1.中文分词三大类
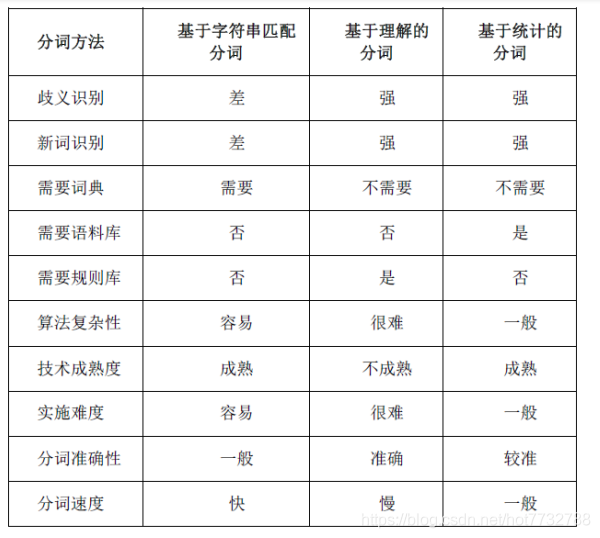
- 基于字典,词库进行匹配
- 正向最大匹配
- 逆向最大匹配
- 双向最大匹配
- 设立切分标志法
- 最佳匹配
- 基于词频度统计
- N-gram模型
- 隐马尔科夫模型
- 基于字标注的中文分词方法
- 基于知识理解
2.结巴分词


# # -*- coding: utf-8 -*-
#
#
# from __future__ import unicode_literals
# import sys
# sys.path.append("../")
import jieba
import jieba.posseg
import jieba.analyse
#分词
seg_list = jieba.cut("我来到北京清华大学",cut_all=True)
print("Full Mode:", "/ ".join(seg_list)) #全模式(可能存在的分词都给出)
seg_list = jieba.cut("我来到北京清华大学",cut_all=False)
print("Default Mode:", "/ ".join(seg_list)) #精确模式(仅输出概率最大的切分方法)
seg_list = jieba.cut("他来到了网易杭研大厦") #默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") #搜索引擎模式(细粒度的全模式)
print(", ".join(seg_list))
#添加词典
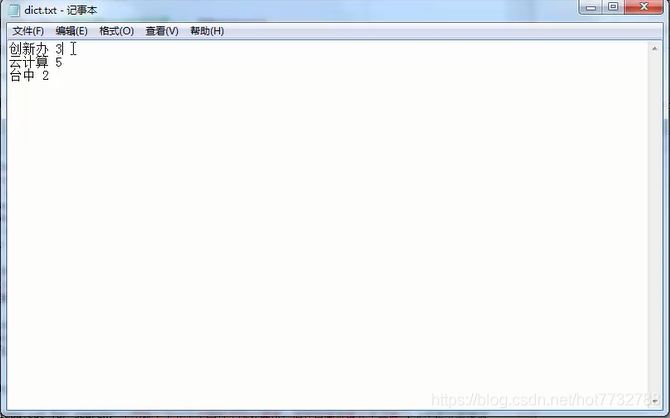
jieba.load_userdict("./dict.txt") #词语 词频 词性 顺序不可以颠倒(必须保存成utf-8的格式)(只管一次)
seg_list = jieba.cut("他是创新办主任,也是云计算方面的专家") #默认是精确模式
print(", ".join(seg_list))
#他, 是, 创新, 办, 主任, ,, 也, 是, 云, 计算, 方面, 的, 专家
#他, 是, 创新办, 主任, ,, 也, 是, 云计算, 方面, 的, 专家
# #调整词典
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
jieba.suggest_freq(('中', '将'), True) #调节单个词语的词频,使其人工设定社否可以被分出来
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
jieba.suggest_freq('台中', True)
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#关键词提取
s = '''
此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册
资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。
目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。
'''
for x, w in jieba.analyse.extract_tags(s, topK=20, withWeight=True):#自行设定提取多少个关键词
print('%s %s' % (x, w))#词语 权重值
#textrank
for x, w in jieba.analyse.textrank(s, withWeight=True):#另一种关键词提取算法,但同样适用
print('%s %s' % (x, w))
#词性标注
words = jieba.posseg.cut("我爱北京天安门")
for word, flag in words:#可以查看词性,前面有一篇博客将有一个api可以直接提取词性
print('%s %s' % (word, flag))
# #Tokenize
result = jieba.tokenize(u'永和服装饰品有限公司')#精确模式
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))#返回词语 + 起始位置
result = jieba.tokenize(u'永和服装饰品有限公司', mode='search')#搜索引擎模式
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
- 自创字典词语字典格式