-
随着之前我们学习的多线程和多进程,但是我们知道无论是创建多进程还是创建多线程来解决问题,都要消耗一定的时间来创建进程、创建线程、以及管理他们之间的切换。随着我们对于效率的追求不断提高,基于单线程来实现并发又成为一个新的课题,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发。这样就可以节省创建线进程所消耗的时间。为此我们需要先回顾下并发的本质:切换+保存状态,cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制):
- 一种情况是该任务发生了阻塞
- 一种情况是该任务计算的时间过长

在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态 。
一:其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。
为此我们可以基于yield来验证。yield本身(tonodo最初版本就是yield实现)就是一种在单线程下可以保存任务运行状态的方法,我们来简单复习一下:
x#1 yiled可以保存状态,yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级#2 send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换#串行执行import timedef consumer(res):'''任务1:接收数据,处理数据'''passdef producer():'''任务2:生产数据'''res=[]for i in range(10000000):res.append(i)return resstart=time.time()#串行执行res=producer()consumer(res) #写成consumer(producer())会降低执行效率stop=time.time()print(stop-start) #1.5536692142486572#基于yield并发执行import timedef consumer():'''任务1:接收数据,处理数据'''while True:x=yielddef producer():'''任务2:生产数据'''g=consumer()next(g)for i in range(10000000):g.send(i)start=time.time()#基于yield保存状态,实现两个任务直接来回切换,即并发的效果#PS:如果每个任务中都加上打印,那么明显地看到两个任务的打印是你一次我一次,即并发执行的.producer()stop=time.time()print(stop-start) #2.0272178649902344二:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
xxxxxxxxxximport timedef consumer():'''任务1:接收数据,处理数据'''while True:x=yielddef producer():'''任务2:生产数据'''g=consumer()next(g)for i in range(10000000):g.send(i)time.sleep(2)start=time.time()producer() #并发执行,但是任务producer遇到io就会阻塞住,并不会切到该线程内的其他任务去执行stop=time.time()print(stop-star)#对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到io阻塞时就切换到另外一个任务去计算,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而更多的将cpu的执行权限分配给我们的线程。 -
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
xxxxxxxxxx#1. 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。#2. 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
-
xxxxxxxxxx1、协程(本质是一条线程,操作系统不可见)2、是有程序员操作的,而不是由操作系统调度的3、多个协程的本质是一条线程,所以多个协程不能利用多核# 出现的意义 : 多个任务中的IO时间可以共享,当执行一个任务遇到IO操作的时候,# 可以将程序切换到另一个任务中继续执行# 在有限的线程中,实现任务的并发,节省了调用操作系统创建\销毁线程的时间# 并且协程的切换效率比线程的切换效率要高# 协程执行多个任务能够让线程少陷入阻塞,让线程看起来很忙# 线程陷入阻塞的次数越少,那么能够抢占CPU资源就越多,你的程序效率看起来就越高总结:# 1.开销变小了# 2.效率变高了
-
一、协程
- 协程并不是实际存在的实体,它的本质就是一个线程的多个部分,比线程的单位更小————协程、纤程,一个线程中可以开启多个协程,在执行程序的过程中遇到IO操作就冻结当前位置的状态,去执行其他任务,在执行其他任务过程中会不断的检测上一个冻结的任务是否IO结束,如果IO结束了,就继续从冻结的位置开始执行,
- 协程的特点:冻结当前程序/任务的执行状态————技能解锁可以规避IO操作的时间
- 单纯的切换 还是要耗费一些时间的 记住当前执行的状态,但是节省内存
xxxxxxxxxx
#冻结状态之生成器
def func():
print(1)
yield 'aaa'
print(2)
yield 'bbb'
print(3)
yield 'ccc'
g = func()
next(g) #1
#列表
def func():
x = yield 1
print(x)
yield 2
g = func()
print(next(g))
print(g.send('aaa'))
#1
#aaa
#2
-
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
-
需要强调的是:
xxxxxxxxxx#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)#2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关) -
对比操作系统控制线程的切换,用户在单线程内控制协程的切换:
xxxxxxxxxx优点:#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级#2. 单线程内就可以实现并发的效果,最大限度地利用cpu缺点:#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线 程内开启协程#2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程总结协程特点:1、必须在只有一个单线程里实现并发2、修改共享数据不需加锁3、用户程序里自己保存多个控制流的上下文栈4、附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
-
二、greenlet模块
-
简介:
Greenlet是python的一个C扩展,来源于Stackless python,旨在提供可自行调度的‘微线程’, 即协程。generator实现的协程在yield value时只能将value返回给调用者(caller)。 而在greenlet中,target.switch(value)可以切换到指定的协程(target), 然后yield value。greenlet用switch来表示协程的切换,从一个协程切换到另一个协程需要显式指定。
-
greenlet 实现状态切换
xxxxxxxxxxfrom greenlet import greenletdef eat(name):print('%s eat 1' %name)g2.switch('egon')print('%s eat 2' %name)g2.switch()def play(name):print('%s play 1' %name)g1.switch()print('%s play 2' %name)g1=greenlet(eat)g2=greenlet(play)g1.switch('egon')#可以在第一次switch时传入参数,以后都不需要 -
单纯的切换(在没有io的情况下或则没有重复开辟内存空间的操作),反而会降低程序的执行速度
#顺序执行 import time def f1(): res=1 for i in range(100000000): res+=i def f2(): res=1 for i in range(100000000): res*=i start=time.time() f1() f2() stop=time.time() print('run time is %s' %(stop-start)) #10.985628366470337 #切换 from greenlet import greenlet import time def f1(): res=1 for i in range(100000000): res+=i g2.switch() def f2(): res=1 for i in range(100000000): res*=i g1.switch() start=time.time() g1=greenlet(f1) g2=greenlet(f2) g1.switch() stop=time.time() print('run time is %s' %(stop-start)) # 52.763017892837524 #greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。 #单线程里的这20个任务的代码通常会既有计算操作又有阻塞操作,我们完全可以在执行任务1时遇到阻塞,就利用阻塞的时间去执行任务2。。。。如此,才能提高效率,这就用到了Gevent模块 -
greenlet不是创造协程的模块,它是用来做多个协程任务切换的,它到底是怎么实现切换的呢?
from greenlet import greenlet def func(): print(123) def func2(): print(456) g1 = greenlet(func) # 实例化 g2 = greenlet(func2) g1.switch() # 开始运行,它会运行到下一个switch结束。否则一直运行 结果:123 #复杂点的交叉切换 from greenlet import greenlet def test1(): print 12 gr2.switch() #可以把switch理解为水龙头的开关,g2开 print 34 def test2(): print 56 gr1.switch() #g1开 print 78 gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch() #执行结果 #12 #56 #34 #当创建一个greenlet时,首先初始化一个空的栈, switch到这个栈的时候,会运行在greenlet构造时传入的函数(首先在test1中打印 12), 如果在这个函数(test1)中switch到其他协程(到了test2 打印34),那么该协程会被挂起,等到切换回来(在test2中切换回来 打印34)。当这个协程对应函数执行完毕,那么这个协程就变成dead状态。 #注意:上面没有打印test2的最后一行输出 78,因为在test2中切换到gr1之后挂起,但是没有地方再切换回来。这个可能造成泄漏,后面细说 -
greenlet的缺点:1.手动切换;2.不能规避I/O操作(睡眠)
三、gevent模块
-
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
-
用法介绍
g1=gevent.spawn(func,1,,2,3,x=4,y=5) #创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的 g2=gevent.spawn(func2) g1.join() #等待g1结束 g2.join() #等待g2结束 #或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value #拿到func1的返回值
-
gevent遇到io主动切换
from gevent import monkey;monkey.patch_all() #这里的猴子是可以抓取下面的所有阻塞,如time import threading import gevent import time def eat(): print(threading.current_thread().getName()) print('eat food 1') time.sleep(2) #遇到io主动切换到play print('eat food 2') def play(): print(threading.current_thread().getName()) print('play 1') time.sleep(1) print('play 2') g1=gevent.spawn(eat) g2=gevent.spawn(play) gevent.joinall([g1,g2]) print('主') #结果 DummyThread-1 #dummy 假的;仿制品,所以可以知道是假进程 eat food 1 DummyThread-2 play 1 play 2 eat food 2 主 -
详细解读gevent
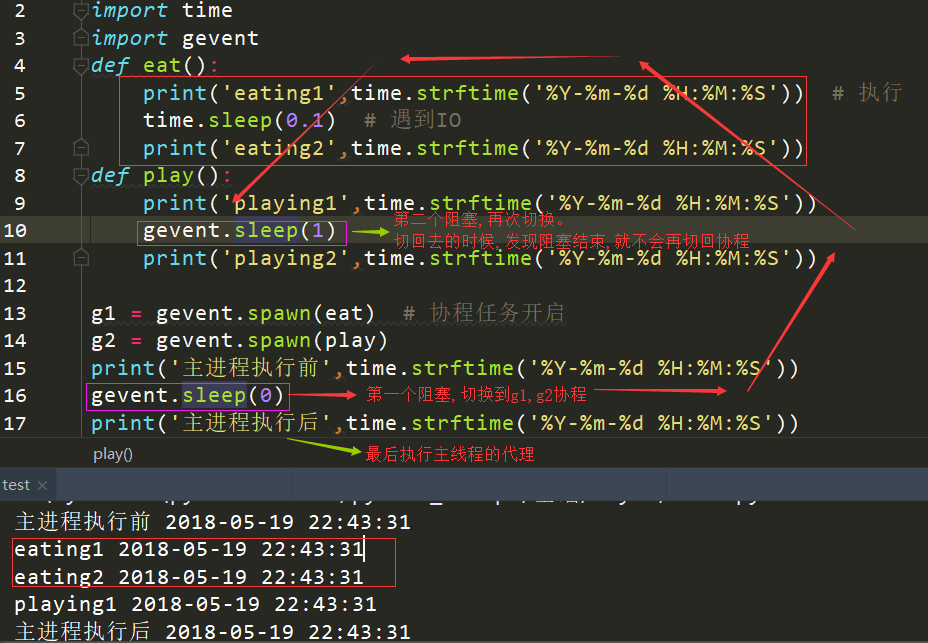
import gevent def eat(): print('eating1') print('eating2') g1 = gevent.spawn(eat) #创建一个协程对象g1 #结果:为空,不会执行,因为没有遇到阻塞 import gevent def eat(): print('eating1') print('eating2') g1 = gevent.spawn(eat) #创建一个协程对象g1 g1.join() #等待g1结束 #结果:eating1 eating2 #当使用time时,gevent并抓不到这个阻塞 import time import gevent def eat(): print('eating1') time.sleep(1) print('eating2') def play(): print('playing1') time.sleep(1) print('playing2') g1 = gevent.spawn(eat) #创建一个协程对象g1 g2 = gevent.spawn(play) g1.join() #等待g1结束 g2.join() #执行输出: #eating1 #eating2 #playing1 #playing2 #使用gevent的阻塞的time才能抓取 import time import gevent def eat(): print('eating1') gevent.sleep(1) #延时调用 print('eating2') def play(): print('playing1') gevent.sleep(1) #延时调用 print('playing2') g1 = gevent.spawn(eat) #创建一个协程对象g1 g2 = gevent.spawn(play) g1.join() #等待g1结束 g2.join() #执行输出: eating1 playing1 eating2 playing2 -
猴子补丁
如果想让协程执行time.sleep()呢?由于默认,协程无法识别time.sleep()方法,需要导入一个模块monkey monkey patch (猴子补丁) from gevent import monkey;monkey.patch_all() # 它会把下面导入的所有的模块中的IO操作都打成一个包,gevent就能够认识这些IO了 import time import gevent def eat(): print('eating1') time.sleep(1) #延时调用 print('eating2') def play(): print('playing1') time.sleep(1) #延时调用 print('playing2') g1 = gevent.spawn(eat) #创建一个协程对象g1 g2 = gevent.spawn(play) g1.join() #等待g1结束 g2.join() #执行输出: #playing1 #eating2 #eating2 #playing2 -
结论:
- 使用gevent模块来执行多个函数,表示在这些函数遇到IO操作的时候可以在同一个线程中进行切换 利用其他任务的IO阻塞时间来切换到其他的任务继续执行
- spawn来发布协程任务join负责开启并等待任务执行结束 gevent本身不认识其他模块中的IO操作,但是如果我们在导入其他模块之前执行from gevent import monkey;monkey.patch_all() 这行代码,必须在文件最开头gevent就能够认识在这句话之后导入的模块中的所有IO操作了
-
-
Gevent的同步与异步
from gevent import spawn,joinall,monkey;monkey.patch_all() import time def task(pid): time.sleep(0.5) print('Task %s done' % pid) def synchronous(): # 同步 for i in range(10): task(i) def asynchronous(): # 异步 g_l=[spawn(task,i) for i in range(10)] joinall(g_l) print('DONE') if __name__ == '__main__': print('Synchronous:') synchronous() #前者打印完,才执行后面 print('Asynchronous:') asynchronous() # 上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 # 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数, # 后者阻塞当前流程,并执行所有给定的greenlet任务。执行流程只会在 所有greenlet执行完后才会继续向下走。 -
Gevent的应用举例
#爬虫 url_dic = { '协程':'http://www.cnblogs.com/Eva-J/articles/8324673.html', '线程':'http://www.cnblogs.com/Eva-J/articles/8306047.html', '目录':'https://www.cnblogs.com/Eva-J/p/7277026.html', '百度':'http://www.baidu.com', 'sogou':'http://www.sogou.com', '4399':'http://www.4399.com', '豆瓣':'http://www.douban.com', 'sina':'http://www.sina.com.cn', '淘宝':'http://www.taobao.com', 'JD':'http://www.JD.com' } import time from gevent import monkey;monkey.patch_all() from urllib.request import urlopen import gevent def get_html(name,url): ret = urlopen(url) content = ret.read() with open(name,'wb') as f: f.write(content) start = time.time() for name in url_dic: get_html(name+'_sync.html',url_dic[name]) ret = time.time() - start print('同步时间 :',ret) start = time.time() g_l = [] for name in url_dic: g = gevent.spawn(get_html,name+'_async.html',url_dic[name]) g_l.append(g) gevent.joinall(g_l) ret = time.time() - start print('异步时间 :',ret) #同步时间 : 5.821720123291016 #异步时间 : 4.347508907318115 #聊天工具 #服务端 from gevent import monkey;monkey.patch_all() import socket import gevent def async_talk(conn): try: while True: conn.send(b'hello') ret = conn.recv(1024) print(ret) finally: conn.close() sk = socket.socket() sk.bind(('127.0.0.1',9000)) sk.listen() while True: conn,addr = sk.accept() gevent.spawn(async_talk,conn) sk.close() #客服端 import socket from threading import Thread def socket_client(): sk = socket.socket() sk.connect(('127.0.0.1',9000)) while True: print(sk.recv(1024)) sk.send(b'bye') sk.close() for i in range(500): Thread(target=socket_client).start()
四、生成器————>asyncio模块 asyncio学习