1.开发环境配置
俗话说,工欲善其事,必先利其器。下面我将主要讲解如何在Windows系统中安装Python 3以及配置爬虫所需要的库文件。
1.1 Python 3的安装
第一步,安装Python 3,相关链接如下:
- 官方网址:http://python.org
- 下载地址:https://www.python.org/downloads
- 第三方库:https://pypi.python.org/pypi
- 中文教程:http://www.runoob.com/python3/python3-tutorial.html
1.1.1 Windows
在Windows环境下,建议直接采用安装Anaconda集成开发工具包,它提供了Python的科学计算环境,并且自带了Python以及常用的库。选择这种方式会使后面的环境配置过程更加方便。
Anaconda的安装:
官方下载链接地址:https://www.continuum.io/downloads
选择Python 3 版本的安装包下载就行
这里我将Anaconda下载到电脑的D盘,你也可以自己定义存放路径。在下载到D盘之后,我们开始检测python 3 是否安装成功。
具体操作如下:
在“开始”菜单中点击鼠标右键,在弹出的对话框中选择“命令提示符”,然后将系统目录转换到你下载的Anaconda下,这里我存放的位置在D盘
即输入 D: 这样就切换到D盘,然后输入 cd D:\Anaconda 这样系统就切换到Anaconda所在路径了。与此同时,你可以打开文件资源管理器发现在D:\Anaconda文件目录下有一个python.exe文件,于是在命令提示符中输入python ,若出现下列结果则Anaconda安装成功。
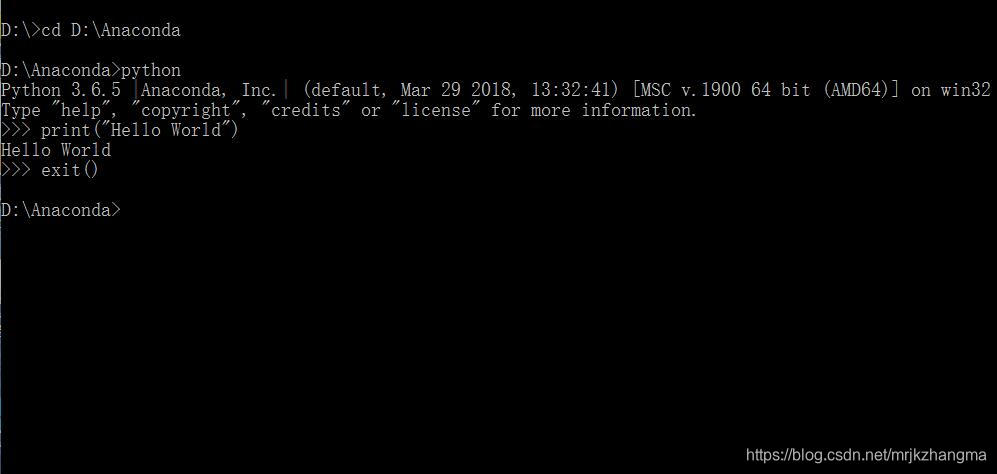
注意:以下所有操作采用的Anaconda所在路径都是在D盘,如果,你不是直接安装在D盘,下面的操作,自己根据所安装的Anaconda所在路径进行相应的改动
1.2 请求库的安装
爬虫过程具体可分为以下三步:抓取页面、分析页面和存储数据。
在抓取页面过程中,我们需要模拟浏览器向服务器发出请求,所以需要用到一些Python库来实现HTTP请求操作。下面,我将介绍一些请求库的安装方法:
1.2.1 requests的安装
requests库的相关链接:
requests属于第三方库,需要我们手动安装。根据我们上一步所示,我们在Window中已经安装好了Anaconda,下面我们便利用Anaconda中的pip 这个包管理工具来进行安装。
我们打开文件资源管理器切换到D:\Anaconda\Scripts路径下,会发现这里有个pip.exe文件。下面我们利用pip 对requests库进行安装
首先在“开始”菜单中点击鼠标右键,在弹出的对话框中选择“命令提示符”,然后将系统目录转换到Anaconda所在的系统盘下,这里,然后使用 cd D:\Anaconda\Scripts 这样便切换到pip所在路径了,后面直接使用
pip install requests
便可完成requests库的安装
你可以使用 pip list查看是否安装成功
1.2.2 Selenium的安装
Selenium是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等操作。对于一些使用JavaScript渲染的页面来说,这种抓取方式十分有效,下面我们来看看Selenium的安装过程。
相关链接:
- 官方文档:http://selenium-python.readthedocs.io
- GitHub:https://github.com/SeleniumHQ/selenium/tree/master/py
简单安装,可以采取跟上面requests库一样的方式使用pip安装
pip install selenium
1.3 解析库的安装
抓取网页代码之后,下一步就是从网页中提取信息。这里我们使用几个常用的解析库来高效便捷的从网页中提取有效信息。
1.3.1 lxml的安装
lxml是Python的一个解析库,支持HTML和XML的解析,支持XPath结息方式,而且解析效率非常高。
相关链接:
- 官方网站:http://lxml.de
- GitHub:https://github.com/lxml/lxml
- PyPI:https://pypi.python.org/pypi/lxml
使用pip安装
pip install lxml
如果出现报错,比如提示缺少libxml2库等信息,可以采用wheel方式安装。
从链接:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
下载对应的wheel文件,根据自己所下载的Python版本选择对应的lxml版本,下载到pip所在文件路径,假设选择的wheel文件为:lxml-3.8.0-cp36-cp36m-win_amd64.whl
然后利用pip install lxml-3.8.0-cp36-cp36m-win_amd64.whl即可完成安装
1.3.2 Beautiful Soup 的安装
Beautiful Soup是Python的一个HTML或XML解析库,我们可以利用它来方便的从网页中提取数据。
相关链接
官方文档:https://www.crummy.com/soware/BeautifulSoup/bs4/doc
Beautiful Soup 的HTML和XML解析库是依赖与lxml的,所以需在安装Beautiful Soup 前安装好lxml
- pip 安装命令如下:
pip install beautifulsoup4
- wheel安装
链接如下:https://pypi.python.org/pypi/beautifulsoup4
然后使用pip 安装wheel文件即可
安装完成后,代码验证:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>','lxml')
print(soup.p.string
运行结果如下:
Hello