Node.js 中 有两种频率很高的操作:文件,网络。这两种操作,有一个共同点,都需要处理二进制数据。Node.js 中的Buffer API,就是处理二进制数据的。由于它使用的频率很高,因此它被挂到了 global 对象上。这样我们就不需要require 就可以直接用了。
关于 Buffer 有以下几点:
- Buffer 用于处理二进制数据流
- 实例类似整数数组,数组的大小固定
- C++ 代码在 V8 堆外分配物理内存 (Buffer 的内存不是V8 分配的,它是C++ 代码在V8 对外分配的物理内存)
这是 Buffer 的文档 http://nodejs.cn/api/buffer.html
下面我们来使用一下 Buffer 中的方法。
我们来申请一块放 Buffer 数据的内存。实例化Buffer。用下面的方法。
// 创建一个长度为10,0填充的Buffer
const buf1 = Buffer.alloc(10);
// 创建一个长度为10,0x1填充的Buffer
const buf2 = Buffer.alloc(10,1);
// 创建一个包含[0x1,0x2,0x3]填充的Buffer
const buf3 = Buffer.from([1,2,3]);
// 创建一个包含utf-8字节的Buffer
const buf4 = Buffer.from("test");
console.log(buf1);
console.log(buf2);
console.log(buf3);
console.log(buf4);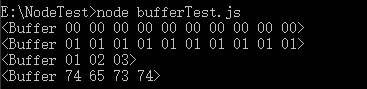
接下来,我们来看看Buffer 里面常用的属性和方法。
首先,静态的方法:Buffer.byteLength() , Buffer.isBuffer(), Buffer.concat()
Buffer.byteLength 返回的是一个字符串实际占了几个字节【可见,JS中中文字符是占3个字节大小的】
console.log(Buffer.byteLength("test"));
console.log(Buffer.byteLength("测试"));
Buffer.isBuffer 就是返回参数是否是Buffer 对象
console.log(Buffer.isBuffer({}));
console.log(Buffer.isBuffer(Buffer.alloc(5)));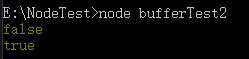
Buffer.concat 就是 buffer 的合并
const buf1 = Buffer.from("This");
const buf2 = Buffer.from("is");
const buf3 = Buffer.from("buffer");
const buf4 = Buffer.from(".");
const buf = Buffer.concat([buf1,buf2,buf3,buf4]);
console.log(buf.toString());![]()
下面,我们再看看 Buffer 实例的属性与方法:buf.length, buf.toString(), buf.fill(), buf.equals(), buf.indexOf(), buf.copy()
首先,前面两个buf.length , buf.toString()
const buf = Buffer.from("This is a test.");
console.log(buf.length);
console.log(buf.toString());
下面我们看看 buf.fill , 它是用来填充数据的。当我们使用allocUnsafe 创建Buffer 对象时,就需要 fill 来填充数据。
// 并不会初始化,Buffer对象的内容是不能确定的
const buf = Buffer.allocUnsafe(10);
console.log(buf);![]()
// 并不会初始化,Buffer对象的内容是不能确定的
const buf = Buffer.allocUnsafe(10);
console.log(buf);
console.log(buf.fill(10,2,6));
下面,是 buf.equals() 它比较两个buffer 内容是否一致
const buf1 = Buffer.from("test");
const buf2 = Buffer.from("test");
const buf3 = Buffer.from("test!");
console.log(buf1.equals(buf2));
console.log(buf1.equals(buf3));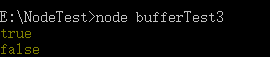
下面 buf.indexOf()
const buf1 = Buffer.from("test");
console.log(buf1.indexOf("st"));
console.log(buf1.indexOf("sa"));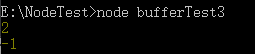
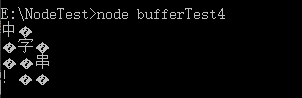
在JS 中中文字符占3个字节,在日常处理中肯会遇到中文乱码问题。比如这样的一个中文乱码:
const buf = Buffer.from("中文字符串!");
// console.log(buf.toString());
for (let i = 0; i < buf.length; i += 5) {
const b = Buffer.allocUnsafe(5);
buf.copy(b,0,i);
console.log(b.toString());
}
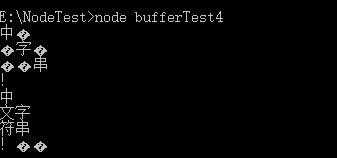
这种情况下,我们可以借助string_decoder。string_decoder是node.js 内置的模块。(decoder 能在不能解析的时候,把数据进行缓存,下次解析的时候能把缓存的数据先拿来用上)
const StringDecoder = require("string_decoder").StringDecoder;
const decoder = new StringDecoder("utf8")
const buf = Buffer.from("中文字符串!");
// console.log(buf.toString());
for (let i = 0; i < buf.length; i += 5) {
const b = Buffer.allocUnsafe(5);
buf.copy(b,0,i);
console.log(b.toString());
}
for (let i = 0; i < buf.length; i += 5) {
const b = Buffer.allocUnsafe(5);
buf.copy(b,0,i);
console.log(decoder.write(b));
}
最后 buf.copy() :