- 信息论基础(熵 联合熵 条件熵 信息增益 基尼不纯度)
2.决策树的不同分类算法(ID3算法、C4.5、CART分类树)的原理及应用场景 - 回归树原理
- 决策树防止过拟合手段
- 模型评估
- sklearn参数详解,Python绘制决策树
学习时长:两天
参考:西瓜书
cs229吴恩达机器学习课程
李航统计学习
谷歌搜索公式推导参考:http://t.cn/EJ4F9Q0博客可参考:https://blog.csdn.net/qq_29027865/article/details/86710772
1/信息论基础(熵 联合熵 条件熵 信息增益 基尼不纯度)
熵:是信息的期望
用来衡量不确定性,当熵越大,概率X=Xi的不确定性越大。
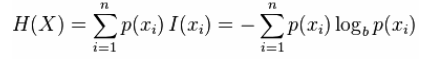
联合熵:观察一个多个随机变量的随机系统获得的信息量,通俗的说,比如变量x,y,两个在一起时的不确定性度量
条件熵:在变量x确定时,y的不确定性度量
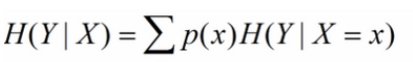
信息增益:在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好。在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差
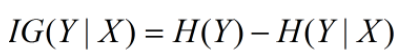
基尼系数:
是一种与信息熵类似的做特征选择的方式,可以用来做数据的不纯度。在CART算法中利用基尼指数构造二叉决策树(选择基尼系数最小的特征及其对应的特征值)
参考博文:https://blog.csdn.net/xbmatrix/article/details/56691137
2/决策树的不同分类算法
ID3:算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归的建立决策树。具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点,再对子结点递归地调用以上方法,构建决策树,直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树,ID3相当于用极大似然法进行概率模型的选择。
C4.5:与ID3算法相似,在生成的过程中,用信息增益比来选择特征
CART:同样由特征选择、树的生成及剪枝组成,既可以用于分类也可以用于回归。是在给定输入随机变量X条件下输出随机变量Y的条件概率分布的学习方法。
CART算法由以下两步组成:
1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;
2)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。
3/回归树原理

4/决策树防止过拟合手段
使用预剪枝可以降低过拟合的风险,还能显著减少决策树的训练时间开销和测试时间开销。

5/模型评估
决策树适用分类指标:P,R,F1,ROC曲线,使用交叉验证
回归树适合回归指标:MAE,MSE,RMSE,R平方,Adjusted R平方,MAPE,RMSPE
6/sklearn参数
class sklearn.tree.DecisionTreeClassifier(criterion =‘gini’,splitter =‘best’,max_depth = None,min_samples_split = 2,min_samples_leaf = 1,min_weight_fraction_leaf = 0.0,max_features = None,random_state = None,max_leaf_nodes = None,min_impurity_decrease = 0.0,min_impurity_split = None,class_weight = None,presort = False )
criterion:特征选择标准,可选参数,默认是gini
splitter:best是根据算法选择最佳的切分特征。random找局部最优的划分点。
max_depth:树的最大深度。None表示划分到所有叶子结点都是纯的或小于最小样本量
min_samples_split :节点可以划分的最小样本量
min_samples_leaf:叶子节点所需的最小样本数。
min_weight_fraction_leaf :计算权重,默认大家权重一样
max_features :寻找最佳分割时考虑的特征数量
random_state:随机数种子
max_leaf_node: 最大的叶节点数量
min_impurity_decrease:节点划分最小不纯度,小于该值不再分裂
min_impurity_split:节点的不纯度高于该值,才进行分裂
class_weight:类别权重
presort :数据是否预排序,默认False,数据量小可以改成True
7/绘制决策树
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()#加载数据
clf = tree.DecisionTreeClassifier()#初始化模型
clf = clf.fit(iris.data, iris.target)#训练模型
with open(“iris.dot”, ‘w’) as f: f = tree.export_graphviz(clf, out_file=f)#存储决策树
import pydotplus
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf(“iris.pdf”)
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True,rounded=True, special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
clf.predict(iris.data[:1, :])