版权声明:本文为博主高远原创文章,转载请注明出处:http://blog.csdn.net/wgyscsf https://blog.csdn.net/wgyscsf/article/details/51706298
概述
- 易生活的搜索业务主要是为了完成用户对商品、商家的搜索。搜索途径主要包括包括:语音识别搜索、文字搜索、历史搜索组成。使用到的第三方技术主要包括:科大讯飞的语音识别系统、哈工大的中文分词系统等。搜索结果会以列表的形式进行展示,用户可以点击进入详情页,进行浏览和购买。
效果图
业务流程图
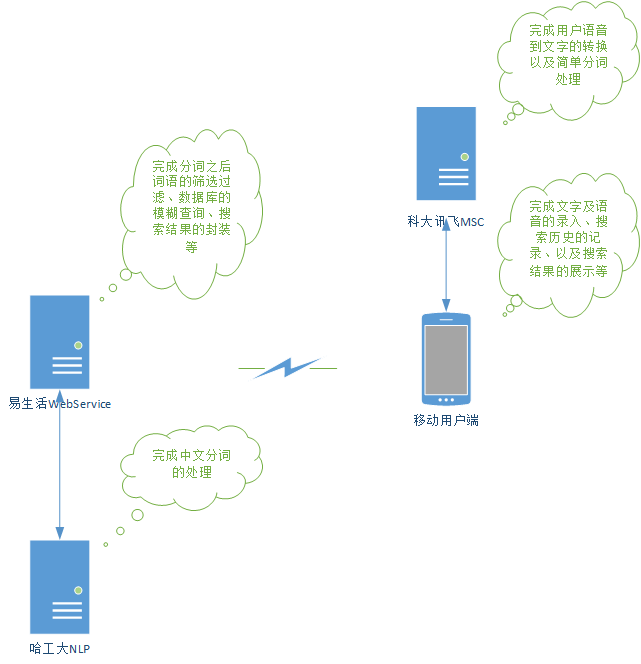
业务逻辑处理
- 由上图我们可以看到在客户端主要完成了用户指令的获取、历史信息的保存以及获取搜索之后信息的展示等。服务端完成了对中文分词的处理、用户指令信息的过滤处理、数据库的模糊查询以及信息的封装返回等。
- 客户端:
- 布局分为上中下三部分:上面包括搜索栏、中间包括历史记录列表、底部包括一个语音按钮。* 历史记录的实现主要用到了SharedPreferences+json进行数据的记录存储,特别注意历史记录是按照由新到旧的顺序进行排布的。
- 另外,当历史记录为空或者被清除之后,需要隐藏listview的头部和尾部,提高用户体验。* * 在记录历史记录的逻辑上,有两部分,包括:语音搜索的结果、输入搜索框的文字,不包括点击历史记录!
- 在搜索结果跳转上,包括三部分:文本框输入、语音输入、历史记录。
- 在搜索结果获取上,是在搜索页面获取之后,才跳转到搜索结果页面。
- 注意:该处不能做网络缓存处理!
- 服务端:
- 服务端首先会获取客户端请求的信息,客户端请求的信息是用户根据自己的想法输入的,具有随 性、不确定性。比如:“我想吃黄焖鸡。”。
- 这个时候,服务器会立刻把获取的信息去哈工大的中分分词系统中进行中文分词处理,然后获取其中的名词(因为搜索,我们只需要名词),这个时候我们会取到“黄焖鸡”这个名词,对于“我想吃”进行过滤处理;如果有多个名词,比如“黄焖鸡”、“老干妈”、“老干爹”,易生活服务器会进行拼接处理:“黄焖鸡,老干妈,老干爹”。
- 然后,易生活服务器会拿这些词去服务器进行模糊查询。
- 将获取到的商品信息装入到商品集合进行返回。
搜索粒度的处理
- 对于不做任何中文分词处理的搜索,我们可能这样去搜索:当我去搜索“我想吃黄焖鸡。”,数据库会这样去模糊查询:“%我%”||“%想%”….。这样也可以会把“黄焖鸡”查询出来,以及相关的“鸡”全部查询出来。但是,另外一方面,由于多个文字的无用匹配,比如“我想吃”,全部属于无用信息,在一定程度上增加了数据库的查询压力。并且,会查询出许多用户不需要的信息,比如所有“鸡”都会被查询出来。这个明显是用户不想要的。
- 对于做了中文分词处理的操作,优点是明显的。另外一方面,查询过于精细,对于上面的例子,我只能查询到“黄焖鸡”,如果想看“鸡公煲”,就没有进行显示。但是,明显的,我们已经过滤掉了“我想吃”这些明显无用的信息。如果,我们现在对分词之后的信息再进行模糊查询呢?比如“黄焖鸡”拆分成:“%黄%”||“%焖%”||“%鸡%”去查询。这样,就可以查询到用户可能想要的“鸡公煲”。
- 在我们项目中,并没有再去对分词之后的信息进行拆分模糊查询。这个搜索的粒度比较难以控制,如何确定是否再去进行分词之后信息的拆分处理,需要看业务需求。
存在的问题
- 客户端没有对搜索之后的信息进行筛选处理,比如:按照销量排序、按照好评排序等。这一块,淘宝已经做的很好。
- 在web端没有进行分页处理,这个明显是一个隐患。如果有大量搜索结果,服务器会有很大压力,对于客户端也很危险。
- 对于搜索粒度的控制也是存在的一个问题。
- 搜索结果精度的排序问题。