import nltk
defunusual_words(text):#输出不常见的词
text_vocab =set(w.lower()for w in text if w.isalpha())
english_vocab =set(w.lower()for w in nltk.corpus.words.words())
unusual = text_vocab.difference(english_vocab)#两者之间的差别词returnsorted(unusual)print(unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt')))
停用词,输出一个文本有意义的词汇占文章的百分比
from nltk.corpus import stopwords #停用词(自动忽略高频无意义的词汇)import nltk
stopwords.words('english')defcontent_fraction(text):#输出有意义词语占整个文本的百分比
stopwords = nltk.corpus.stopwords.words('english')
content =[w for w in text if w.lower()notin stopwords]#不是停用词的词语,即有意义的词print(content)returnlen(content)/len(text)print(content_fraction(nltk.corpus.reuters.words()))
import nltk #一个游戏,
puzzle_letters = nltk.FreqDist('egivrvonl')
obligatory ='r'
wordlist = nltk.corpus.words.words()print([w for w in wordlist iflen(w)>=6and obligatory in w
and nltk.FreqDist(w)<= puzzle_letters])#从此处限定了出现的字母和出现字母的数量
寻找男女姓名中重复的部分
import nltk
names = nltk.corpus.names #姓名的词汇表
names.fileids()
male_names = names.words('male.txt')#男性姓名
female_names = names.words('female.txt')#女性姓名print([w for w in male_names if w in female_names])#男女中通用的姓名-重复部分
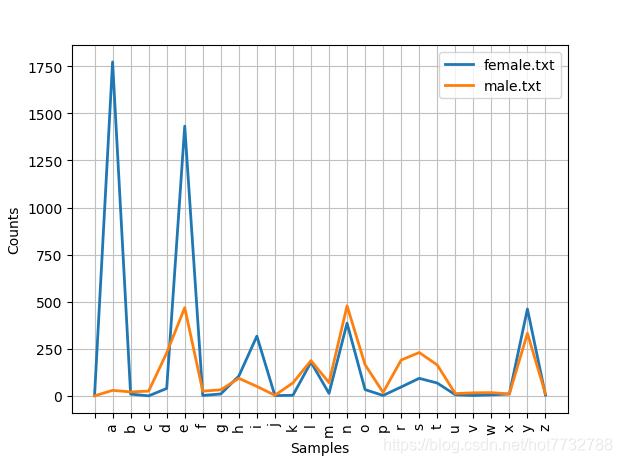
输出姓名末尾的字母在男女中的比例(即男女中以26个字母为姓名末尾的频数分布)
import nltk
names = nltk.corpus.names #姓名的词汇表
cfd = nltk.ConditionalFreqDist((fileid, name[-1])for fileid in names.fileids()#['female.txt', 'male.txt']for name in names.words(fileid))
cfd.plot()
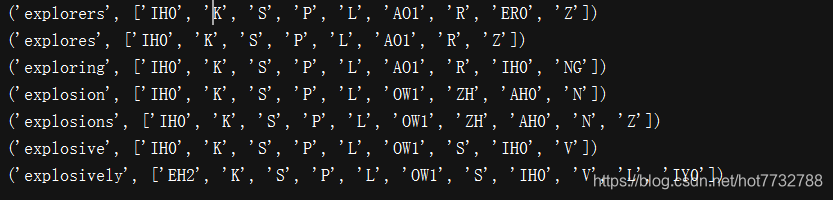
1.发音词典(并没有完全整理完整,当涉及到时在看)
import nltk
entries = nltk.corpus.cmudict.entries()print(len(entries))for entry in entries[39943:39951]:print(entry)#形成多个音束
找出三音节,并且第一个音节是P,第三个音节是T,的发音词典中的词
import nltk
entries = nltk.corpus.cmudict.entries()for word, pron in entries:iflen(pron)==3:
ph1, ph2, ph3 = pron
if ph1 =='P'and ph3 =='T':print(word, ph2)#输出单词,中间的音束,数字表示重音
输出以设定好音节为发音结尾的词(可用于其他部分,如果以单词为结尾的中文句子,稳)
import nltk
entries = nltk.corpus.cmudict.entries()
syllable =['N','IH0','K','S']print([word for word, pron in entries if pron[-4:]== syllable])
2.比较词典(相同单词在不同语言中的意思转换,未细看,请自行整理,此处仅作提醒)
from nltk.corpus import swadesh
print(swadesh.fileids())
3.词汇工具toolbox
from nltk.corpus import toolbox
print(toolbox.entries('rotokas.dic')[0])
4.woednet(同义词)
from nltk.corpus import wordnet as wn
print(wn.synsets('motorcar'))#搜索同义词集-[Synset('car.n.01')]-car这个单词的第一个意思print(wn.synset('car.n.01').lemma_names())#获得同类词print(wn.synset('car.n.01').definition())#获得意思的定义print(wn.synset('car.n.01').examples())#获得使用的例子from nltk.corpus import wordnet as wn
print(wn.synset('car.n.01').lemmas())#查找同义词条print(wn.lemma('car.n.01.automobile'))#查找某一特定的词条print(wn.lemma('car.n.01.automobile').synset())#某一词条的同义词集print(wn.lemma('car.n.01.automobile').name())#某一词条的名称for synset in wn.synsets('car'):#访问包含car的同义词条的同义词print(synset.lemma_names())
motorcar = wn.synset('car.n.01')
types_of_motorcar = motorcar.hyponyms()#访问下位词集sorted([lemma.name()for synset in types_of_motorcar for lemma in synset.lemmas()])#对下位词集进行排序
motorcar.hypernyms()#上位词