第01章 课程简介
1-01 课程简介
一、前端性能优化点
1、网络层面
2、构建层面
3、浏览器渲染层面
4、服务端层面
二、涉及的功能
1、资源的合并与压缩
2、图片编解码原理和类型选择
3、浏览器选择机制
4、懒加载预加载
5、浏览器存储
6、缓存机制
7、PWA
8、Vue-SSR
三、前端性能优化原理
1、作用及原理
2、如何与真实业务场景结合
3、理论结合实践
4、量化分析
四、静态资源压缩合并,减少http请求。
(1)减少http请求数量
(2)减少请求资源大小
在线网站、fis3两种实现压缩与合并的方法
第02章 资源合并与压缩
2-01 http请求潜在的性能优化点
一、
1、cs架构
2、bs架构:webserver、cdn
二、浏览器的一个请求从发送到返回都经历了什么
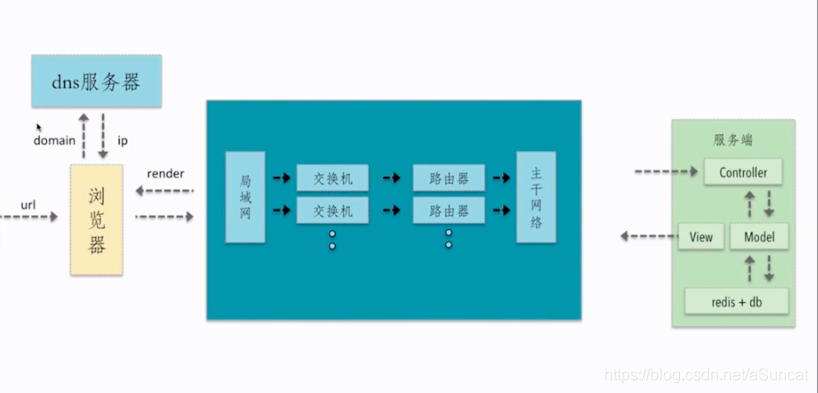
三、加载静态资源,cdn和主站域名不同,这样可以防止访问主站携带cookie,避免http request header中携带cookie
2-02 html压缩
一、资源压缩
1、html压缩
2、css压缩
3、js的压缩和混乱
4、文件合并
5、开启gzip
二、如何进行html压缩
1、使用在线网站进行压缩
2、nodejs提供了html-minifier工具
3、后端模板引擎(cjs/ ejs/ jade)渲染压缩
二、css压缩
1、无效代码删除
2、css语义合并
三、如何进行css压缩
1、使用在线网站进行压缩
2、使用html-minifier对html中的css进行压缩
3、使用clean-css对css进行压缩
四、js压缩
1、无效字符的删除
2、剔除注释
3、代码语义的缩减和优化
4、代码保护
五、如何进行js压缩
1、使用在线网站进行压缩
2、使用html-minifier对html中的js进行压缩
3、使用uglifyjs2对js进行压缩
六、keep-alive,不合并请求的缺点:
1、文件与文件之间有插入的上行请求,增加了n-1个网络延迟
2、受丢包问题影响更严重
3、经过代理服务器时可能会被断开
七、文件合并存在的问题
1、首屏渲染问题
2、缓存失效问题
八、文件合并的建议
1、公共库合并
2、不同页面的合并
3、见机行事,随机应变。
九、如何进行文件合并
1、使用在线网站进行文件合并
2、使用nodejs实现文件合并
十、浏览器静态资源请求并发数是有限的,这也需要我们进行文件的合并
2-06 fis3构建工具自动压缩合并流程
一、fis3
1、百度内部使用的构建工具,结合前端构建、服务器端构建的整个工程化解决方案。
2-07 fis3构建工具自动压缩合并-实操
一、fis3支持match语法
fis3 release -cd output ,fis3打包并将结果打包到output文件夹下
第03章 图片相关的优化
3-01 一张jpg图片的解析过程
一、jpg图片解析过程
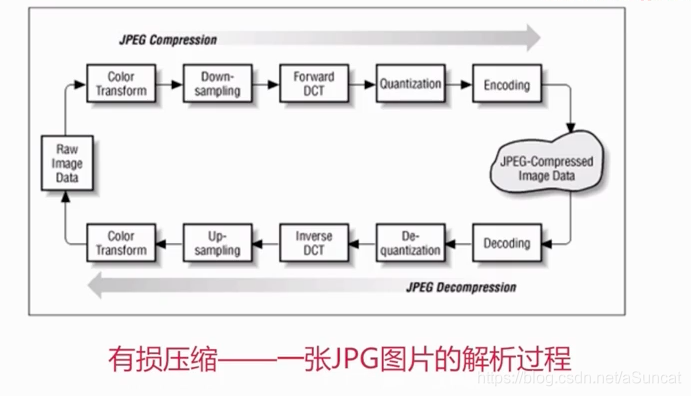
二、不同格式图片常用的业务场景
1、jpg有损压缩,压缩率高,不支持透明
2、png支持透明,浏览器兼容好
3、webq压缩程度更好,在ios webview有兼容性问题
4、svg矢量图,代码内嵌,相对较小,图片样式相对简单的场景
三、雪碧图(csssprits),将多个小图整合成一张大图
1、优点:减少http请求
2、缺点:图片太大,加载时间长,如果加载异常,影响整个页面的图片显示。
3、优化:将雪碧图进行拆分
(1)基于业务将业务相关的图整合到一张雪碧图
(2)对雪碧图进行拆分
四、淘宝图片是webp格式,如果不取_.webp,也可以使用降级的jpg
五、svg不需要重新发请求,因为是内嵌在html中的
六、网站
1、常用压缩图片网站:https://tinypng.com
2、图片格式转换网站:https://zhitu.isux.us
3、雪碧图网站:http://www.spritecow.com
七、inline-image,根据业务需要,<4kb或者<8kb的时候,推荐用inline。这种情况,相对于网络损耗,是更优的选择。
第04章 css与js的装载与执行
4-01 页面加载渲染的过程
一、html, 字符流->字节流->token
二、设置3到4个cdn域名
三、浏览器词法分析,token获取,是从上到下的,所以html是从上到下解析的
四、控制某个域名下的资源数量,从而避免达到并发的上限。
五、css阻塞
1、css head中阻塞页面的渲染
2、css阻塞js的执行
3、css不阻塞外部脚本的加载
六、js阻塞
1、直接引入的js阻塞页面的渲染
2、js不阻塞资源的加载
3、js顺序执行,阻塞后续js逻辑的执行
第05章 懒加载与预加载
5-01 懒加载原理
一、懒加载
监听scroll事件,图片进入可视区域,去请求资源,为图片赋上src
1、图片的top<屏幕的height时,就进入了可视区域
var viewHeight = document.documentElement.clientHeight; // 可视区域的高度
function lazyload() {
var eles = document.querySelectorAll('img[data-original][lazyload]');
[].forEach.call(eles, function(item, index) { // 等同于Array.prototype.forEach.call(), []是用来访问数组的原型链。
var rect;
if (item.dataset.original === '') {
return;
}
rect = item.getBoundingClientRect();
if (rect.bottom >= 0 && rect.top < viewHeight) {
!function() {
var img = new Image();
img.src = item.dataset.original;
img.onload = function() {
item.src = img.src;
}
item.removeAttribute('data-original');
item.removeAttribute('lazyload');
}();
}
})
}
lazyload();
document.addEventListener('scroll', lazyload);
二、预加载的3种方式
1、<img src="" style="display:none">
2、js中设置
使用Image对象
var image = new Image();
image.src = "http://test.png";
3、XMLHttpRequest
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = callback;
xhr.onprogress = progressCallback;
xhr.open('GET', 'http://test.png', true);
xhr.send();
function callback() {
if (xhr.readyState == 4 && xhr.status == 200) {
var responseText = xhr.responseText;
} else {
console.log('request was unsuccessful:' + xhr.status);
}
}
function progressCallback(e) {
e = e || event;
if (e.lengthComputable) {
console.log('Received' + e.loaded + ' of ' + e.total + 'bytes');
}
}
(1)优点:①能监听数据传输情况
(2)缺点:①跨域
三、可以使用preload.js
var queue = new createjs.LoadQueue(false); // true:异步, false:使用html标签方式
queue.on('complete', handleComplete, false);
queue.loadManifest([
{id: 'myImage', src: 'http://pic26.com/test1.png'}
{id: 'myImage2', src: 'http://pic26.com/test2.png'}
])
function handleComplete() {
var image = queue.getResult('myImage');
document.body.appendChild(image);
}
第06章 重绘与回流
6-01 css性能让javascript变慢
一、不同线程
javascript解析
ui 渲染
二、ui线程和javascript线程是互斥的,执行ui线程的时候,javascript线程是冻结的;执行javascript线程的时候,ui线程是冻结的。
6-02 什么是重绘与回流
一、回流(重排):页面布局和几何属性发生改变的时候,就会触发回流。如尺寸、布局、layout的变化
二、重绘:当render tree的一些元素需要更新属性,而这些属性只是改变元素的外观、风格,而不改变布局,比如background-color,color
三、回流会引起重绘,重绘不一定会引起回流
6-03 避免重绘回流的两种方法
一、触发页面重绘回流的属性,页面重新布局
1、盒子模型相关:
width、height、padding、border、margin、display、border-width、min-height
2、定位属性及浮动:
top、right、bottom、left、position、float、clear
3、节点内部文字结构,行内属性
text-align、overflow、line-height、vertical-align、font-weight、white-space、font-size
二、只触发重绘
color、border-style、border-radius、visibility、background、box-shadow、outline
三、避免重绘回流的方法
1、属性替代:避免使用触发重绘、回流的css属性
2、新建图层:将频繁重绘回流的dom元素单独作为一个独立图层,那么这个dom元素的重绘和回流的影响只会在这个图层中
(1)chrome创建图层方法
①3d或透视变换css属性:persepective,
transform:translateZ(0);
transform: translate3d(0,0,0);
will-change:transform;
②使用加速视频解码的节点
③拥有3d(webGL)上下文或加速的2d上下文的
④混合插件(如flash)
⑤对自己的opacity做css动画或使用动画webkit变换的元素
⑥拥有加速css过滤器的元素
⑦元素有一个包含复合层的后代节点(一个元素拥有一个子元素,该子元素在自己的层里)
⑧元素有一个z-index较低且包含一个复合层的兄弟(换句话说就是该元素在复合层上面渲染)
(2)图层缺点:图层合成过程非常消耗运算量
四、新建dom的过程
1、获取dom后分割为多个图层
2、对每个图层的节点计算样式结果(recalculate style-样式重计算)
3、为每个节点生成图形和位置(layout-回流和重布局)
4、将每个节点绘制填充到图层位图中(paint setup和paint-重绘)
5、图层作为纹理上传至gpu
6、符合多个图层到页面上生成最终屏幕图像(coposite layers-图层重组)
6-04
一、调试
1、performance:性能监测
layer:展示图层的情况
more tools-rendering
二、重绘回流优化点
1、translate替换top,top会触发回流但是translate不会
2、opacity替换visibility,visibility会触发重绘但不会触发回流
3、不要一条一条修改dom样式,预先定义好class,然后修改dom的class
4、可以将dom离线操作,如先display:none(会有一次reflow),但是接下来的操作都不会重绘,等离线操作结束后,再显示。
5、不要把dom节点的属性值放在循环里,当成循环的变量
offsetWidth/ offsetHeight,强制刷新缓冲机制
6、不要使用table,即使最后一行改变,整个table也会回流
7、动画实现速度的选择
8、动画新建图层
9、使用gpu加速,位置变换时,用translate,persepective
transform:translateZ(0);
transform: translate3d(0,0,0);
cpu走主线到gpu,会有传输损耗
第07章 浏览器缓存
7-01
一、知识点
1、localstorage、cookie、sessionstorage、indexdb
2、pwa、service worder
二、cookie
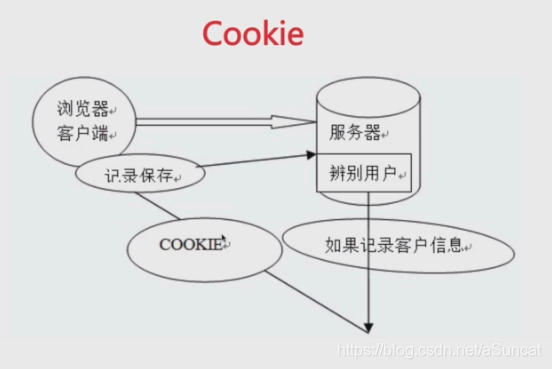
1、cookie的初衷:因为http请求无状态,所以需要cookie去维持客户端状态。
2、cookie的生成方式:
(1)http response header中的set-cookie
(2)js中可以通过document.cookie可以读写cookie
3、使用
(1)用于浏览器端和服务器端的交互
(2)客户端自身数据的存储
4、cookie存储数据能力被localStorage替代
5、httponly,当前cookie不支持js读写
6、cookie中在相关域名下面-cdn的流量损耗
解决方法:cdn的域名和主站的域名要分开
二、indexDB
1、indexDB是一种低级API,用于客户端存储大量结构化数据。该api使用索引来实现对该数据的高性能搜索。虽然web storage对于存储少量的数据很有用,但对于存储更大量的结构化数据来说,这种方法很有用。indexDB提供了一个解决方案。
为应用创建离线版本。
7-06
一、PWA
PWA(progressive web apps)是一种web app新模型,并不是具体指某一种前沿的技术或者某一个单一的知识点,是一个渐进式的web app,是通过一系列新的web特性,配合优秀的ui交互设计,逐步的增强web app的用户体验。
1、方向
(1)可靠:在没有网络的环境中也能提供基本的页面访问,而不会出现“未连接到互联网”的页面。
(2)快速:针对网页渲染及网络数据访问有较好优化。
(3)融入(engaging):应用可以被增加到手机桌面,并且和普通应用一样有全屏、推送等特性。
2、检测pwa、检测性能:lighthouse(https://lavas.baidu.com/doc-assets/lavas/vue/more/downloads/lighthouse_2.1.0_0.zip);(aSuncat:链接进去是404?)
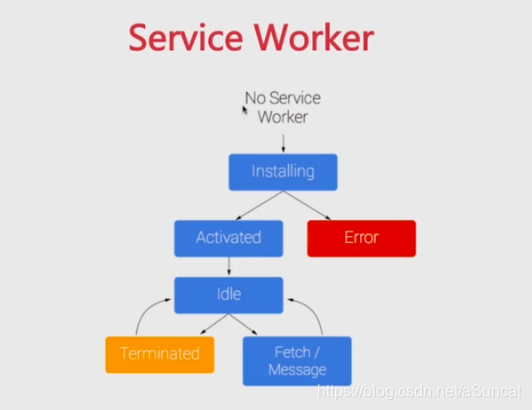
二、service worker
service worker是一个脚本,浏览器独立于当前网页,将其在后台运行,为实现一些不依赖页面或者用户交互的特性打开了一扇大门。在未来这些特性包括推送消息,北京后台同步,geofencing(地理围栏定位),但它将推出的第一个首要特性,就是拦截和处理网络请求的能力,包括以编程方式来管理被缓存的响应。
1、应用点
(1)使用拦截和处理网络请求的能力,去实现一个网络应用。
(2)使用service worker在后台运行同时能和页面通信的能力,去实现大规模后台数据的处理。
2、service worker生命周期
7-07
一、service worker
1、chrome://serviceworker-internals/
chrome://inspect/#service-workers
2、application里找serveiceworker注册的文件名,然后network里搜索serviceworker注册文件
3、serviceworker有个api叫cache,浏览器cache storage里有这些缓存资源
4、network的size能看到数据是否是从serviceworker的缓存中读取的
5、mobile.twitter.com能离线加载应用
7-08
1、cookie
document.cookie 获取cookie
document.cookie = 'userName=may' 写入cookie
document.cookie = 'gender=male'
7-09
1、indexDB,大规模数据处理
function openDB(name, callback) {
// 建立打开indexDB
var request = window.indexedDB.open(name);
request.onerror = function(e) {
console.log('open indexdb error');
}
request.onsuccess = function(e) {
myDB.db = e.target.result;
callback && callback();
// console.log(myDB.db);
// console.log(myDB.db.close()); // 关闭
// indexedDB.deleteDatabase(); 删除
}
// from no database to first version, first version to second version...
request.onupgradeneeded = function() {
var store = request.result.createObjectStore('books', {
keyPath: 'isbn'
});
// 建索引
var titleIndex = store.createIndex('by_title', 'title', {
unique: true
});
var authorIndex = store.createIndex('by_author', 'author');
store.put({
title: 'Quarry memories',
author: 'fred',
isbn: 12345
});
store.put({
title: 'water buffaloes',
author: 'fred',
isbn: 23456
})
store.put({
title: 'bednack',
author: 'barney',
isbn: 34567
})
}
}
var myDB = {
name: 'testDB',
version: '1',
db: null
}
function addData(db, storeName) {
// object store,transaction事务,是为了操作object store
var transaction = db.transaction('books', 'readwrite');
var store = transaction.objectStore('books');
// 获取当前indexdb中的数据
var request = store.get(23456);
request.onsuccess = function(e) {
console.log(e.target.result);
}
// 添加信息到indexDB中
store.add({
title: 'flowers',
author: 'quan',
isbn: 222
})
// 删除记录
// store.delete(222);
store.get(222).onsuccess = function(e) {
var books = e.target.result;
console.log(books);
books.author = 'james';
var request = store.put(books); // put更新
request.onsuccess = function(e) {
console.log('update success');
}
}
}
openDB(myDB.name, function() {
// 关闭indexdb
// myDB.db.close();
// 删除indexdb
// window.indexedDB.deleteDatabase();
});
setTimeout(function() {
addData(myDB.db);
}, 2000)
2、indexDB没有表的概念,有object store的概念
7-12
一、每个service worker都有启动它的配置文件
app.js
if (navigator.serviceWorker) {
var sendBtn = document.getElementById('send-msg-button');
var msgInput = document.getElementById('msg-input');
var msgBox = document.getElementById('msg-box');
sendBtn.addEventListener('click', function() {
// 主页面发送信息到serviceworker
navigator.serviceWorker.controller.postMessage(msgInput.value);
})
navigator.serviceWorker.addEventListener('message', function() {
msgBox.innerHTML = msgBox.innerHTML + ('<li>' + event.data.message + '</li>')
})
navigator.serviceWorker.register('./service-worder.js', {scoped: './'})
.then(function(reg) {
console.log(reg);
})
.catch(function(e) {
console.log(e);
})
} else {
alert('service worker is not supported');
}
service-worker.js
self.addEventListner('install', function(e) {
e.waitUntil( // waitUntil接收一个promise对象
caches.open('app-vl') // caches:cacheStorage的对象
.then(function(cache) {
console.log('open cache');
return cache.addAll([
'./app.js',
'./main.css',
'./serviceWorker.html'
])
})
)
})
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request).then(function(res) {
if (res) {
return res;
}else {
// 通过fetch方法向网络发起请求
fetch(url).then(function (res) {
if (res) {
// 对于新请求的资源存储到我们的cachestorage
caches
} else {
// 用户提示
}
});
}
})
)
})
二、service workers只能在https下才能生成,本地调试能用localhost:80,不能用ip:80
三、serviceworker的api
1、主页面给serviceworker发消息
self.addEventListner('message', function(event) {
var promise = self.clients.matchAll().then(function(client) {
var senderID = event.source ? event.source.id : 'unkown';
clientList.forEach(function(client) {
if (client.id === senderID) {
return;
} else {
client.postMessage({
client: senderID,
message: event.data
})
}
})
})
event.waitUtil(promise);
})
2、serviceworker给主页面发消息
第08章 缓存优化
8-01 缓存1
一、缓存
1、cache-control所控制的缓存策略
2、last-modified和etag以及整个服务端浏览器端的缓存流程
二、cache-control
1、max-age:从请求资源到这段时间之内,浏览器请求资源,不会向浏览器发起请求
(1)cache-control: max-age=315360000
状态码也是200:status code: 200 (from memory cache)
(2)max-age(http1.1)比expires(http1.0)的优先级高
2、s-maxage
(1)cache-control: s-maxage=21536000
状态码304
(2)s-maxage比max-age优先级高
(3)只适用于public缓存设备,不适用于private缓存设备
3、private: 私人缓存,如用户浏览器缓存
4、public: cdn缓存设备
5、no-cache
(1)cache-control: private, max-age=0, no-cache
向服务器端发起请求,根据服务端返回的信息决定缓存策略
6、no-store
(1)完全不使用任何缓存策略
8-03 last-modified、if-modified-since
一、expires
1、缓存过期时间,用来指定资源到期的时间,是服务器端的具体的时间点。
2、告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。
3、max-age, expires
强的浏览器端缓存,不需要向服务器端发起请求。
二、last-modified/ if-modified-since
1、基于客户端和服务端协商的缓存机制
2、last-modified —— response header
last-modified:Fri,18 Aug 2017 07:21:46 GMT
状态码304
先走max-age,过期了再取last-modified
3、if-modified-since —— request header
if-modified-since:Fri, 18 Aug 2017 07:31:46 GMT
4、last-modified/ if-modified-since需要与cache-control共同使用
4、last-modified有什么缺点
(1)某些服务端不能获取精确的修改时间
(2)文件修改时间改了,但文件内容却没有变
8-04 etag/ if-none-match
一、etag/ if-none-match
1、文件内容的hash值
2、etag——response header
3、if-none-match——request header
4、需要与cache-control共同使用
5、etag/ if-none-match优先级比last-modified/ if-modified-since更高
6、优点:比if-modified-since更精确
7、状态码:304
二、分级缓存策略
通过apche、nginx的配置,自动进行的缓存策略
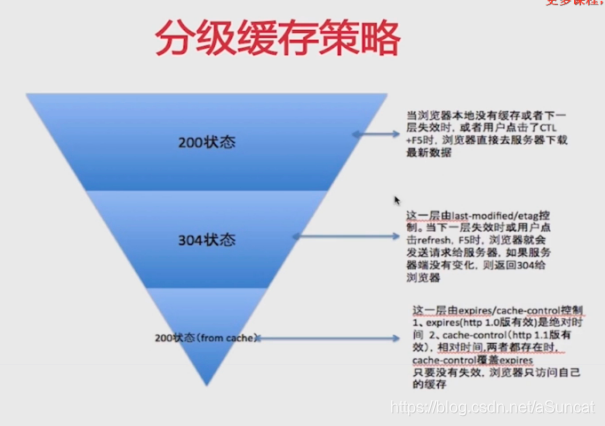
三、缓存策略是服务端定的。
四、node开启的服务:
(1)chrome浏览器刷新直接加了一个cache-control:max-age=0;
(2)防止浏览器加max-age=0的方式:
①index.html,外链方式加入图片。②外链方式:右键,检查,地址栏输入地址
mime.js
exports.types = {
'jpg': 'image/jpeg',
'json': 'application/json'
}
config.js
exports.Expires = {
fileMatch: /^(jpg|png|gif|js|css)$/ig,
maxAge: 60 * 60 * 24 * 365
}
app.js
var PORT = 8000;
var http = require('http');
var url = require('url');
var fs = require('fs');
var path = require('path');
var mime = require('mime').types;
var config = require('./config');
var server = http.createServer(function(request, response) {
var pathname = url.parse(request.url).pathname;
var realPath = 'assets/img' + pathname;
var ext = path.extname(realPath);
ext = ext ? ext.slice(1): 'unknown';
var contentType = mime[ext] || 'text/plain';
if (ext.match(config.Expires.fileMatch)) {
var expires = new Date();
expires.setTime(expires.getTime() + config.Expires.maxAge * 1);
response.setHeader('Expires', expires.toUTCString());
response.setHeader('Cache-Control', 'max-age=' + config.Expires.maxAge);
}
fs.stat(realPath, function(err, stat) { // stat:读取文件的状态,可获取最后修改日期
if (stat) {
var lastModified = stat.mtime.toUTCString();
response.setHeader('Last-Modified', lastModified);
}
if (request.headers['if-modified-since'] && lastModified == request.headers['if-modified-since']) {
response.writeHead(304, 'Not Modified');
response.end();
} else {
fs.exists(realPath, function(exists) {
if (!exists) {
response.writeHead(404, {
'Content-Type': 'text/plain'
});
response.write('this request url' + pathname + 'was not found');
} else {
fs.readFile(realPath, 'binary', function(err, file) { // binary:二进制的
if (err) {
response.writeHead(500, {
'Content-Type': contentType
})
} else {
response.write(file, 'binary');
response.end();
}
})
}
})
}
});
});
server.listen(PORT);
console.log('runnding at port:' + PORT);
8-05 案例解析
一、缓存读取
1、max-age,浏览器读取缓存,200,from memory cache。
不会带if-modified-since
2、s-maxage,向cdn请求,这个请求是真正发出去了,读取的是cdn缓存,而不是走浏览器缓存。304
到cdn服务器后,cdn根据last-modified,if-modified-since判断当前文件是否过期,if-modified-since传到cdn,cdn会比对if-modified-since和文件最后修改日期是否相同,这个文件的相关内容从s-maxage来决定当前读取的文件的内容。如果s-maxage已经过期,就会去原服务器拿最新信息。
就算if-modified-since失效了,还是会返回304.
二、缓存机制
强制缓存优先于协商缓存进行,若强制缓存(Expires和Cache-Control)生效则直接使用缓存,若不生效则进行协商缓存(Last-Modified / If-Modified-Since和Etag / If-None-Match),协商缓存由服务器决定是否使用缓存,若协商缓存失效,那么代表该请求的缓存失效,返回200,重新返回资源和缓存标识,再存入浏览器缓存中;生效则返回304,继续使用缓存。
8-06 流程图
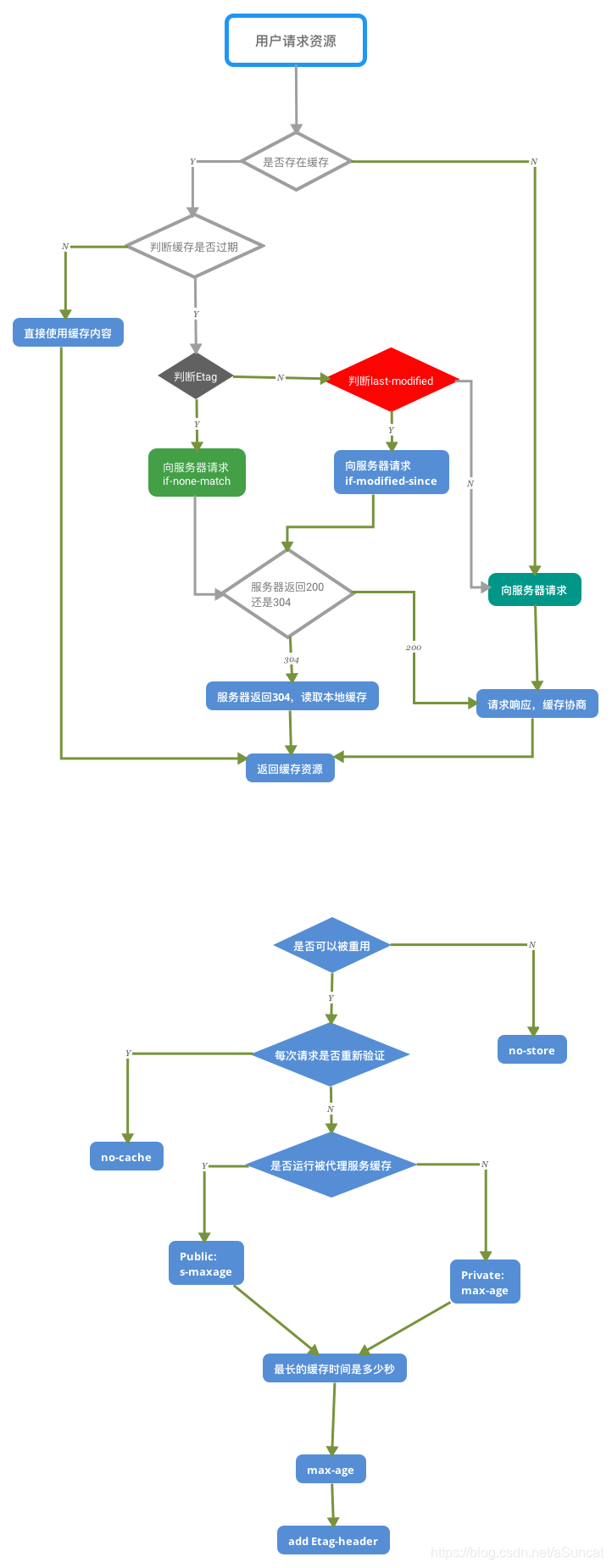
aSuncat:推荐文章(深入理解浏览器的缓存机制):https://blog.csdn.net/howgod/article/details/88176395
第09章 ssr
9-01
一、服务端是nodejs,客户端复杂运算可以放到服务端,减少前端运算成本。
二、流程
1、vue开发,页面加载流程
(1)加载vue.js
(2)执行vue.js代码
(3)生成html页面
三、没有前端框架时
1、用jsp/ php在服务器端进行数据的填充,发送给客户端就是已经填充好数据的html
2、使用jquery异步加载数据
3、使用react和vue前端框架
四、多层次的优化方案
1、构建层模板编译
2、数据无关的prerender的方式:如果用户进来看到的页面都是一样的(如营销活动),可以在构建层直接将vue.js执行掉,生成相应的html
3、服务端渲染:可能涉及到内存泄漏,服务端运算能力,服务器压力。
服务端本身是在集群上的
四、ssr: server side rendering
9-03
一、豆瓣资源:https://github.com/monkeyWangs/doubanMovie-SSR
二、渲染
<!--vue-ssr-outlet-->