Spire.PDF是一个专业的PDF组件,能够独立地创建、编写、编辑、操作和阅读PDF文件,支持 .NET、Java、WPF和Silverlight。
文本和图片是PDF文档的重要组成部分。本文将介绍如何通过编程的方式使用Spire.PDF C#获取PDF文档中的文本和图片并保存到本地路径。
提取PDF文档中的文本
//实例化一个PdfDocument对象
PdfDocument doc = new PdfDocument();
//加载PDF文档
doc.LoadFromFile("测试文档.pdf");
//实例化一个StringBuilder 对象
StringBuilder content = new StringBuilder();
//提取PDF所有页面的文本
foreach (PdfPageBase page in doc.Pages)
{
content.Append(page.ExtractText());
}
//将提取到的文本写为.txt格式并保存到本地路径
String fileName = "获取文本.txt";
File.WriteAllText(fileName, content.ToString());
提取 PDF 文档中的图片
//加载PDF文档
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("测试文档.pdf");
List<Image> ListImage = new List<Image>();
for (int i = 0; i < doc.Pages.Count; i++)
{
// 实例化一个Spire.Pdf.PdfPageBase对象
PdfPageBase page = doc.Pages[i];
// 获取所有pages里面的图片
Image[] images = page.ExtractImages();
if (images != null && images.Length > 0)
{
ListImage.AddRange(images);
}
}
// 将提取到的图片保存到本地路径
if (ListImage.Count > 0)
{
for (int i = 0; i < ListImage.Count; i++)
{
Image image = ListImage[i];
image.Save("image" + (i + 1).ToString() + ".png", System.Drawing.Imaging.ImageFormat.Png);
}
}
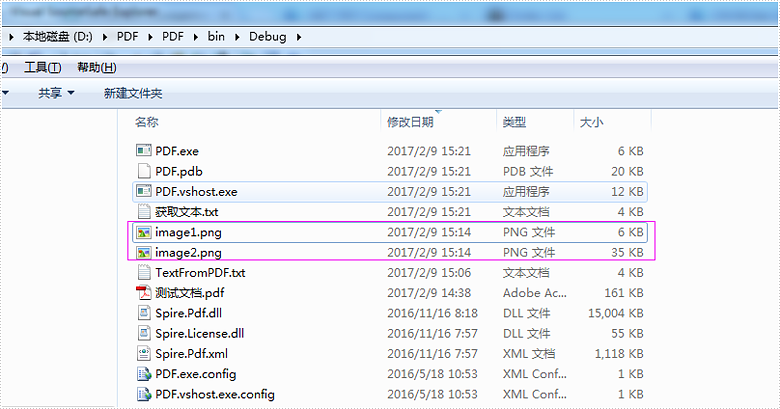
效果图:
查看冰蓝更多产品教程,为你推荐: