一.数据流向
1.基本的数据流向
client —>server(直接由客户端流向服务端)
在实际生产环境中因为访问量大,服务器承受不了压力,因此基本不会使用。
2.企业架构的数据流向
企业采用分布式的数据流向。
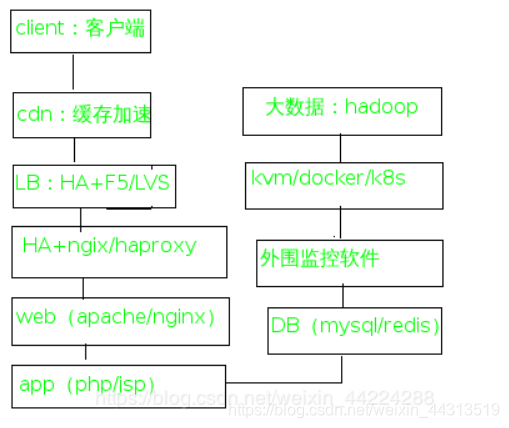
cdn:缓存加速reverse
LB:HA+F5/LVS 调度,负载均衡(路由级别的负载均衡,每级的负载均衡基本都要加高可用,为第四级别的负载均衡)
HA+nginx/haproxy:第七级别的负载均衡
web:apache/ngingx
app(php/jsp)
DB(mysql/redis/mongodb):内存级别的数据库,读的时候快,负载均衡,主备,并且读写分离
zzbix/nagios/cacti:外围监控软件,支持API,通过写脚本调用API动态的加载或者删除端口
Kvm/docker:实现秒级部署,秒级上线,一层一层 k8s(swarm):虚拟化
大数据:hadoop
elk:开元分布式的搜索引擎,l代表日志,客服人员可以自己去查日志
git:代码管理
openstack:云计算时的扩展,把服务器一键生成一套系统
apache:
处理:prefork,预派生,处理业务高峰,与客户端建立的连接时稳定的
优点:处理动态的页面,稳定。
nginx:
work(cpu)
优点:高并发,处理静态资源,接收请求但不处理请求,需要内存小,配置文件简单,支持重写,自动八挂了的服务器踢出群组,内部会有报错,但是外部不会发现,内部支持比较好,原码编译时可以加载模块。
缓存加速的原因:近,快。服务器分布在各个省市
cdn:就近原则,当有客户请求时先去就近的cdn取数据,如果没有再在原来的服务器去取
IP:第四层的传输协议 port:端口一般为80
但是淘宝的是Tengine端口,是自己编写的
3.http访问的几种形式
cdn在缓存网页时,可能有的网页基本不会用到,而有的网页则需要经常使用,所以了解页面的访问量也是必要的。
pv:page file:页面访问,客户每点击一次pv增加一次
uv:user view:用户访问,都是判断页面访问量大小
active connection:判断网站的活跃量
qps:quest per second:每秒的请求量