Metrics-server简介
Pod核心指标是相对于自定义指标而言的,也就是指通过采集Pod CPU、内存等核心资源指标实现Pod弹性伸缩。Metrics-server是用来替换heapster获取集群资源指标数据的服务,heapster从1.11开始逐渐被废弃了。
metrics-server,是一种API Server,提供了核心的Metrics API,就像k8s组件kube-apiserver提供了很多API群组一样,但它不是k8s组成部分,而是托管运行在k8s之上的Pod。为了让用户无缝的使用metrics-server当中的API,还需要把这类自定义的API,通过聚合器聚合到核心API组里,然后把此API当作是核心API的一部分,通过kubectl api-versions可直接查看。Metrics server是K8S集群资源使用情况的聚合器。
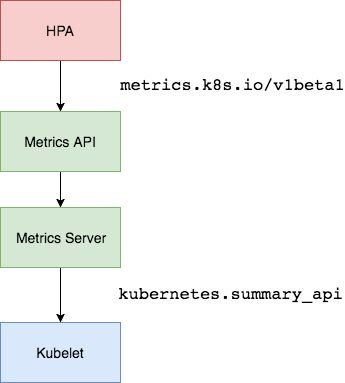
metrics-server收集指标数据的方式是从各节点上kubelet提供的Summary API 即10250端口收集数据,收集Node和Pod核心资源指标数据,主要是内存和cpu方面的使用情况,并将收集的信息存储在内存中,所以通过kubectl top不能查看资源数据的历史情况,其它资源指标数据则通过prometheus采集。
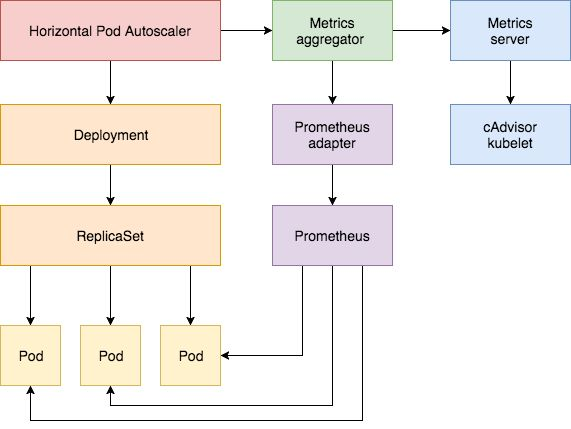
k8s中很多组件是依赖于资源指标API的功能 ,比如kubectl top 、hpa,如果没有一个资源指标API接口,这些组件是没法运行的。
安装metrics-server
下载该链接目录下的六个文件(说明:因为我安装的K8s版本是1.13.1,故此使用的对应分支也是1.13.1)。
https://github.com/kubernetes/kubernetes/blob/v1.13.1/cluster/addons/metrics-server/
查看下载的资源清单文件
1
2
3
4
|
# ls metrics-server/
auth-delegator.yaml metrics-server-deployment.yaml resource-reader.yaml
auth-reader.yaml metrics-server-service.yaml
metrics-apiservice.yaml
|
修改配置
下载下来的文件不能直接部署,有几处需要修改。
1
2
3
4
5
6
|
# vim metrics-server-deployment.yaml
image: k8s.gcr.io/metrics-server-amd64:v0.3.1
//修改为image: xiaoxu780/metrics-server-amd64:v0.3.1
image: k8s.gcr.io/addon-resizer:1.8.4
//修改为image: xiaoxu780/addon-resizer:1.8.1
|
1
2
3
4
5
6
7
8
9
|
# vim resource-reader.yaml
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats #新增这一行
- namespaces
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# vim metrics-server-deployment.yaml
#修改containers metrics-server 启动参数,修改好的如下:
containers:
- name: metrics-server
image: k8s.gcr.io/metrics-server-amd64:v0.3.1
command:
- /metrics-server
- --metric-resolution=30s
- --kubelet-insecure-tls //表示不验证kubelet API服务的HTTPS证书
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
# These are needed for GKE, which doesn't support secure communication yet.
# Remove these lines for non-GKE clusters, and when GKE supports token-based auth.
#- --kubelet-port=10255
#- --deprecated-kubelet-completely-insecure=true
----
# 修改containers,metrics-server-nanny 启动参数,修改好的如下:
command:
- /pod_nanny
- --config-dir=/etc/config
- --cpu=80m
- --extra-cpu=0.5m
- --memory=80Mi
- --extra-memory=8Mi
- --threshold=5
- --deployment=metrics-server-v0.3.1
- --container=metrics-server
- --poll-period=300000
- --estimator=exponential
# Specifies the smallest cluster (defined in number of nodes)
# resources will be scaled to.
#- --minClusterSize={{ metrics_server_min_cluster_size }}
|
应用到集群
1
2
3
4
5
6
7
8
9
10
|
# kubectl create -f ./
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
configmap/metrics-server-config created
deployment.extensions/metrics-server-v0.3.1 created
service/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
|
验证metrics-server
查看是否成功运行
1
2
3
|
# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
metrics-server-v0.3.1-75d77b57cd-hlwlh 2/2 Running 0 3m
|
查看api
1
2
|
# kubectl api-versions | grep metrics-server
metrics.k8s.io/v1beta1
|
查看Metrics API数据,启动一个代理以便curl api
1
2
|
# kubectl proxy --port=8091
Starting to serve on 127.0.0.1:8091
|
直接查看接口数据,可获取的资源:nodes和pods
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# curl localhost:8091/apis/metrics.k8s.io/v1beta1
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "metrics.k8s.io/v1beta1",
"resources": [
{
"name": "nodes",
"singularName": "",
"namespaced": false,
"kind": "NodeMetrics",
"verbs": [
"get",
"list"
]
},
{
"name": "pods",
"singularName": "",
"namespaced": true,
"kind": "PodMetrics",
"verbs": [
"get",
"list"
]
}
]
|
查看获取到的Node资源指标数据:cpu和内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# curl localhost:8091/apis/metrics.k8s.io/v1beta1/nodes
{
"kind": "NodeMetricsList",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes"
},
"items": [
{
"metadata": {
"name": "k8s-node02",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/k8s-node02",
"creationTimestamp": "2018-10-06T08:48:51Z"
},
"timestamp": "2018-10-06T08:48:23Z",
"window": "30s",
"usage": {
"cpu": "118493217n",
"memory": "1320848Ki"
}
|
kubectl top查看
既然通过接口查看到了数据,就可以使用kubectl top直接查看了。
查看node
1
2
3
|
# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s 135m 1% 2476Mi 7%
|
查看pod
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# kubectl top pods -n kube-system
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-687b7cc79c-knj87 1m 12Mi
calico-node-7rj8c 13m 33Mi
coredns-5b47d4476c-8wdb7 2m 20Mi
coredns-5b47d4476c-92wnq 2m 19Mi
dns-autoscaler-5b547856bc-95cft 1m 10Mi
kube-apiserver-k8s 19m 410Mi
kube-controller-manager-k8s 34m 68Mi
kube-proxy-cdlzp 2m 29Mi
kube-scheduler-k8s 8m 22Mi
kubernetes-dashboard-d7978b5cc-lvf6l 1m 21Mi
metrics-server-v0.3.1-584d9c57d4-cbkw2 1m 28Mi
|
Metrics Server从Kubernetes集群中每个Node上kubelet的API收集metrics数据。通过Metrics API可以获取Kubernetes资源的Metrics指标,Metrics API挂载/apis/metrics.k8s.io/ 下。 可以使用kubectl top命令访问Metrics API,例如:
1
2
|
# kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes"
{"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/metrics.k8s.io/v1beta1/nodes"},"items":[{"metadata":{"name":"k8s","selfLink":"/apis/metrics.k8s.io/v1beta1/nodes/k8s","creationTimestamp":"2019-01-07T15:25:55Z"},"timestamp":"2019-01-07T15:25:52Z","window":"30s","usage":{"cpu":"135838412n","memory":"2532372Ki"}}]}
|
metrics-server已经可以正常工作了,核心指标已经获取到了,其它的自定义指标获取则要借助于prometheus了。
k8s v1.10版本之前仍然要通过heapster获取指标数据,否则即使部署了metrics-server,kubectl top这个指令仍然连接heapster。
HPA介绍和使用
HPA是k8s一个非常强大的功能,根据Pod的cpu、内存及其它指标自动伸缩Pod副本数量,HPA目前有两个版本,通过kubectl api-versions查看:
1
2
3
4
|
# kubectl api-versions | grep autoscal
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
|
- autoscaling/v1:仅支持核心指标API,目前是由metrics-service提供的metrics.k8s.io/v1beta1,提供的指标来定义,也就是cpu和内存,而内存是不可压缩型资源,不支持弹性缩放,所以只能支持cpu指标来弹性伸缩。
- autoscaling/v2:除了核心指标之外,还支持定义自定义指标,目前是由custom-metrics-apiserver服务提供的custom.metrics.k8s.io/v1beta1,比如内存、网络方面的指标,前提是配置了自定义指标API服务。
下面创建一个Pod,然后创建一个HPA监控Pod的CPU使用率,再对Pod实施压测,查看HPA是否根据Pod的cpu使用率伸缩Pod副本。
创建一个Pod
1
2
3
4
5
6
7
8
|
# kubectl run php-apache --image=k8s.gcr.io/hpa-example --requests=cpu=200m --expose --port=80
service/php-apache created
deployment.apps/php-apache created
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
php-apache-b5f58cc5f-6csfw 1/1 Running 0 28s 192.168.85.198 k8s-node01 <none>
|
定义HPA
HPA监控目标对象的cpu使用率,确保所有副本的Pod的CPU使用不超50%, 并适当的进行伸缩。
1
2
|
# kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
horizontalpodautoscaler.autoscaling/php-apache autoscaled
|
当前为0%
1
2
3
|
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 30s
|
启动一个程序对其压测
1
2
3
|
# kubectl run -i --tty load-generator --image=busybox /bin/sh
/ # while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK
|
等一会查看hpa
1
2
3
|
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 481%/50% 1 10 1 21m
|
POD的cpu占用率已达481%,因此hpa控制器自动将pod副本调整到了10个。
1
2
3
|
# kubectl get deployments php-apache
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
php-apache 10 10 10 10 25m
|
停止压测,过几分钟后查看,HPA自动缩减至1个。
1
2
3
4
5
6
7
|
# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 39m
# kubectl get deployments php-apache
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
php-apache 1 1 1 1 39
|
问题
1.通过Metrics API我们可以获取到指定node或者pod的当前资源使用情况,但是该服务并不存储任何信息也不支持其他后端存储,所以我们不可能通过Metrics API来获取资源的历史使用情况。
2.由于Metrics Server只能获取核心资源指标,对于其他指标(如网络、HTTP等),还得使用prometheus,并实现数据持久化存储。
关注微信公众号,获取更多信息

文章来源:https://xuchao918.github.io/2019/04/19/%E5%A6%82%E4%BD%95%E5%AE%9E%E7%8E%B0K8s-Pod%E6%A0%B8%E5%BF%83%E6%8C%87%E6%A0%87%E5%BC%B9%E6%80%A7%E4%BC%B8%E7%BC%A9/