Ok,不多说废话,先附上相关代码。
我们这里采用的是不带头单链表和带头结点的循环双向链表供大家参考。
单链表
typedef struct SListNode
{
int data ;
struct SListNode* next ;
}SListNode ;
//封装了一个指向链表节点指针的结构体,通过这个结构体变量进行单链表的调用。
typedef struct SList
{
struct SListNode* first ;
}SList ;
//SList.h
#pragma once
typedef int SLDataType ;
typedef struct SListNode
{
int data ;
struct SListNode* next ;
}SListNode ;
typedef struct SList
{
struct SListNode* first ;
}SList ;
//初始化&销毁
void SListInit(SList* list) ;
//销毁
void SListDestroy(SList* list) ;
//头插
void SListPushFront(SList* list, SLDataType data) ;
//头删
void SListPopFront(SList* list) ;
//打印
void SListPrint(SList* list) ;
//尾插
void SListPushBack(SList* list, SLDataType data) ;
//尾删
void SListPopBack(SList* list) ;
//查找
SListNode* SListFind(SList* list, SLDataType data) ;
//在pos位置的节点后插入元素
void SListInsertAfter(SListNode* pos, SLDataType data) ;
//删除pos位置后的第一个节点
void SListEraseAfter(SListNode* pos) ;
//删除遇到的指定的第一个节点
void SListRemove(SList* list, SLDataType data) ;
//**************************************************
//SList.c
#include "SList.h"
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
//初始化
void SListInit(SList* list)
{
assert(list != NULL) ;
list->first = NULL ;
}
//销毁
void SListDestroy(SList* list)
{
SListNode* next ;
SListNode* cur ;
for(cur=list->first; cur!=NULL; cur=next)
{
next = cur->next ;
free(cur) ;
}
list->first = NULL ;
}
//头插
void SListPushFront(SList* list, SLDataType data)
{
SListNode* node = (SListNode*) malloc (sizeof(SListNode)) ;
assert(node) ;
node->data = data ;
node->next = list->first ;
//更新头指针的指向;
list->first = node ;
}
//头删
void SListPopFront(SList* list)
{
SListNode* old_first = list->first ;
assert(list) ; //有无链表
assert(list->first != NULL) ; //有链表,链表里是否有元素,
//若链表为空,则删除失败
list->first = list->first->next ;
free(old_first) ;
}
//打印
void SListPrint(SList* list)
{
SListNode* cur ;
assert(list) ;
for(cur=list->first; cur!=NULL; cur=cur->next)
{
printf("%d-->", cur->data) ;
}
printf("NULL\n") ;
}
//尾插
void SListPushBack(SList* list, SLDataType data)
{
SListNode* node = (SListNode*) malloc (sizeof(SListNode)) ;
SListNode* lastone = list->first ;
assert(list != NULL) ;
for( ; lastone->next != NULL; lastone=lastone->next)
{}
assert(node != NULL) ;
node->data = data ;
node->next = lastone ->next ;
lastone->next = node ;
}
//尾删
void SListPopBack(SList* list)
{
SListNode* cur ;
SListNode* m ;
assert(list != NULL) ;
assert(list->first != NULL) ;
if(list->first->next == NULL)
{
//若链表为空,则尾删即为头删
SListPopFront(list) ;
return ;
}
for(cur=list->first; cur->next->next != NULL; cur=cur->next)
{
}//找到倒数第二个节点
m = cur->next ;
cur->next = m->next ;
free(m) ;
}
//查找
SListNode* SListFind(SList* list, SLDataType data)
{
SListNode* cur = list->first ;
for( ; cur!=NULL; cur=cur->next)
{
if(cur->data == data)
{
return cur ;
}
}
return NULL ;
}
//在pos位置的节点后插入元素
void SListInsertAfter(SListNode* pos, SLDataType data)
{
SListNode* node = (SListNode*) malloc (sizeof(SListNode)) ;
assert(node != NULL ) ;
node->data = data ;
node->next = pos->next ;
pos->next = node ;
}
//删除pos位置后的第一个节点
void SListEraseAfter(SListNode* pos)
{
SListNode* node = pos->next->next ;
free(pos->next) ;
pos->next = node ;
}
//删除遇到的指定的第一个节点
void SListRemove(SList* list, SLDataType data)
{
SListNode* prev = NULL ;
SListNode* cur = list->first ;
while(cur != NULL && cur->data != data)
{
prev = cur ;
cur = cur->next ;
}
//要删除的节点不存在
if(cur == NULL )
{
return ;
}
//要删除的节点若就是第一个节点
if(prev == NULL)
{
//即头删
SListPopFront(list) ;
return ;
}
prev->next = cur->next ;
free(cur) ;
}
双链表
//双向循环链表
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
// 数据类型
typedef int DLDataType;
// 结点类型
typedef struct DListNode {
DLDataType val;
struct DListNode *next; // 后继结点
struct DListNode *prev; // 前驱结点
} DListNode;
// 双向链表类型
typedef struct {
DListNode *head; // 指向头结点
} DList;
// 内部接口
DListNode * BuyNode(DLDataType val) {
DListNode *node = (DListNode *)malloc(sizeof(DListNode));
assert(node);
node->val = val;
node->next = node->prev = NULL;
return node;
}
// 接口
// 初始化/销毁
void DListInit(DList * dlist) {
// 创建头结点
DListNode *head = BuyNode(0); // 头结点中的 val 没有实际意义
// 通常会存链表的长度
// 我这里没存
head->next = head;
head->prev = head;
// 将头结点放置到链表中
dlist->head = head;
}
// 清空
void DListClear(DList *dlist) {
DListNode *cur, *next;
// 和单链表有区别
for (cur = dlist->head->next; cur != dlist->head; cur = next) {
next = cur->next;
free(cur);
}
dlist->head->next = dlist->head;
dlist->head->prev = dlist->head;
}
// 销毁
// 头结点都没有了,是个无效链表
void DListDestroy(DList *dlist) {
DListClear(dlist);
free(dlist->head);
dlist->head = NULL;
}
// 增删改查
// 在 pos 结点前面做插入
void DListInsert(DListNode *pos, DLDataType val) {
// 申请结点
DListNode *node = BuyNode(val);
node->next = pos;
node->prev = pos->prev;
pos->prev->next = node;
pos->prev = node;
}
// 头插
void DListPushFront(DList *dlist, DLDataType val) {
DListInsert(dlist->head->next, val);
#if 0
// 申请结点
DListNode *node = BuyNode(val);
// 处理 next / prev
// 有 4 个指针
node->prev = dlist->head;
node->next = dlist->head->next;
dlist->head->next->prev = node;
dlist->head->next = node;
#endif
}
// 尾插
void DListPushBack(DList *dlist, DLDataType val) {
DListInsert(dlist->head, val);
#if 0
// 申请结点
DListNode *node = BuyNode(val);
node->prev = dlist->head->prev;
node->next = dlist->head;
dlist->head->prev->next = node;
dlist->head->prev = node;
#endif
}
// 打印
void DListPrintByHead(DListNode *head) {
for (DListNode *cur = head->next; cur != head; cur = cur->next) {
printf("%d --> ", cur->val);
}
printf("\n");
}
void DListPrintByDList(DList *dlist) {
DListPrintByHead(dlist->head);
}
// 查找
// 找到第一个 val 的结点,返回结点地址
// 如果没找到,返回 NULL
DListNode * DListFind(DList *dlist, DLDataType val) {
for (DListNode *cur = dlist->head->next; cur != dlist->head; cur = cur->next) {
if (cur->val == val) {
return cur;
}
}
return NULL;
}
// 删除 pos 结点,pos 不是头结点
void DListErase(DListNode *pos) {
pos->prev->next = pos->next;
pos->next->prev = pos->prev;
free(pos);
}
void DListPopFront(DList *dlist) {
assert(dlist->head->next != dlist->head); // 链表不为空
DListErase(dlist->head->next);
}
void DListPopBack(DList *dlist) {
assert(dlist->head->next != dlist->head); // 链表不为空
DListErase(dlist->head->prev);
}
昨天面试官面试的时候问了我一道关于链表的问题:情境如下
面试官:请说一下链表跟数组的区别?
我:数组静态分配内存,链表动态分配内存;数组在内存中连续,链表不连续;数组利用下标定位,时间复杂度为O(1),链表定位元素时间复杂度O(n);数组插入或删除元素的时间复杂度O(n),链表的时间复杂度O(1)。
根据以上分析可得出数组和链表的优缺点如下:
数组的优点
1.随机访问性强(通过下标进行快速定位)
2.查找速度快
数组的缺点
1.插入和删除效率低(插入和删除需要移动数据)
2.可能浪费内存(因为是连续的,所以每次申请数组之前必须规定数组的大小,如果大小不合理,则可能会浪费内存)
3.内存空间要求高,必须有足够的连续内存空间。
4.数组大小固定,不能动态拓展
链表的优点
插入删除速度快(因为有next指针指向其下一个节点,通过改变指针的指向可以方便的增加删除元素)
内存利用率高,不会浪费内存(可以使用内存中细小的不连续空间(大于node节点的大小),并且在需要空间的时候才创建空间)
大小没有固定,拓展很灵活。
链表的缺点
不能随机查找,必须从第一个开始遍历,查找效率低
面试官:那请说一下单链表和双链表的区别?
答:顾名思义,单链表只能单向读取单链表只有一个指向下一结点的指针,也就是只能next ; 双链表除了有一个指向下一结点的指针外,还有一个指向前一结点的指针,可以通过prev快速找到前一结点。
面试官:从你的描述来看,双链表的在查找、删除的时候可以利用二分法的思想去实现,那么这样效率就会大大提高,但是为什么目前市场应用上单链表的应用要比双链表的应用要广泛的多呢?
我:……这个我真的不知道,然后面试官就提醒我从存储效率上来考虑问题……
我回来后百度了下,发现网上的回答大都是关于链表的代码实现的,并没有关于链表本质深层次的分析,于是我便做以下分析:
单链表与双链表的结构图如下:
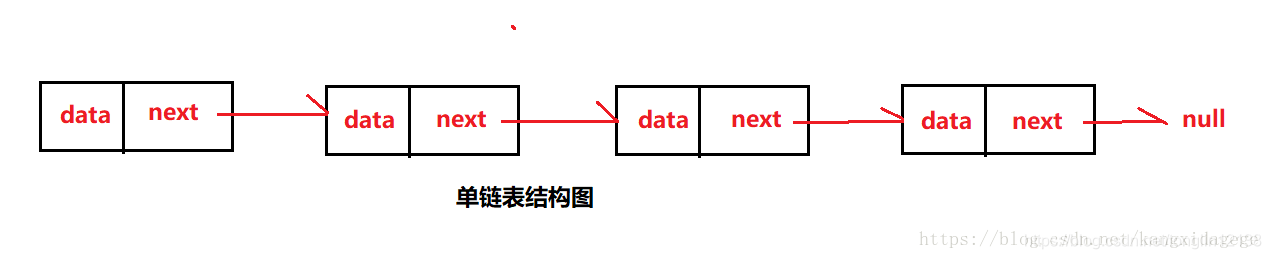
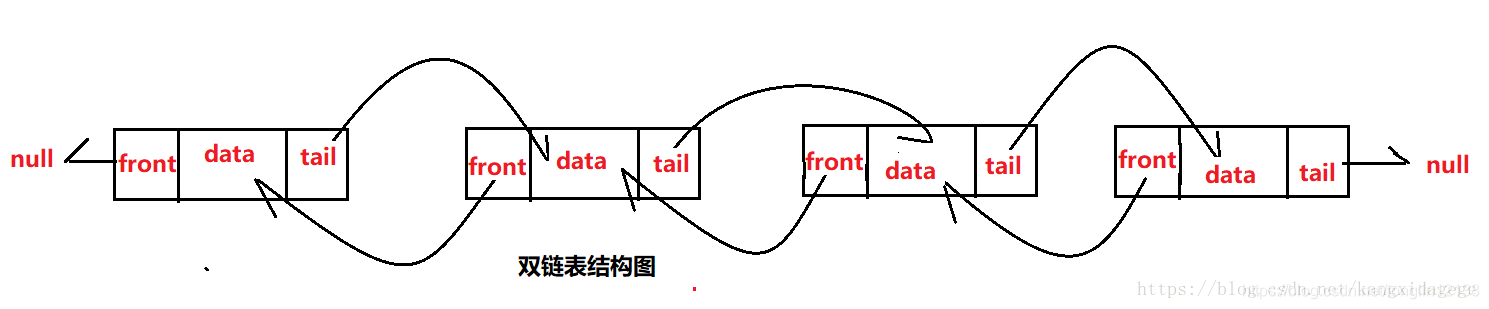
从以上结构可以得出双链表具有以下优点:
1、删除单链表中的某个结点时,一定要得到待删除结点的前驱,得到该前驱有两种方法,第一种方法是在定位待删除结点的同时一路保存当前结点的前驱。第二种方法是在定位到待删除结点之后,重新从单链表表头开始来定位前驱。尽管通常会采用方法一。但其实这两种方法的效率是一样的,指针的总的移动操作都会有2*i次。而如果用双向链表,则不需要定位前驱结点。因此指针总的移动操作为i次。
2、查找时也一样,我们可以借用二分法的思路,从head(首节点)向后查找操作和last(尾节点)向前查找操作同步进行,这样双链表的效率可以提高一倍。
可是为什么市场上单链表的使用多余双链表呢?
从存储结构来看,每个双链表的节点要比单链表的节点多一个指针,而长度为n就需要 n*length(这个指针的length在32位系统中是4字节,在64位系统中是8个字节) 的空间,这在一些追求时间效率不高应用下并不适应,因为它占用空间大于单链表所占用的空间;这时设计者就会采用以时间换空间的做法,这时一种工程总体上的衡量。
文章部分参考来源:https://blog.csdn.net/kangxidagege/article/details/80211225