为什么使用好索引可以优化性能
因为无论是在Innodb还是在mysiam里面,他们底层的数据都是存放在.idb或者.mdb文件夹里面,当没有索引的时候,他们遍历表里面的每一行数据,无论是IO还是CPU使用率都会占用比较高,导致性能问题,而使用索引,可以通过索引获取到对应的内存地址,迅速地查找到数据,如图:
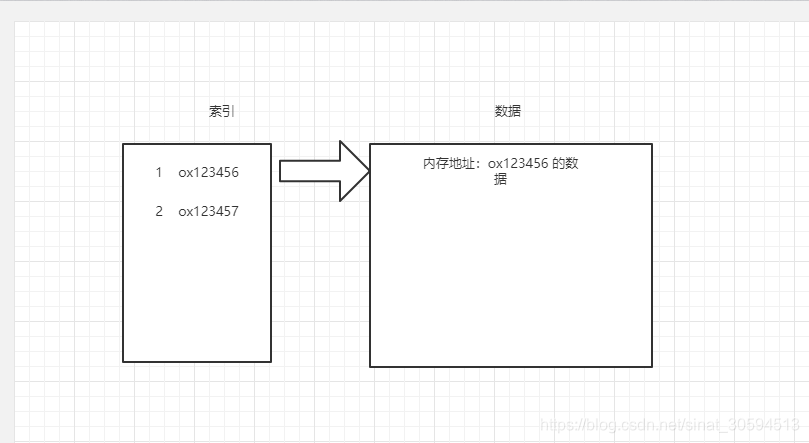
MySQL性能优化的关键是索引:
在MySQL的存储引擎中,Innodb和mysiam使用的索引的底层数据结构都是B+Trees
思考为什么Innodb和mysiam索引底层使用的数据结构是B+Trees,不是使用红黑树?
数据结构超链接:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
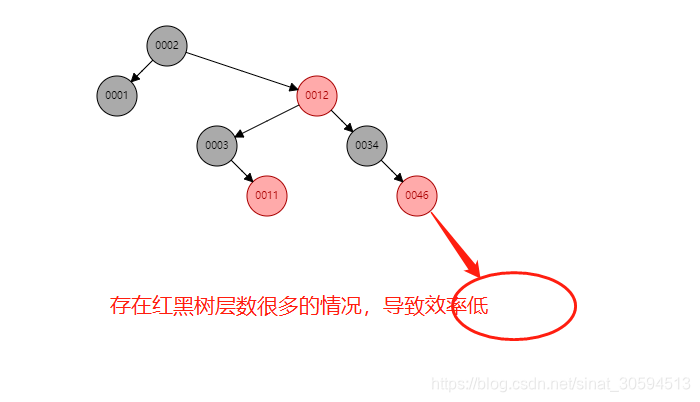
如果使用红黑树,数据量很大,层数就会很多,效率会降低:
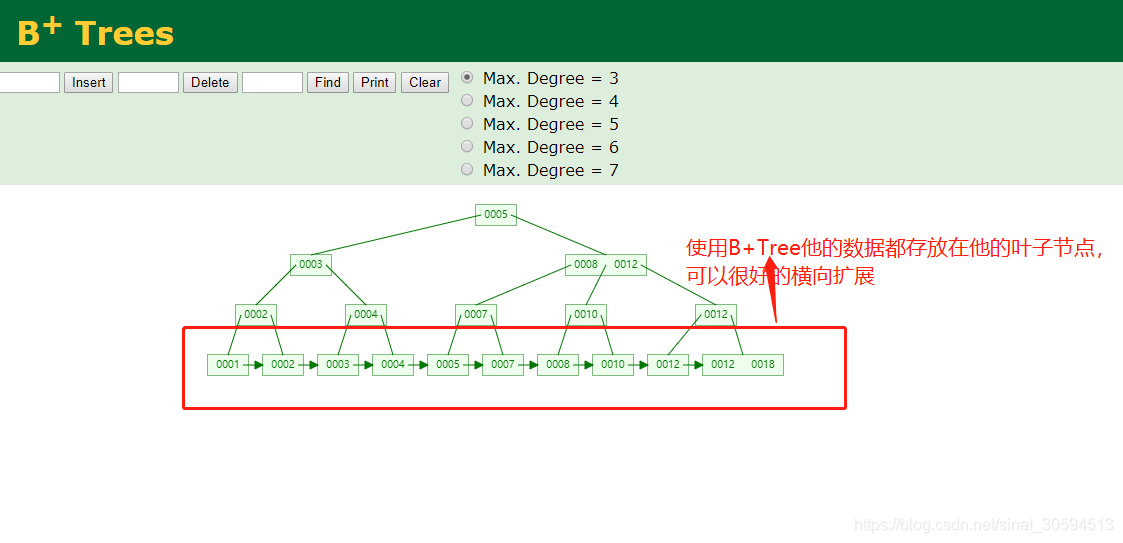
而使用B+Trees的话,他的数据都会存放在叶子节点那里,中间点都是key
分析在mysiam里面的索引的原理
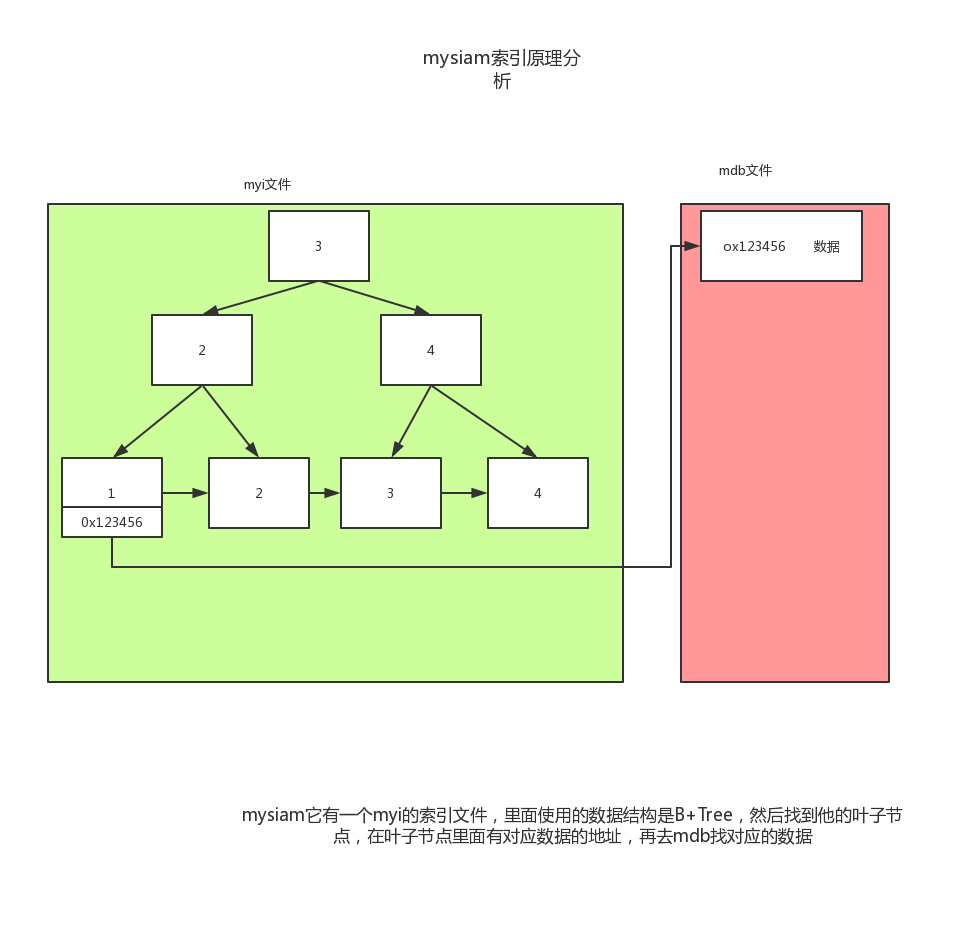
简要说明一下:mysiam是非聚集索引的,他的数据和索引是分开的,通过索引找他的内存地址,再去mdb里面找对应的数据
分析Innodb里面的索引原理(叶子节点忘记加箭头)
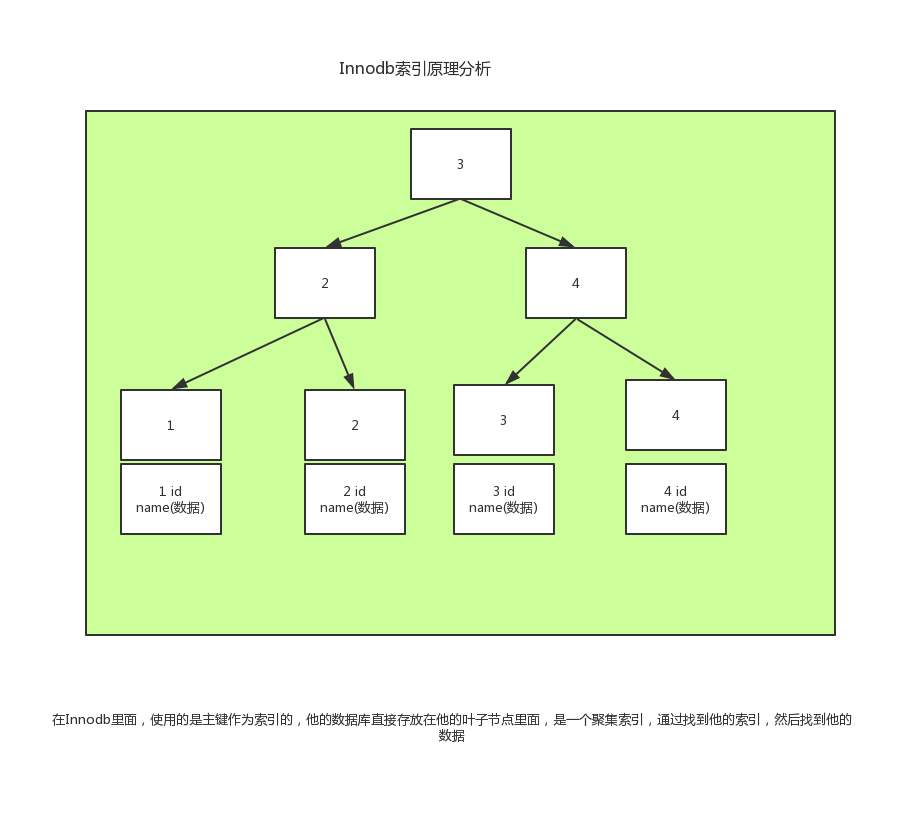
讨论分析对比使用自增ID和uuid做主键的对比:
1.使用字符串做主键ID产生的B+Trees
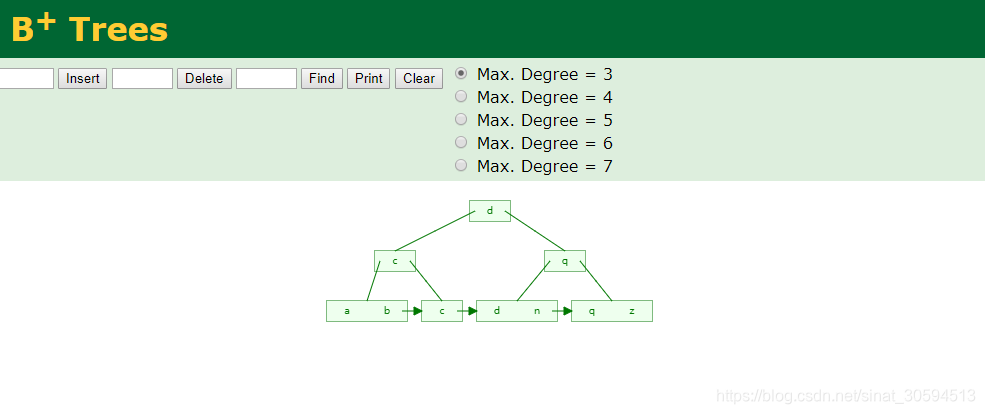
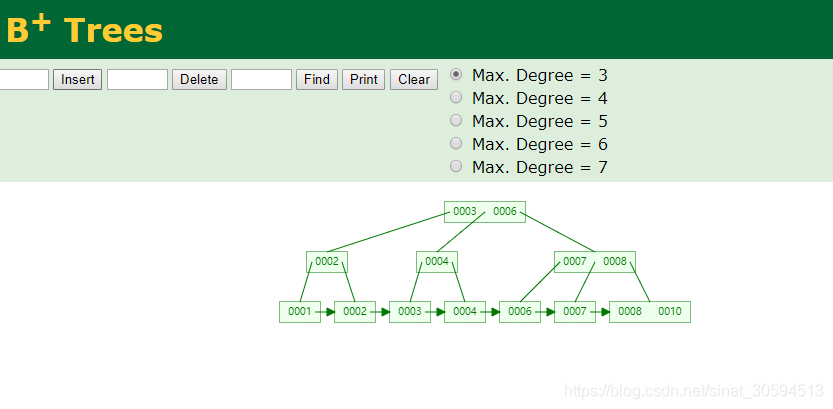
字符串做主键(uuid)差生的B+Trees在内存里面比较零散,不会一块内存填满之后在填下一块
而使用自增ID,与uuid相反
在Innodb里面使用副索引的原理分析(叶子节点忘记加箭头)
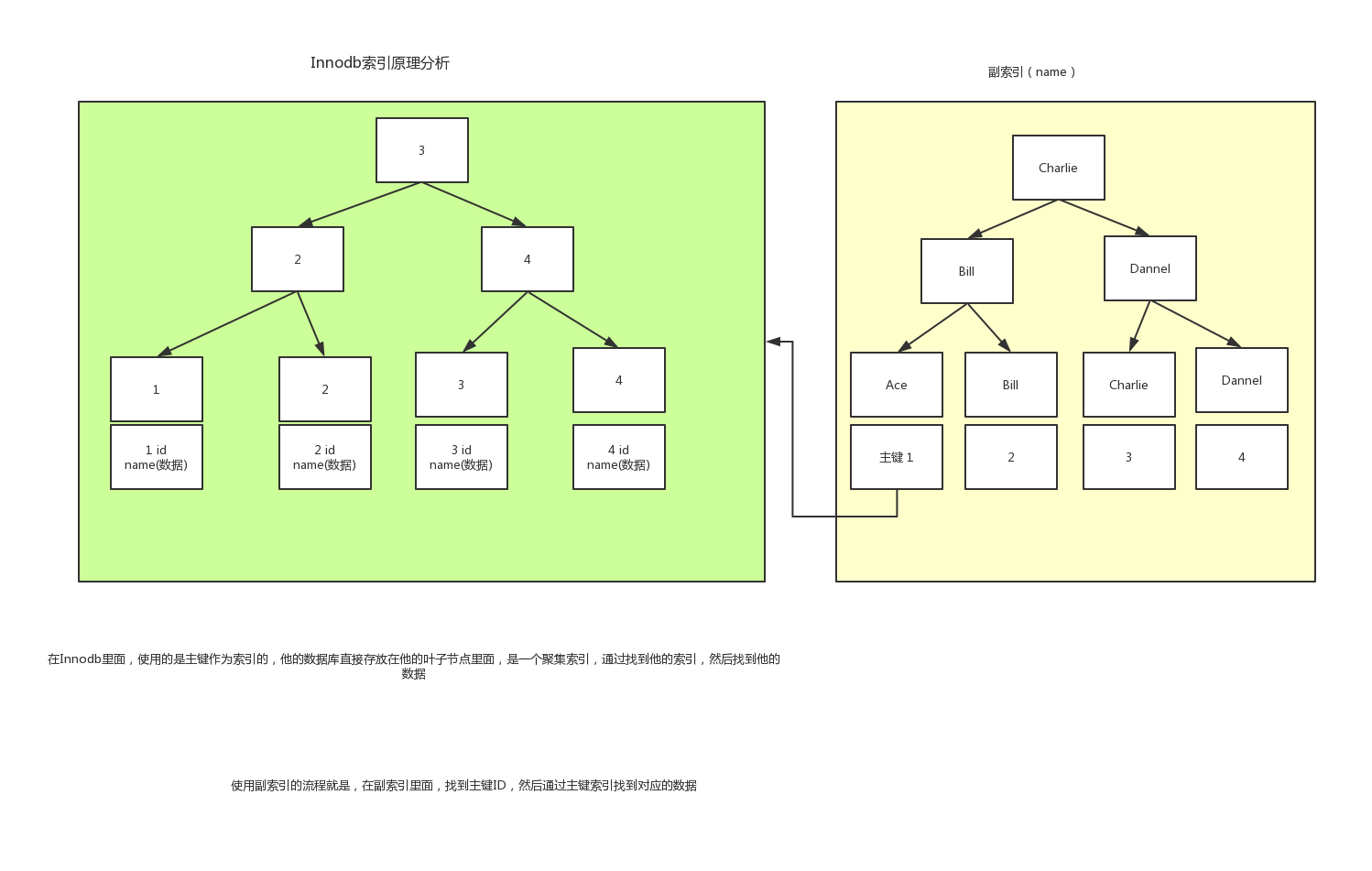
简要说明:使用副索引,找到主键,同通过主键索引找到主键数据
联合索引的原理分析和怎么使用较好
分析:联合主键有点类似于使用副索引,但是他是先看第一个,按照第一个排序的
例如使用id age
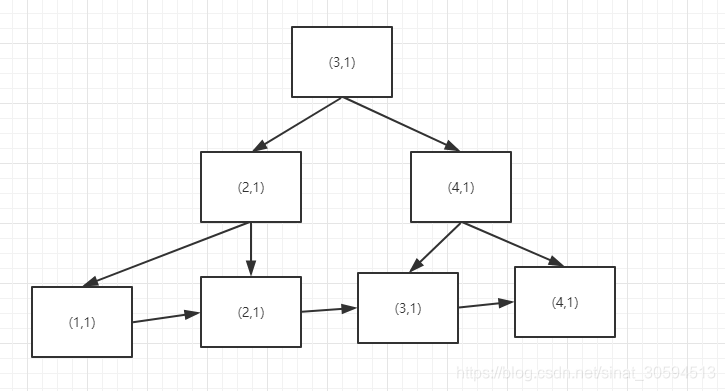
所以在使用联合索引的时候,写sql,要注意左边最好的原则,但是使用第二索引有排序有事,因为第一索引已经分好里面同一组的数据
使用索引的缺点是什么:、
1.就是插入数据的时候,由于需要添加索引数据,导致效率会变低,会带来一定的CPU和IO的开销,
2.当多个索引的时候,建议使用联合索引来降低索引的数量,但是要注意sql的最左最好原则