首页
移动开发
物联网
服务端
编程语言
企业开发
数据库
业界资讯
其他
搜索
scrapy爬取伯乐在线文章数据
其他
2019-04-24 09:08:07
阅读次数: 0
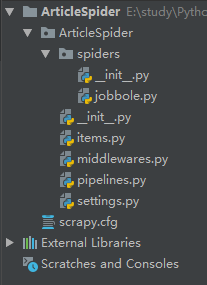
创建项目
切换到ArticleSpider目录下创建爬虫文件
猜你喜欢
转载自
www.cnblogs.com/bkwxx/p/10760340.html
scrapy爬取伯乐在线文章数据
Scrapy爬取伯乐在线文章
Scrapy爬取伯乐在线的所有文章
Scrapy爬取伯乐在线所有文章
爬虫实战——Scrapy爬取伯乐在线所有文章
scrapy入门:爬取伯乐在线
【Scrapy教程】01 初学者笔记(爬取伯乐在线文章实战)
基于scrapy的分布式爬虫(5):伯乐在线文章爬取
使用scrapy爬取伯乐在线多线程存为MySQL数据库
重磅!PYTHON实战使用SCRAPY框架爬取伯乐在线 5000多条数据
Scrapy分布式爬虫打造搜索引擎- (二)伯乐在线爬取所有文章
爬取伯乐在线文章(三)爬取所有页面的文章
爬取伯乐在线文章(四)将爬取结果保存到MySQL
Scrapy分布式爬虫打造搜索引擎——(二) scrapy 爬取伯乐在线
Python爬虫爬取伯乐在线
Scrapy爬取伯乐在线采用两种入库方法
Python爬虫之scrapy--01爬取伯乐网文章
爬取伯乐在线文章(二)通过xpath提取源文件中需要的内容
第三天,爬取伯乐在线文章代码,编写items.py,保存数据到本地json文件中
伯乐在线文章URL
Python爬虫-爬取伯乐在线美女邮箱
Python爬虫爬取伯乐在线网站信息
scrapy爬取某个手机app的文章数据
使用scrapy框架进行抓取伯乐在线所有文章(一)
scrapy定向爬取jobbole文章
python爬虫系列(3.4-使用xpath和lxml爬取伯乐在线)
scrapy爬取动态数据
Scrapy全站数据爬取
scrapy图片数据爬取
bs4主要知识点介绍及实例解析---利用bs4爬取伯乐在线(分别存储在数据库和xls表中)
今日推荐
基于大语言模型的开源知识库问答系统 MaxKB GitHub Star 数量突破 5,000 个!
美国拟限制 AI 大模型出口中国和俄罗斯
苹果将与 OpenAI 达成协议,将 ChatGPT 应用于 iPhone
openKylin 社区生态委员会第六次会议圆满召开
阿里云正式发布通义千问 2.5
Python 3.13 发布首个 Beta:实验性自由线程模式和 JIT、改进交互式解释器
Stack Overflow 拿我的代码去训练 AI 大模型,还封了我的账号
Pop!_OS 的 COSMIC 桌面完成 App Store 上架工作
《2024 年一季度互联网投融资运行情况》研究报告
报告:Django 仍然是 74% 开发者的首选
15 年前上了“FFmpeg 耻辱柱”,今天他还得谢谢咱——腾讯QQPlayer一雪前耻?
TIOBE 5 月榜单:Fortran “复活”进入 Top 10
周排行
记一下去大梅沙的准备(2018-05-26)
Spring 注解 事务
基于HTTP协议的客户端缓存
阿里云rds 备份和还原
[PHP] 几个拖慢 PHP 程序/API 运行速度的点
python 代码风格------------PEP8规则
js控制json生成菜单——自制菜单(一)
将字符串: 'k:1|k1:2|k2:3|k3:4 ' ,处理成 python 字典: {'k':1, 'k1':2, ...}
微信小程序转支付宝小程序
Qt551.窗口滚动条
每日归档
更多
2024-05-13(18)
2024-05-12(0)
2024-05-11(38)
2024-05-10(38)
2024-05-09(35)
2024-05-08(42)
2024-05-07(14)
2024-05-06(40)
2024-05-05(0)
2024-05-04(7)