微服务架构都是通过业务来划分各个服务,然后对外暴露接口。一个接口可能有多个服务共同完成。例如:前几篇文章中说的管理员服务和订单服务都需要调用用户服务,也可以说它们依赖用户服务。这只是比较简单的业务。若是你的系统比较庞大。业务层次比较复杂。一个接口可能需要更多个业务协同完成。倘若,某个服务发生了故障,或者响应较慢。那么它所关联的所有接口,都会受到影响。但是这么多个服务,你怎么知道是哪个服务发生了故障或者网络超时呢?此时,就要对这个服务所涉及的整条链路进行追踪。分析每一个服务的可用性和响应时间,这样就可以及时做出修复。这就需要Zipkin。
Zipkin介绍
Zipkin is a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in microservice architectures. It manages both the collection and lookup of this data. Zipkin’s design is based on the Google Dapper paper.
Applications are instrumented to report timing data to Zipkin. The Zipkin UI also presents a Dependency diagram showing how many traced requests went through each application. If you are troubleshooting latency problems or errors, you can filter or sort all traces based on the application, length of trace, annotation, or timestamp. Once you select a trace, you can see the percentage of the total trace time each span takes which allows you to identify the problem application
上面是Zipkin官网给出的。很多读者看到这个会想:妖怪吧~这么大一串英文,看得懂个鬼。当然,我也是看不懂的,就认识那几个单词。但是可以使用翻译工具进行翻译啊。比如:谷歌翻译。通过翻译,了解大概意思。
Zipkin是一种分布式跟踪系统。 它有助于收集解决微服务架构中的延迟问题所需的时序数据。 它管理这些数据的收集和查找。 Zipkin的设计基于Google Dapper论文。
应用程序用于向Zipkin报告时序数据。 Zipkin UI还提供了一个依赖关系图,显示了每个应用程序通过的跟踪请求数。 如果要解决延迟问题或错误,可以根据应用程序,跟踪长度,注释或时间戳对所有跟踪进行筛选或排序。 选择跟踪后,您可以看到每个跨度所需的总跟踪时间百分比,从而可以识别问题应用程序。
上面就是翻译后的结果。简便点说,就是Zipkin使用UI界面,更加直观的显示了请求中的相关数据。
再讲Zipkin之前,先讲一下Spring Cloud Sleuth,它可以应用于计划任务 、多线程服务或复杂的Web请求,尤其是在一个由多个服务组成的系统中,通过添加独特的标识符来使用日志跟踪和诊断问题,并能轻松的集成Logback、SLF4J日志框架。动手实际操作,更能直观的反应。
Sleuth的基本使用
首先在每一个服务中添加约束。因为Zipkin的约束文件中已经有Sleuth,所以,直接导入Zipkin的约束即可。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
Sleuth要对请求进行采样,而它默认的probability是0.1,即10%。在开发环境中,可以设置采集所有信息。即设置为1
spring:
sleuth:
sampler:
probability: 1
这里需要使用日志来跟踪,所以,在需要的地方打上日志即可。启动服务,访问用户服务。http://localhost:9999/api/user/v1.0/user

清楚的看到日志格式:[application.name,traceId,spanId,export]
- application.name:就是当前服务的应用名称,即用户服务(user-service)
- traceId:为请求链路分配的id,唯一标识。
- spanId:表示一个基本的工作单元,一个请求可以包含多个步骤,每个步骤都拥有自己的spanId。一个请求包含一个TraceId,多个SpanId。
- export:是否将该信息输出到类似Zipkin这样的聚合器进行展示。
可以通过traceId来分辨当前请求来自哪个服务。Sleuth的用法还有很多,这里就讲一下基础,下面回归主题。
Zipkin的基本使用
官网提供了三种方式,来启动Zipkin。
(1)使用docker来构建镜像。
docker run -d -p 9411:9411 openzipkin/zipkin
(2)直接下载一个zipkin.jar
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
(3)通过源码进行构建
# get the latest source
git clone https://github.com/openzipkin/zipkin
cd zipkin
# Build the server and also make its dependencies
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# Run the server
java -jar ./zipkin-server/target/zipkin-server-*exec.jar
这里我就选择第一种,使用docker来构建,不熟悉docker的朋友,可以去学习一下docker。菜鸟教程,包括各个操作系统的安装和基本使用,都写的很详细。因为我的docker安装在linux系统上的,所以,使用虚拟机启动centos7。执行上面的命令。然后启动docker。启动Zipkin镜像。
访问:http://192.168.145.101:9411 就能看到Zipkin的界面了。
初次访问,里面什么都没有,接下来,就让应用程序与Zipkin进行关联。
需要在配置文件中,指明Zipkin的地址。
spring:
zipkin:
base-url: http://192.168.145.101:9411/
这里的ip地址和端口都是可变的,博主放的是自己本机的地址,所以,要想测试的朋友,自行修改。
配置完成,接着重新启动服务。就以管理员服务调用用户服务为例。访问:http://localhost:9999/api/admin/v1.0/admin?userId=1 地址后,刷新Zipkin的管理界面。点击查找按钮。
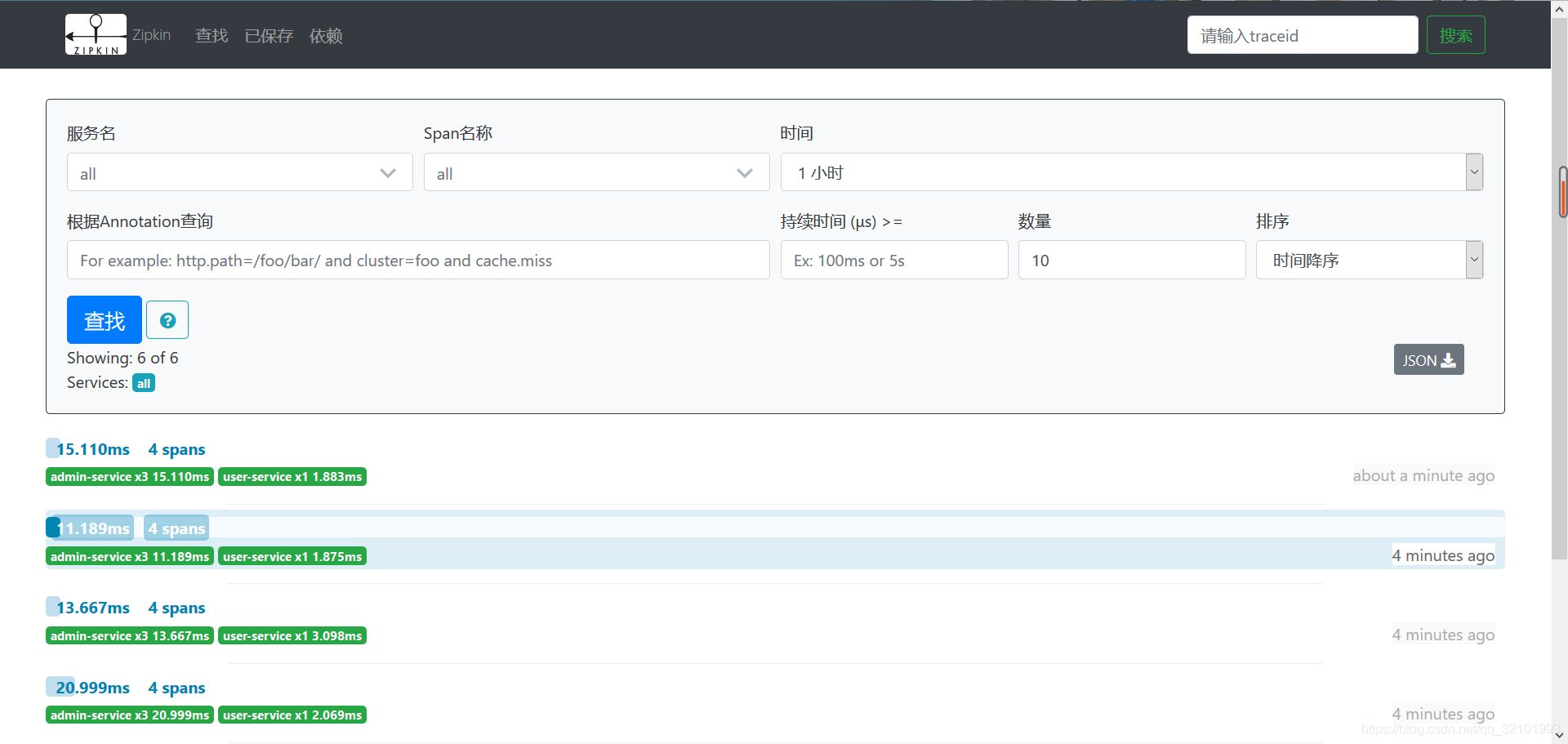
可以看到,上面显示了每次调用接口的记录,点进去就可以查看详细的信息。
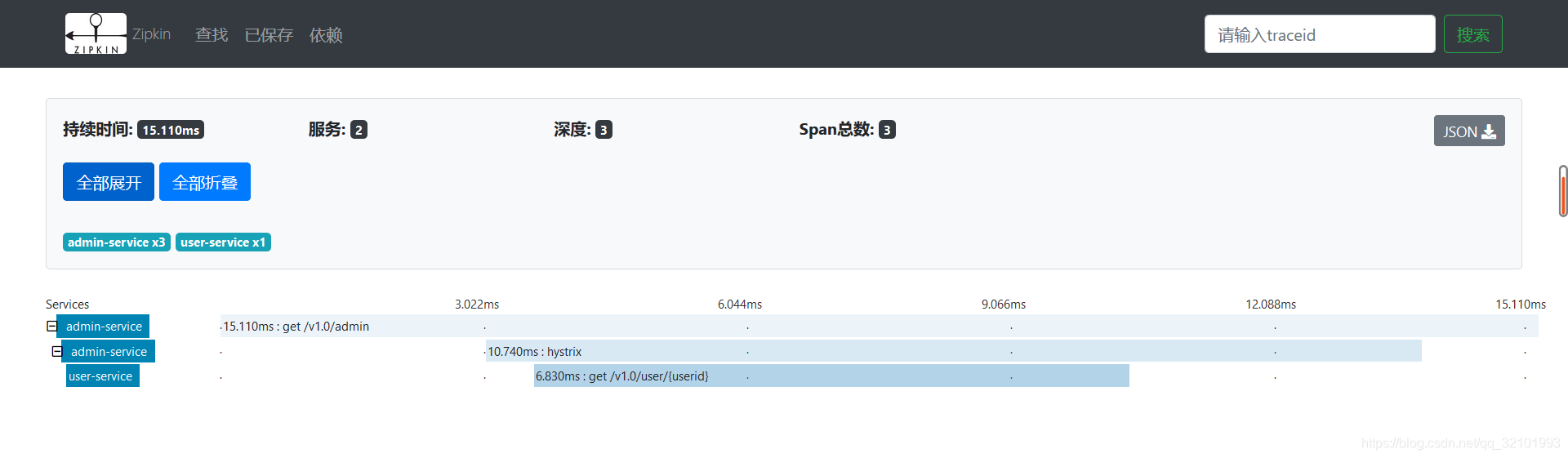
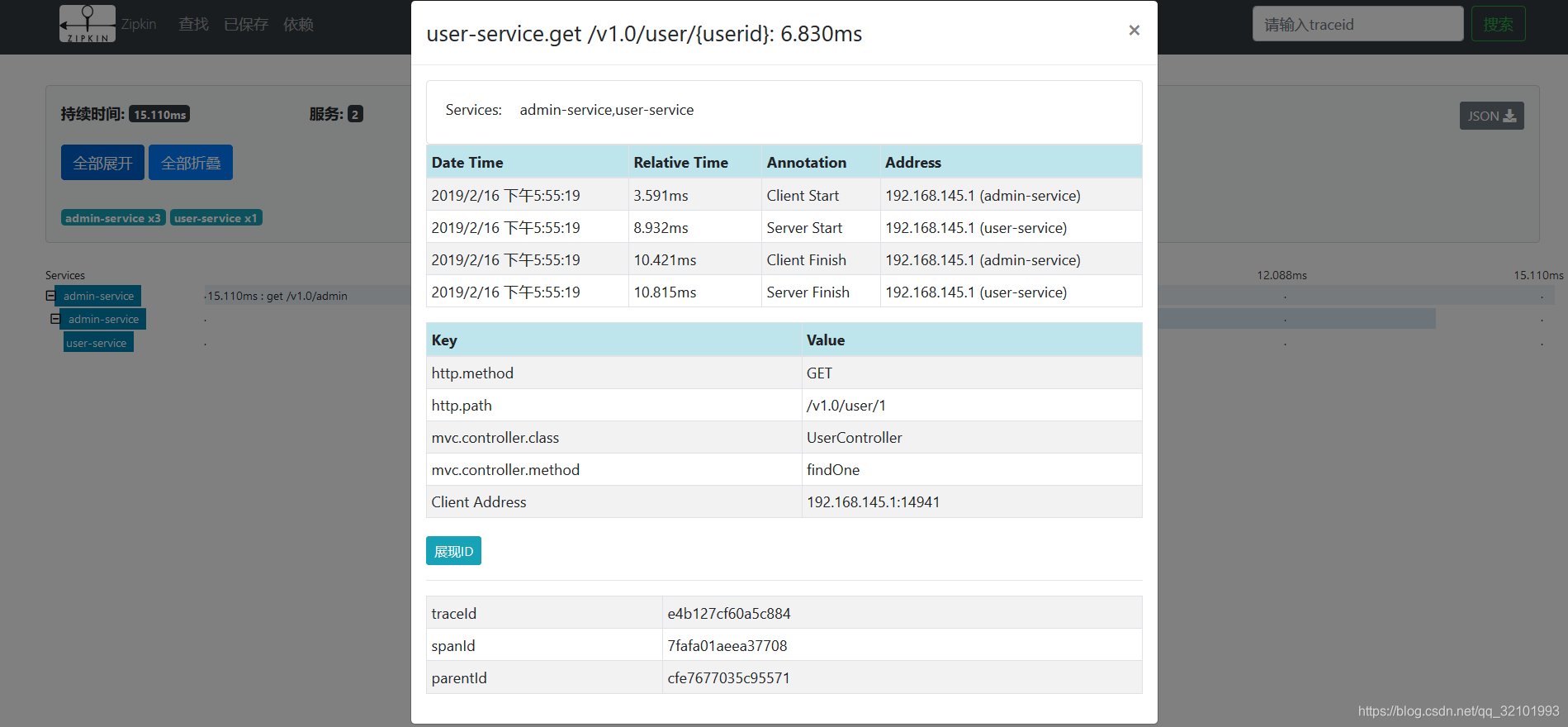
点击服务名称,可以看到请求耗时、请求方式、接口的路径、控制层的名称、方法名称、以及traceId和spanId。
不仅如此,还可以查看服务之间的依赖关系。
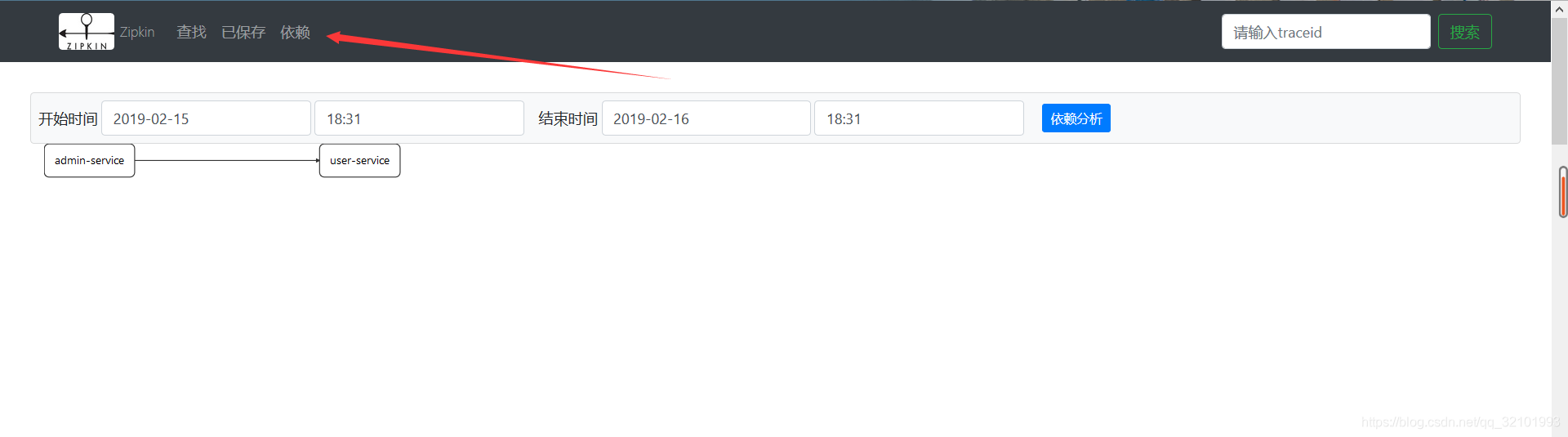
基本上Zipkin的基本使用就讲完了,知识点很零散。毕竟博主刚入猿圈不久,如果文章中出现了什么错误,希望各位猿友指出。
工作996,生病ICU