Scrapy简单介绍及爬取伯乐在线所有文章
一.简说安装相关环境及依赖包
1.安装Python(2或3都行,我这里用的是3)
2.虚拟环境搭建:
依赖包:virtualenv,virtualenvwrapper(为了更方便管理和使用虚拟环境)
安装:pip install virtulaenv,virtualenvwrapper或通过源码包安装
常用命令:mkvirtualenv --python=/usr/local/python3.5.3/bin/python article_spider(若有多个Python版本可以指定,然后创建虚拟环境article_spider);
workon :显示当前环境下所有虚拟环境
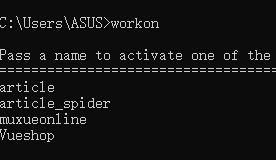
workon 虚拟环境名:进入相关环境:

退出虚拟环境:deactivate
删除虚拟环境:rmvirtualenv article_spider
安装相关依赖包及Scrapy框架:pip install scrapy(建议用豆瓣源镜像安装,快得多pip install https://pypi.douban.com /simple scrapy)
windows操作环境中还需安装(pip install pypiwin32)
注:若安装失败有可能是版本不同,可以到官网查看对应版本安装:https://www.lfd.uci.edu/~gohlke/pythonlibs/
3.新建Scrapy项目(可以定制模板,这里用默认的):
scrapy start project article_spider:

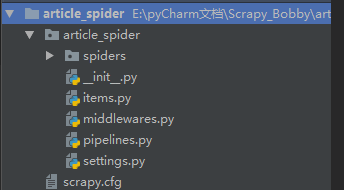
用Pycharm打开,结构如下(与Django相似),爬虫都放在spider文件夹中:
创建爬虫文件:cd article_spider:进入项目
scrapy genspider 爬虫文件名 所爬取的域名


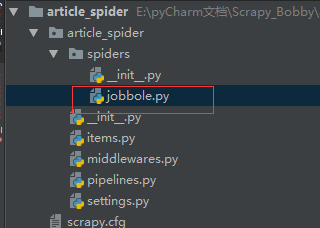
jobbole.py文件如下(start_url中的url都会通过parse函数,可以把要爬取的网址放进start_url):查看Spider源码可知,通过start_requests返回url,是一个生成器
# -*- coding: utf-8 -*- import scrapy class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/'] def parse(self, response): pass
二.爬虫相关技能介绍
1.新建main函数,执行并调试爬虫:
from scrapy.cmdline import execute import sys import os #将父目录添加到搜索目录中 sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(["scrapy","crawl","jobbole"])
修改setting.py:
# Obey robots.txt rules #默认为False会过滤掉ROBOTS协议 ROBOTSTXT_OBEY = True
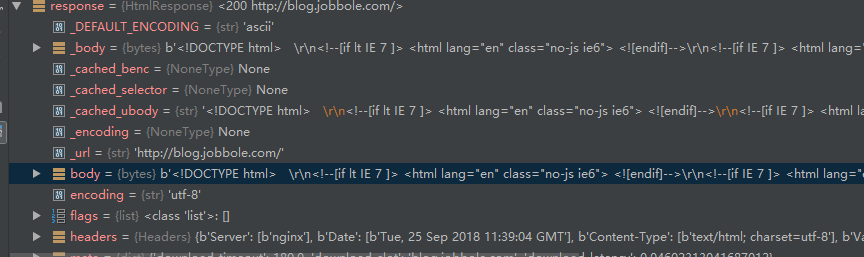
调试结果如下,body中为网页所有内容:
3.scrapy shell的使用(方便调试):
3.1scrapy shell "http://blog.jobbole.com/114405/"(scrapy shell 要爬取调试的url)

3.2xpath提取并获取文章名,extract()方法将Selectorlist转换为list:

3.Xpath的使用,提取所需内容(比Beautifulsoup快得多):
3.1xapth节点关系:
父节点
子节点
同胞节点(兄弟节点)
先辈节点
后代节点
3.2xpath语法简单使用:



3.3提取文章名:
# -*- coding: utf-8 -*- import scrapy class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/114405/']
def parse(self, response):
title=response.xpath('//*[@id="post-114405"]/div[1]/h1/text()')
pass

返回的是一个Selectorlist,便于嵌套xpath
3.4xpath获取时间:

3.5获取点赞数,xpath的contains函数,获取class包含vote-post-up的span标签下的:

3.6获取收藏数:
fav_nums=response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
#使用正则匹配,有可能无收藏,匹配不到 match_fav=re.match(".*(\d+).*",fav_nums) if match_fav: fav_nums=int(match_fav.group(1)) else: fav_nums=0
3.7获取评论数:
comments_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0] math_comments=re.match(".*(\d).*",comments_nums) if math_comments: comments_nums=int(math_comments) else: comments_nums=0
3.8文章内容:

3.9标签提取:
tag_list= response.xpath('//*[@id="post-114405"]/div[2]/p/a/text()').extract() tag_list=[element for element in tag_list if not element.strip().endswith("评论")] tags=','.join(tag_list)
4.CSS选择器筛选提取内容:
4.1CSS常用方法:

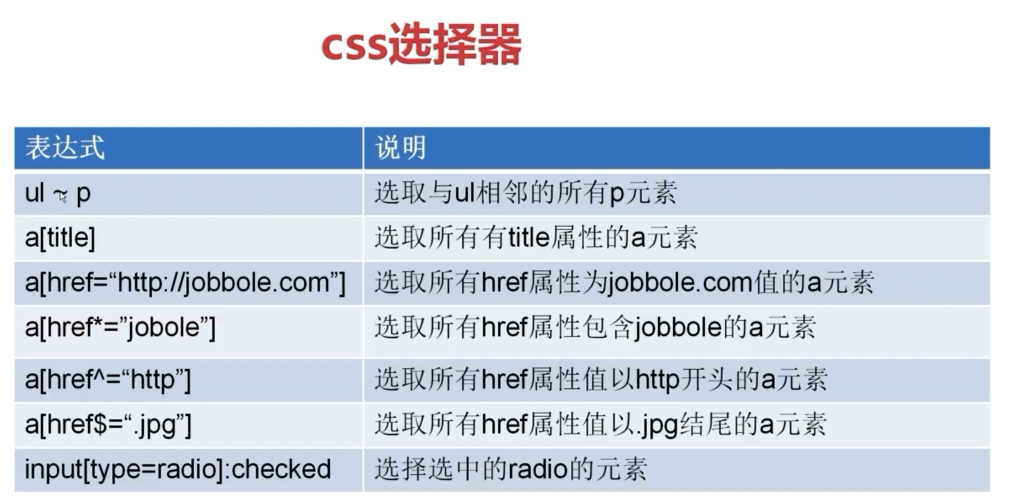

4.2获取文章名:

4.3获取时间:

4.4获取点赞数:

4.5获取收藏数:

4.6获取评论数:

4.7文章内容:

4.8标签提取:

5.Xpath和CSS提取比较,哪种方便用哪个都行,extract()[0]可以换成extract_first("")直接提取第一个,无则返回空:
# -*- coding: utf-8 -*- import scrapy import re class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/114405/'] def parse(self, response): #通过xpath提取 title=response.xpath('//div[@class="entry-header"]/h1/text()') create_date= response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].replace("·","").strip() praise_nums=response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0] if praise_nums: praise_nums=int(praise_nums) else: praise_nums=0 fav_nums=response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0] match_fav=re.match(".*(\d+).*",fav_nums) if match_fav: fav_nums=int(match_fav.group(1)) else: fav_nums=0 comments_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0] math_comments=re.match(".*(\d).*",comments_nums) if math_comments: comments_nums=int(math_comments) else: comments_nums=0 cotent=response.xpath('//div[@class="entry"]').extract()[0] tag_list= response.xpath('//*[@id="post-114405"]/div[2]/p/a/text()').extract() tag_list=[element for element in tag_list if not element.strip().endswith("评论")] tags=','.join(tag_list) #通过CSS提取 title=response.css(".entry-header > h1::text").extract()[0] create_time=response.css("p.entry-meta-hide-on-mobile::text").extract()[0].replace("·","").strip() praise_nums=int(response.css("span.vote-post-up h10::text").extract()[0]) if praise_nums: praise_nums = int(praise_nums) else: praise_nums = 0 fav_nums=response.css(".bookmark-btn::text").extract()[0] match_fav = re.match(".*(\d+).*", fav_nums) if match_fav: fav_nums = int(match_fav.group(1)) else: fav_nums = 0 comments_nums=response.css("a[href='#article-comment'] span::text").extract()[0] math_comments = re.match(".*(\d).*", comments_nums) if math_comments: comments_nums = int(math_comments) else: comments_nums = 0 content=response.css("div.entry").extract()[0] tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tags = ','.join(tag_list)
三.具体实现
1.获取所有文章url:
from scrapy import Request #提取域名的函数 #python3 from urllib import parse #python2 #import urlparse class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): ''' 1.获取文章列表页中的文章url并交给scrapy下载后进行解析; 2.获取下一页url并交给scrapy下载交给parse解析字段 ''' #解析列表页中所有文章url交给scrapy下载后进行解析 post_urls=response.css("div#archive div.floated-thumb div.post-meta p a.archive-title::attr(href)").extract() for post_url in post_urls: #若提取的url不全,不包含域名,可以用parse拼接 #Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail) #生成器,回调 yield Request(post_url,callback=self.parse_detail) #提取下一页并交给scrapy下载 next_url=response.css(".next.page-numbers::attr(href)").extract_first() if next_url: yield Request(next_url,callback=self.parse) def parse_detail(self,response): # 通过xpath提取 title=response.xpath('//div[@class="entry-header"]/h1/text()') create_date= response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].replace("·","").strip() praise_nums=response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0] if praise_nums: praise_nums=int(praise_nums) else: praise_nums=0 fav_nums=response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0] match_fav=re.match(".*(\d+).*",fav_nums) if match_fav: fav_nums=int(match_fav.group(1)) else: fav_nums=0 comments_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0] math_comments=re.match(".*(\d).*",comments_nums) if math_comments: comments_nums=int(math_comments) else: comments_nums=0 cotent=response.xpath('//div[@class="entry"]').extract()[0] tag_list= response.xpath('//*[@id="post-114405"]/div[2]/p/a/text()').extract() tag_list=[element for element in tag_list if not element.strip().endswith("评论")] tags=','.join(tag_list)
2.