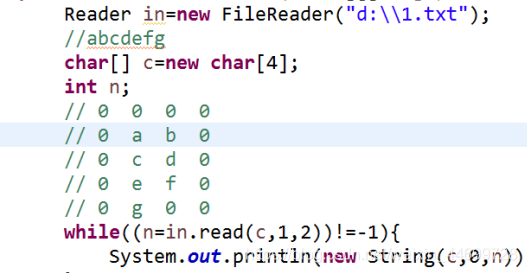
(c,1,2)表示一次开辟4个空间放字符,从c[0]开始存放两个字符,存放如上图,读的时候,每次读两个,c[0],c[1]。
所以运行结果是ace