经典的RNN结构:
由图可得,一输入一输出,因此成为输入序列和输出序列具有相同的时间长度
2)我们为其加上时序性
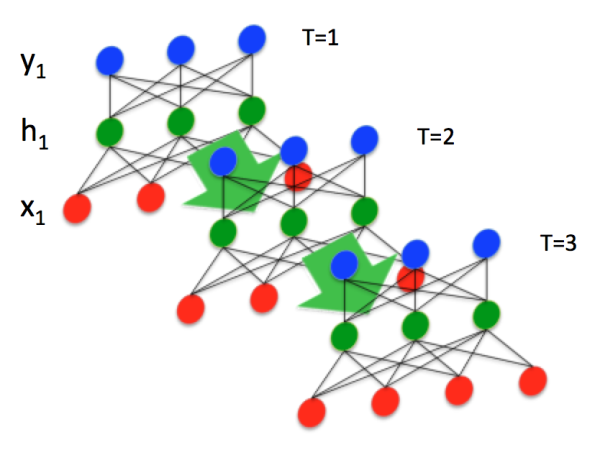
将时间信息作为一个坐标信息加入,

则展开,我们可得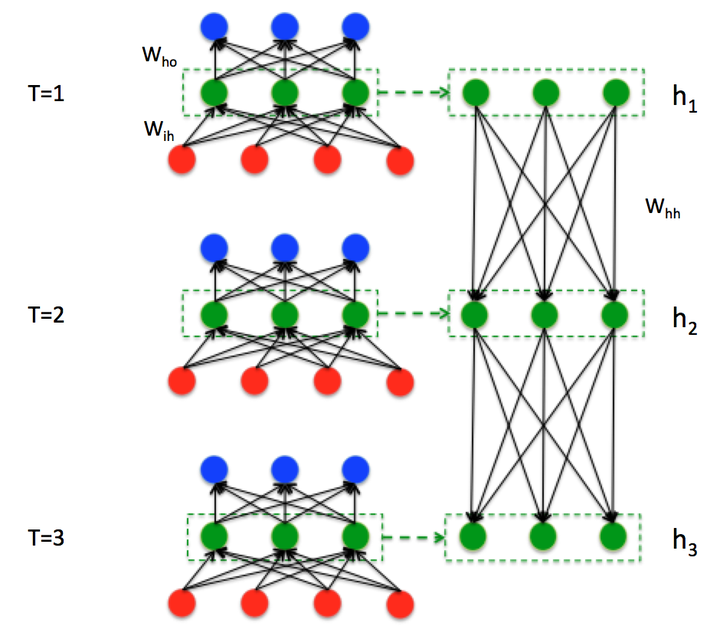
RNN中的“权值共享”:任意时刻 ,所有的权值(包括
,
,
,
,
,
)都相等
3)Sequence to Sequence模型
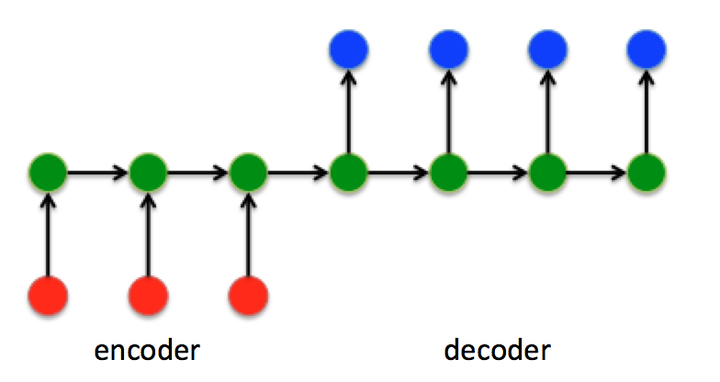
本质:是一个encoder和decoder的过程,不断地将前一个时刻 的输出作为后一个时刻
的输入
encode端:编码器encoder把所有的输入序列都编码成一个统一的语义向量context(不断地将前一个时刻 的输出作为后一个时刻
的输入)
例如: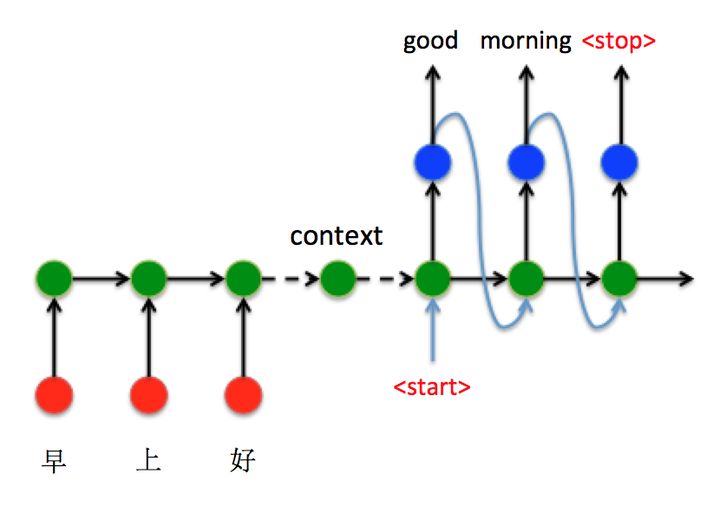
与RNN的区别:Seq2Seq结构不再要求输入和输出序列有相同的时间长度!
decode端:

由上图可得,输入![]() 经过RNN,最后经过sigmoid 或 argmax获得其当前标签(index),经过int2str后将其输出的字符作为输入送入第二时间序列(下一状态)
经过RNN,最后经过sigmoid 或 argmax获得其当前标签(index),经过int2str后将其输出的字符作为输入送入第二时间序列(下一状态)
4)Attention注意力机制
解决问题:1)当输入信息过大时(句子过长),一个context存储不下,会造成精度下降
2)每次只用到编码器最后一个隐藏层状态,信息利用率很低
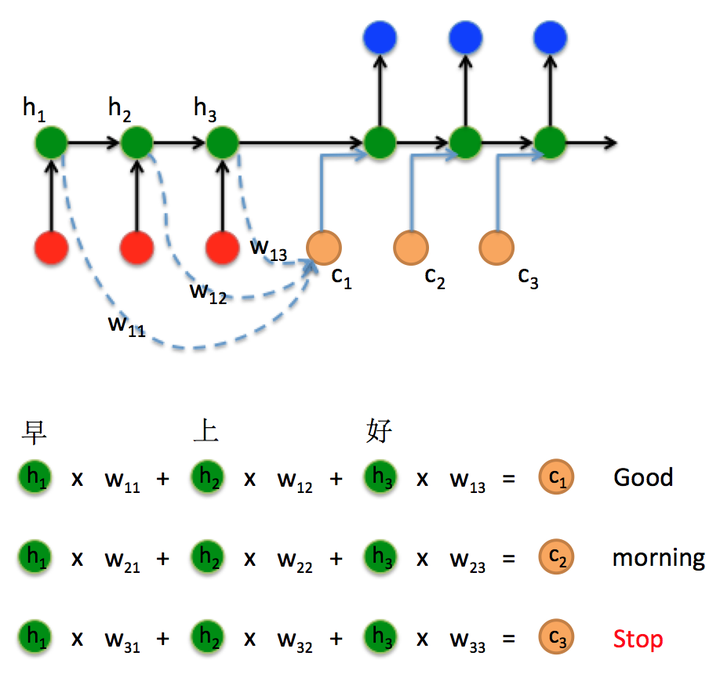
1)encoder把所有的输入序列都编码成一个统一的语义向量context,其中encoder的隐藏层状态 代表对不同时刻输入
的编码结果,会使得context装不下,因此这里引用了多次分别输入(类似于多特征图融合FPN)
细节如下:
祝好~!