一、为什么使用缓存
在看这个问题之前,可以先看一下成功的软件产品具备哪些特点:
1)能解决目标用户的痛点;
2)能够为企业或个人带来利益;
3)具有不错的用户粘性;
其中一个极其重要的因素就是要有好的用户体验
二、分布式缓存的特性
分布式缓存具有如下特性:
- 高性能:当传统数据库面临大规模数据访问时,磁盘I/O 往往成为性能瓶颈,从而导致过高的响应延迟.分布式缓存将高速内存作为数据对象的存储介质,数据以key/value 形式存储,理想情况下可以获得DRAM 级的读写性能;
- 动态扩展性:支持弹性扩展,通过动态增加或减少节点应对变化的数据访问负载,提供可预测的性能与扩展性;同时,最大限度地提高资源利用率;
- 高可用性:可用性包含数据可用性与服务可用性两方面.基于冗余机制实现高可用性,无单点失效(single point of failure),支持故障的自动发现,透明地实施故障切换,不会因服务器故障而导致缓存服务中断或数据丢失.动态扩展时自动均衡数据分区,同时保障缓存服务持续可用;
- 易用性:提供单一的数据与管理视图;API 接口简单,且与拓扑结构无关;动态扩展或失效恢复时无需人工配置;自动选取备份节点;多数缓存系统提供了图形化的管理控制台,便于统一维护;
- 分布式代码执行(distributed code execution):将任务代码转移到各数据节点并行执行,客户端聚合返回结果,从而有效避免了缓存数据的移动与传输.最新的Java 数据网格规范JSR-347中加入了分布式代码执行与Map/reduce 的API 支持,各主流分布式缓存产品,如IBM WebSphere eXtreme Scale,VMware GemFire,GigaSpaces XAP 和Red Hat Infinispan 等也都支持这一新的编程模型.
三、缓存应用场景
分布式缓存的典型应用场景可分为以下几类:
1)、页面缓存:用来缓存Web 页面的内容片段,包括HTML、CSS 和图片等,多应用于社交网站等;
2)、浏览器缓存、服务端缓存、数据库缓存;
3)、平台级缓存:在系统开发的时候,适当地使用平台级缓存,往往可以取到事半功倍的效果。平台级缓存在这里指的是用来写带有缓存特性的应用框架,或者可用于缓存功能的专用库(如 PHP 中的 Smarty 模版库);
4)、应用级缓存:当平台级缓存不能满足系统性能要求的时候,就要考虑使用应用级缓存了。应用级缓存,需要开发着通过代码来实现缓存机制。这里是 NoSQL 的胜场,不论是 Redis 还是 MongoDB,以及 Memcached 都可以作为应用级缓存的重要技术。一种典型的方式是每分钟或一段时间后统一生成某类页面存储在缓存中,或者可以在热数据变化时更新缓存;
5)、状态缓存:缓存包括Session 会话状态及应用横向扩展时的状态数据等,这类数据一般是难以恢复的,对可用性要求较高,多应用于高可用集群;
6)、并行处理:通常涉及大量中间计算结果需要共享;
7)、事件处理:分布式缓存提供了针对事件流的连续查询(continuous query)处理技术,满足实时性需求;
8)、极限事务处理:分布式缓存为事务型应用提供高吞吐率、低延时的解决方案,支持高并发事务请求处理,多应用于铁路、金融服务和电信等领域;
四、分布式缓存的发展
分布式缓存经历了多个发展阶段,由最初的本地缓存到弹性缓存平台直至弹性应用平台[8],目标是朝着构建更好的分布式系统方向发展(如下图所示).
- 本地缓存:数据存储在应用代码所在内存空间.优点是可以提供快速的数据访问;缺点是数据无法分布式共享,无容错处理.典型的,如Cache4j;
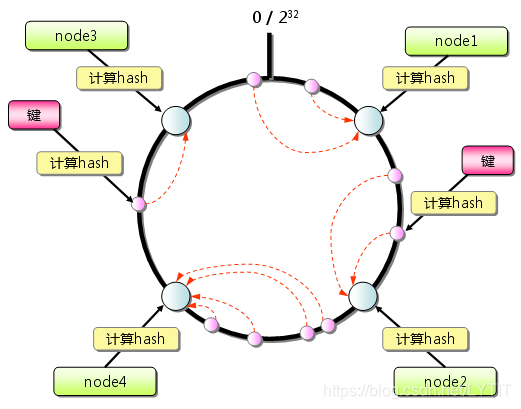
- 分布式缓存系统:数据在固定数目的集群节点间分布存储.优点是缓存容量可扩展(静态扩展);缺点是扩展过程中需要大量配置,无容错机制.典型的,如 Memcached;
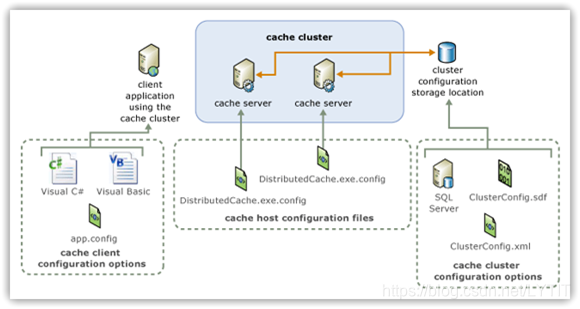
- 弹性缓存平台:数据在集群节点间分布存储,基于冗余机制实现高可用性.优点是可动态扩展,具有容错能力;缺点是复制备份会对系统性能造成一定影响.典型的,如 Windows Appfabric Caching;
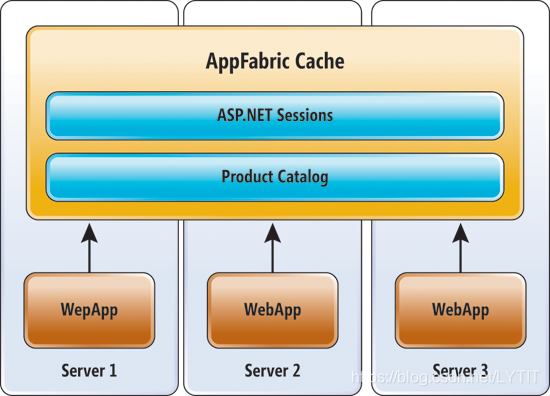
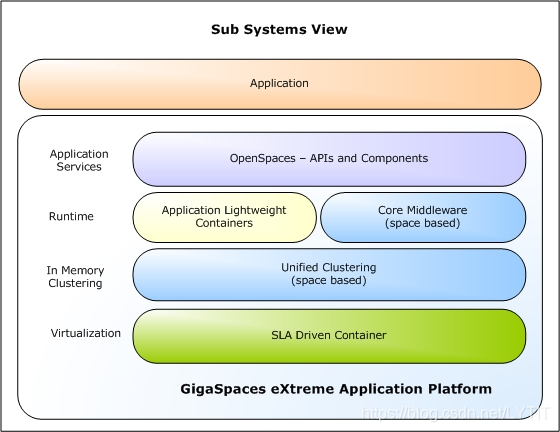
- 弹性应用平台:弹性应用平台代表了云环境下分布式缓存系统未来的发展方向.简单地讲,弹性应用平台是弹性缓存与代码执行的组合体,将业务逻辑代码转移到数据所在节点执行,可以极大地降低数据传输开销,提升系统性能.典型的,如 GigaSpaces XAP.

五、分布式缓存部分应用
1、基于 Redis 的多级缓存示例
一个使用了 Redis 集群和其他多种缓存技术的应用系统架构如图所示:
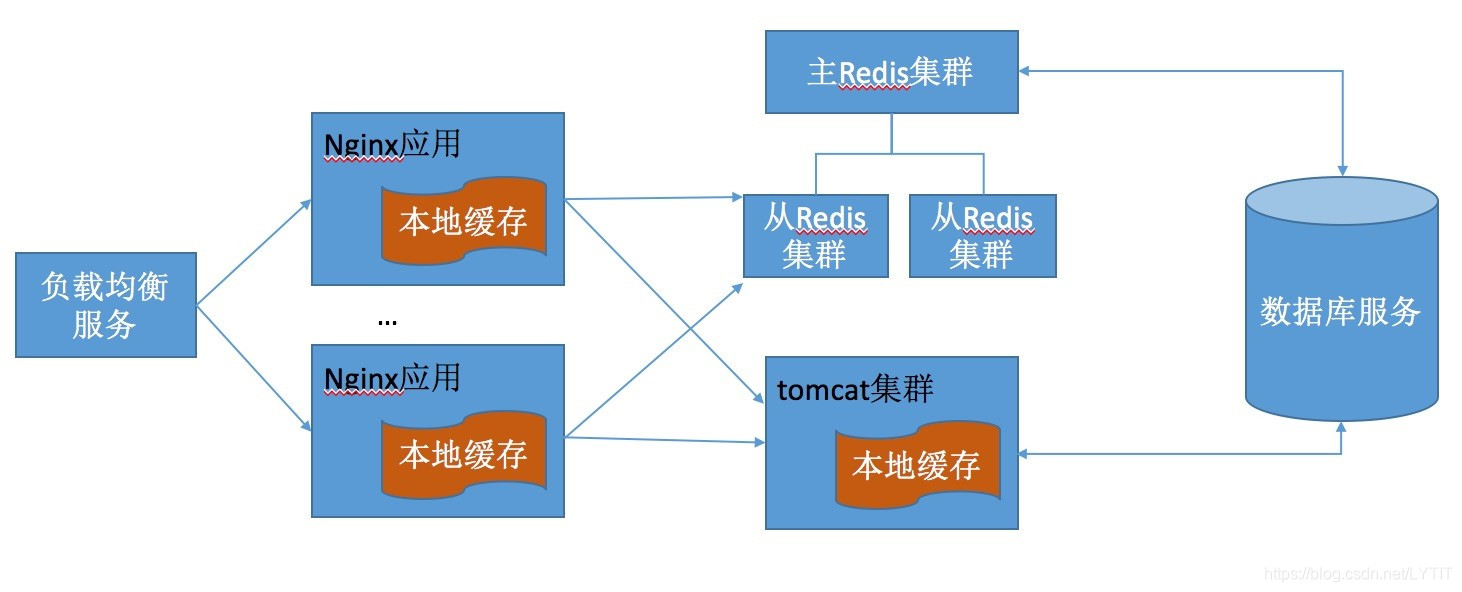
1)首先,用户的请求被负载均衡服务分发到 Nginx 上,此处常用的负载均衡算法是轮询或者一致性哈希,轮询可以使服务器的请求更加均衡,而一致性哈希可以提升 Nginx 应用的缓存命中率。
2)接着,Nginx 应用服务器读取本地缓存,实现本地缓存的方式可以是 Lua Shared Dict,或者面向磁盘或内存的 Nginx Proxy Cache,以及本地的 Redis 实现等,如果本地缓存命中则直接返回。Nginx 应用服务器使用本地缓存可以提升整体的吞吐量,降低后端的压力,尤其应对热点数据的反复读取问题非常有效。如果 Nginx 应用服务器的本地缓存没有命中,就会进一步读取相应的分布式缓存——Redis 分布式缓存的集群,可以考虑使用主从架构来提升性能和吞吐量,如果分布式缓存命中则直接返回相应数据,并回写到 Nginx 应用服务器的本地缓存中。
3)如果 Redis 分布式缓存也没有命中的时候,则会回源到 Tomcat 集群,在回源到 Tomcat 集群时也可以使用轮询和一致性哈希作为负载均衡算法。当然,如果 Redis 分布式缓存没有命中的话,Nginx 应用服务器还可以再尝试一次读主 Redis 集群操作,目的是防止当从 Redis 集群有问题时可能发生的流量冲击。在 Tomcat 集群应用中,首先读取本地平台级缓存,如果平台级缓存命中则直接返回数据,并会同步写到主 Redis 集群,然后再同步到从 Redis 集群。此处可能存在多个 Tomcat 实例同时写主 Redis 集群的情况,可能会造成数据错乱,需要注意缓存的更新机制和原子化操作。
4)如果所有缓存都没有命中,系统就只能查询数据库或其他相关服务获取相关数据并返回,当然,我们已经知道数据库也是有缓存的。
5)整体来看,这是一个使用了多级缓存的系统。Nginx 应用服务器的本地缓存解决了热点数据的缓存问题,Redis 分布式缓存集群减少了访问回源率,Tomcat 应用集群使用的平台级缓存防止了相关缓存失效或崩溃之后的冲击,数据库缓存提升数据库查询时的效率。
6)正是多级缓存的使用,才能保障系统具备优良的性能。
2、基于云服务的分布式缓存
云服务不仅为软件系统的开发和部署带来了更多的敏捷性,而且提供了更多创新的可能性。当分布式缓存技术遇到云服务会是怎样的情形呢?EVCache 就是这样的一种技术。
EVCache 是一个开源、快速的分布式缓存,基于 Memcached 的内存存储 和 Spymemcached 客户端实现的解决方案,主要用在亚马逊弹性计算云服务 (AWS EC2)的基础设施上,为云计算做了优化,能够顺畅而高效地提供数据层服务。
EVCache 在 Netflix 内部是一个被广泛使用的数据缓存服务,所提供的低延迟且高可用的缓存方案可以很好地满足 Netflix 微服务架构需要,也用来做一般数据的存储。EVCache 能够使面向终端用户的应用,个性化算法和各种微服务都具备优良的性能。
EVCache 具有如下的特性:
1)分布式的键值对存储 , 缓存可以跨越多个实例;
2)数据可以跨越亚马逊云服务的可用区进行复制;
3)通过 Netflix 内部的命名服务进行注册,自动发现新节点和服务;
4)为了存储数据,键是非空字符串,值可以是非空的字节数组,基本类型,或者序列化对象,且小于 1 MB;
5)作为通用的缓存集群被各种应用使用,支持可选的缓存名称,以命名空间避免主键冲突;
6)一般的缓存命中率在 99% 以上;
与 Netflix 驻留数据框架能够良好协作,典型的访问次序: 内存 ->EVCache -> Cassandra/SimpleDB/S3。
使用缓存技术所带来的最大影响可能是数据的不一致性。出于性能优先的考虑,具体的应用会依赖于 EVCache 来处理数据的不一致性。
对于存活时间很短的数据,用 TTL 设置数据的失效时间,对于长时间保留的数据,通过构建一致性检查来修复它们。
一个典型的用例是 Netflix 向用户推荐与已看历史中节目类似的电影或者电视节目,如下图所示:
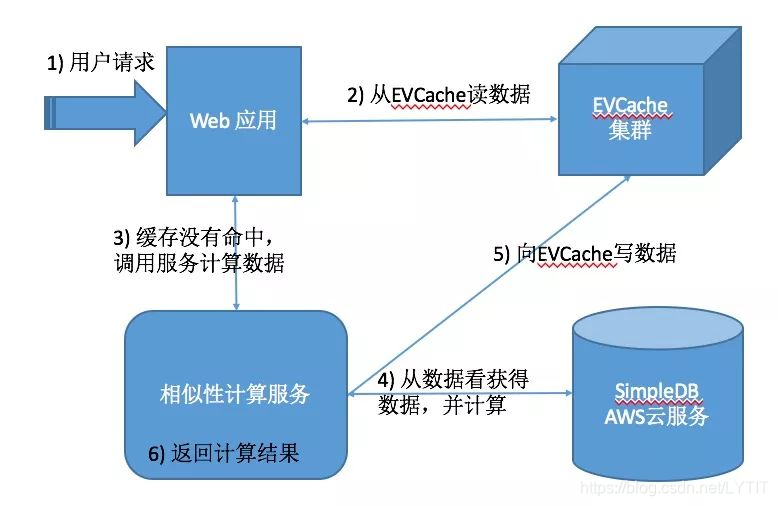
内容相似性推荐服务给出了与已看历史中节目类似的电影或者电视节目的相似性列表。一旦计算出了相似性,就存储在 SimpleDB/S3 中,前端使用 EVCache。
当任何应用或者算法需要这些数据的时候,可以从 EVCache 提取数据,并返回结果。具体过程如下:
1)一个客户向 Web 应用发了一个页面请求,处理这一请求需要得到一个电影或电视节目的相似性列表;
2)Web 应用查询 EVCache 来得到这些数据,这样场景的典型缓存命中率高于 99.9%;
3)如果缓存没有命中,Web 应用将调用相似性计算服务来计算这些数据;
4)如果已经计算过的数据也没有命中的话,相似性计算服务将从 SimpleDB 中读取数据。如果在 SimpleDB 没有,相似性计算服务根据给出的电影或电视节目重新计算相似性;
5)相似性计算服务在计算出电影或电视节目的数据后,将数据写入到 EVCache 中;
6)最后,相似性计算服务生成客户端所需要的响应并返回给客户端。
参考地址:
- https://www.cnblogs.com/softidea/p/5555578.html
- https://blog.csdn.net/gitchat/article/details/78913230
不足之处,还望大牛多多指点,相互学习,共同进步~