目录
一、hadoop
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The project includes these modules:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
二、HDFS
- 扩展性&容错性&海量数据存储
- 将文件切分成指定大小的数据块,并以多副本的存储在多个机器上
- 数据切分、多副本、容错等操作对用户是透明的
先对某个文件进行拆分,每个块128M
2.1 什么是HDFS
- Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS
- 源自于Google的GFS论文
2.2 设计目标
- 非常巨大的分布式文件系统
- 运行在廉价的硬件上
- 易扩展、为用户提供性能不错的文件存储服务
2.3 HDFS架构
- 1个Master(NameNode /NN) 带 N个Slaves(DataNode/DN)
1个文件会被拆分成多个Block
blocksize:128M(CDH默认)
130M ==》2个block :128M和2M
2.3.1NN:
- 负责客户端请求的响应
- 负责元数据(文件的名称、副本系数、block存放的DN)的管理
2.3.2DN:
- 存储用户文件对应的数据块(Block)
- 要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康情况
A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software.
NN+多个DN
建议NN和DN部署在不同的节点上
三、YARN
- YARN(Yet Another Resource Negotiator)
- 负责整个集群的资源的管理和调度
- 扩展性&容错性&多框架资源统一调度
3.1Yarn产生背景
MapReduce1.X(单点故障,节点压力大不易扩展)
JobTracker:
负责资源管理和作业调度
TaskTracker:
定期向JT汇报本节点的健康状况、资源使用情况、作业执行情况
接收来自JT的命令:启动任务/杀死任务

资源利用率&运维成本

3.2 yarn产生
yarn:不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度
XXX on YARN 的好处:与其他计算框架共享集群资源,按资源需要分配,进而提高集群资源的利用率
XXX:Spark/MapReduce/Storm/Flink

3.3 Yarn的架构:
http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
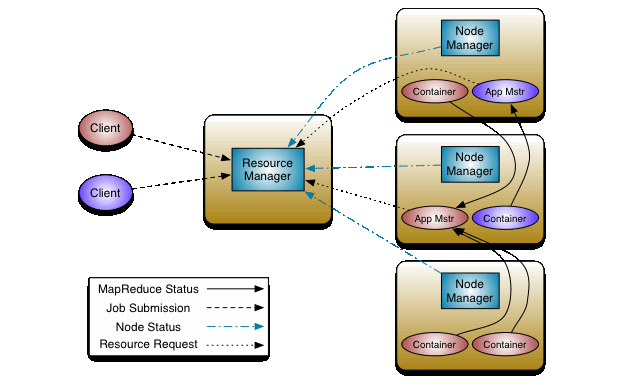
1)ResourceManager (RM)
整个集群同一时间提供服务的1RM只有一个,负责集群资源的统一管理和调度
处理客户端的请求:提交一个作业,杀死一个作业
监控我们的NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉我们的AM来如何处理(如重启)
2) NodeManager (NM)
整个集群中有多个,负责自己本身节点资源管理和使用
定时向RM汇报本节点的资源使用情况
接收并处理来自RM的各种命令:启动Container
处理来自AM的命令
单个节点的资源管理
3) ApplicationMaster (AM)
每个应用程序对应一个:MR、Spark、负责应用程序的管理
为应用程序向RM申请资源(core、memory),分配给内部task
需要与NM通信:启动/
停止task,task试运行在container里面,AM也是运行在container里面
4) Container
封装了CPU、Memory等资源的一个容器
是一个任务运行环境的抽象
5) Client
提交作业
查看作业的运行进度
杀死作业
四、MapReduce
扩展性&容错性&海量数据离线处理(延时比较大)
4.1MapReduce概述



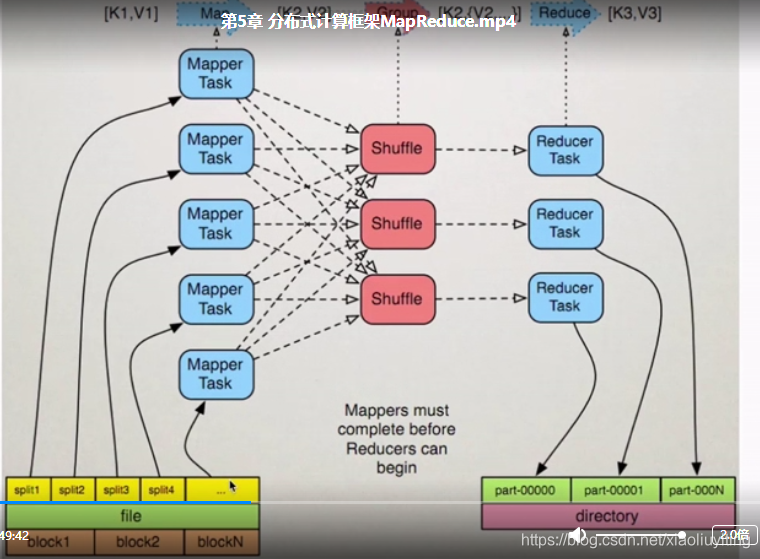
4.2MapReduce编程模型
MapReduce架构






MapReduce编程


combiner不适用于平均数

五、hadoop优势
1、高可靠性
数据存储:数据块多副本
数据计算:重新调度作业计算
2、高扩展性
存储计算资源不够时,可以横向的线性扩展机器
一个集群中可以包含数以千计的节点
3、其他
存储在廉价机器上降低成本
成熟的生态圈
狭义的Hadoop
是一个适合大数据分布式存储(HDFS),分布式计算(MapReduce),资源调度(YARN)的平台
广义的hadoop
指的是Hadoop生态系统,Hadoop生态系统是一个很庞大的概念,hadoop是其中最重要的一个部分;生态系统中的
每一个子系统只解决某一个特定的问题域,不搞统一型的一个全能系统,而是小而精的多个小系统
六、Zookeeper
分布式的协调服务
七、Flume
八、sqoop

九、离线数据处理流程


