1.下载数据
import urllib.request
import os #用于确认数据是否已经存在
url="http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"
filepath="data/titanic3.xls"
if not os.path.isfile(filepath):#判断文件存在就不会进行下载操作
result=urllib.request.urlretrieve(url,filepath)
print('downloaded:',result)
2.进行数据清洗
import numpy
import pandas as pd
#读入数据
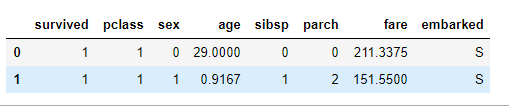
all_df = pd.read_excel(filepath)#使用pandas的api读入数据
#提取有用信息,去除无用信息
cols=['survived','name','pclass' ,'sex', 'age', 'sibsp',
'parch', 'fare', 'embarked'] #提取有用数据,去除无关数据
all_df=all_df[cols] #刷新数据dataframe
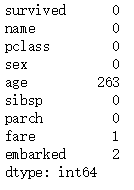
#判断有用数据中响应列为空的情况
print(all_df.isnull().sum())

#删除训练中不需要的姓名列
df=all_df.drop(['name'], axis=1) #训练时不需要姓名这种离散型较大的数据,所以进行删除
#填补数据的空缺
age_mean = df['age'].mean() #取现有年龄的平均值
df['age'] = df['age'].fillna(age_mean) #将平均值填补到空缺的age框中
fare_mean = df['fare'].mean() #提取费用的平均值
df['fare'] = df['fare'].fillna(fare_mean) #填补空缺
#将离散化数据可计算化
df['sex']= df['sex'].map({'female':0, 'male': 1}).astype(int) #将离散化的数据,对应为可以计算的数字

#进行一位有效编码转换,将不同分类分开形成类似one-hot的作用的数据
x_OneHot_df = pd.get_dummies(data=df,columns=["embarked" ])#进行一位有效编码转换

3.将DataFrame转化为Array
- 因为后续深度学习训练的格式必须为Array
#转化为Array
ndarray = x_OneHot_df.values #转化为一维,只取内部的值
#提取标签值和特征值
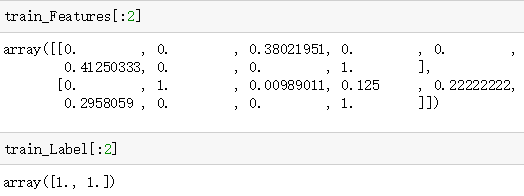
Label = ndarray[:,0]
Features = ndarray[:,1:]
4.对已经处理好的数据进行标准化,提高训练准确度
from sklearn import preprocessing
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0, 1)) #设置标准化后的取值范围(建立对象)
scaledFeatures=minmax_scale.fit_transform(Features) #进行标准化处理

5.训练集和测试集的划分
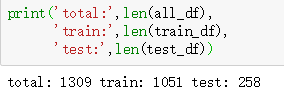
msk = numpy.random.rand(len(all_df)) < 0.8 #按照8:2的比例随机产生msk
train_df = all_df[msk] #选择80%的训练集
test_df = all_df[~msk] #选择%20的测试集--测试集于训练集无交集
- 封装之前的所有数据预处理操作为一个函数
def PreprocessData(raw_df): #封装之前所有的数据预处理操作
df=raw_df.drop(['name'], axis=1)
age_mean = df['age'].mean()
df['age'] = df['age'].fillna(age_mean)
fare_mean = df['fare'].mean()
df['fare'] = df['fare'].fillna(fare_mean)
df['sex']= df['sex'].map({'female':0, 'male': 1}).astype(int)
x_OneHot_df = pd.get_dummies(data=df,columns=["embarked" ])
ndarray = x_OneHot_df.values
Features = ndarray[:,1:]
Label = ndarray[:,0]
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0, 1))
scaledFeatures=minmax_scale.fit_transform(Features)
return scaledFeatures,Label
#处理所有未处理的训练和测试数据
train_Features,train_Label=PreprocessData(train_df)
test_Features,test_Label=PreprocessData(test_df)
- 经封装的处理函数处理后