问题:你想匹配或者搜索特定模式的文本
#2.4字符串匹配和搜索
#可以用来匹配或者搜索特定模式文本。若想匹配只是字面字符串,那么通常只需要调用基本字符串方法就行,比如str.find(),
#str.endswith(),str.startswith()或者类似方法
text = 'yeah, but no, but yeah, but no, but yeah'
print(text=='yeah')
print(text.startswith('yeah'))
print(text.endswith('no'))
print(text.find('no'))
#对于复杂的匹配需要使用正则表达式和re模块。为解释正则表达式基本原理,假设你想匹配数字格式的日期字符串比如11/27/2012,可以这样
text1 = '11/27/2012'
text2 = 'Nov 20, 2012'
import re
if re.match(r'\d+/\d+/\d+',text1):
print('yes')
else :
print('no')
if re.match(r'\d+/\d+/\d+',text2):
print('yes')
else :
print('no')![]()
#若想使用同一个模式去做多次匹配,应该先将模式字符串预编译为模式对象
datepat = re.compile(r'\d+/\d+/\d+')#先将模式字符串预编译为模式对象
if datepat.match(text1):
print('yes')
else :
print('no')
if datepat.match(text2):
print('yes')
else :
print('no')
#match总是从字符串开始去匹配,如果想查找字符串任意部分的模式出现位置,使用findall()方法去代替
text = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
print(datepat.findall(text))![]()
#在定义正则式的时候,通常会利用括号去捕获分组,比如:
datepat = re.compile(r'(\d+)/(\d+)/(\d+)')
#捕获分组可以使得后面的处理更加简单,因为可以分别将每个组的内容提取出来
m = datepat.match('11/27/2012')
print(m)
print(m.group(0))
print(m.group(1))
print(m.group(2))
print(m.group(3))
print(m.groups())
month,day,year = m.groups()
print(month,day,year)
print(text)
print(datepat.findall(text))
for month,day,year in datepat.findall(text): #利用正则找出所有分组
print('{}-{}-{}'.format(year,month,day))
#findall()方法会搜索文本并以列表形式返回所有的匹配。如果你想以迭代的方式返回匹配,可以使用
#finditer()方法来代替
for m in datepat.finditer(text):
print(m.groups())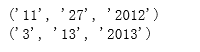
#这一节阐述了使用re模块进行匹配和搜索文本的最基本方法。核心步骤就是先用re.conpile()编译正则表达式你,然后使用
#match(),findall(),finditer()等方法
#当写正则式字符串的时候,相对普遍的做法是使用原始字符串比如r'(\d+)/(\d+)/(\d+)'。这种字符串将不去解析
#反斜杠,这在正则表达式很有用,若不这样,必须使用两个反斜杠,类似'(\\d+)/(\\d+)/(\\d+)'
#要注意的是match()方法仅仅检查字符串的开头部分,他的匹配结果可能并不是期望的样子
m=datepat.match('11/27/2012abcdef')
print(m.group())![]()
#如果你想精准匹配,确保你的正则表达式以$结尾,比如
datepat = re.compile(r'(\d+)/(\d+)/(\d+)$')
print(datepat.match('11/27/2012abcs')) #有了结束符这个后面你的字符就匹配不上了
print(datepat.match('11/27/2012'))
#若仅仅是做一次简单地文本匹配/搜索,可以略过编译,直接使用re模块级别的函数。
print(re.findall(r'(\d+)/(\d+)/(\d+)',text))
#注意:若打算做大量的匹配和搜索操作,最好先编译正则表达式,后重复使用它。模块级别的函数会将最近编译过的模式缓存起来,因此并不会消耗太多
#的性能,但是如果使用预编译模式的话,会减少查找和一些额外的处理损耗![]()