10小时入门大数据(二)------初识Hadoop
Hadoop官网地址:http://hadoop.apache.org/
一、Hadoop介绍
开源、分布式存储+分布式计算平台
二、Hadoop能做什么
- 搭建大型数据仓库、PB级数据存储、处理、分析、统计等
- 搜索引擎:从海量的数据中筛选出用户所需要的数据
- 日志分析:是目前大数据技术最主流的应用场景,因为数据挖掘、分析大部分都是基于日志的
- 商业智能:数据是人工智能的燃料,通过海量的数据能够训练出比较好的机器学习模型
- 数据挖掘:从海量的数据中挖掘出有价值的数据,为公司提供效益,实现数据变现,就像是挖矿一样
三、核心组件之分布式文件系统HDFS
特点:扩展性、容错性、海量数据存储
将文件分成指定大小的数据块并以多副本的存储在多个机器上
数据切分、多副本、容错等操作对用户是透明的
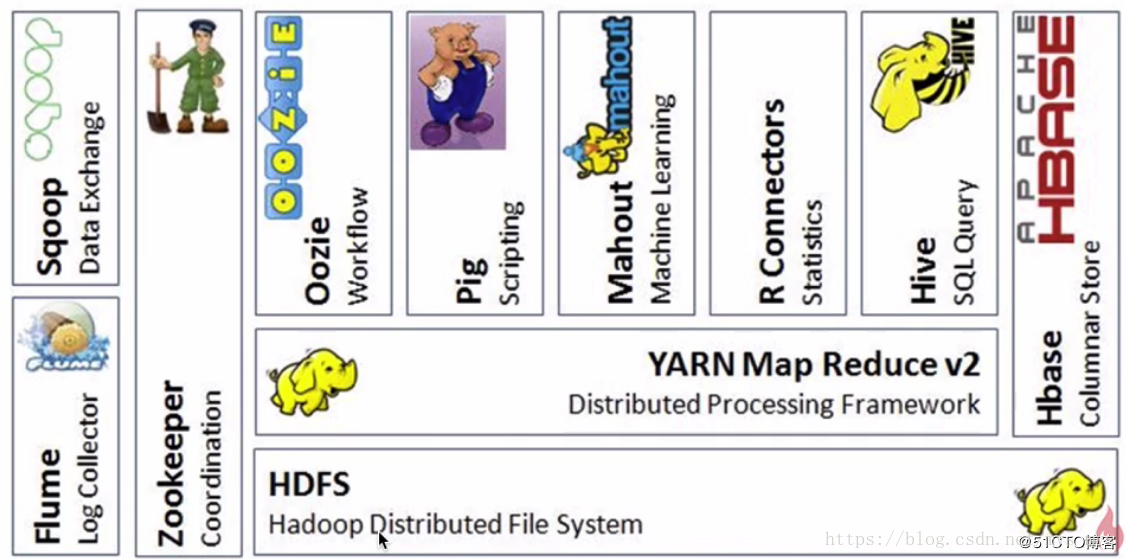
四、Hadoop框架包含的模块
- Hadoop Common:通用的模块,是包含着其他Hadoop模块的一个通用模块
- Hadoop Distributed File System (HDFS):分布式文件系统,提供一个对应用程序数据的高通量访问的分布式文件系统,简称HDFS
- Hadoop YARN:用于作业调度与集群资源管理的框架
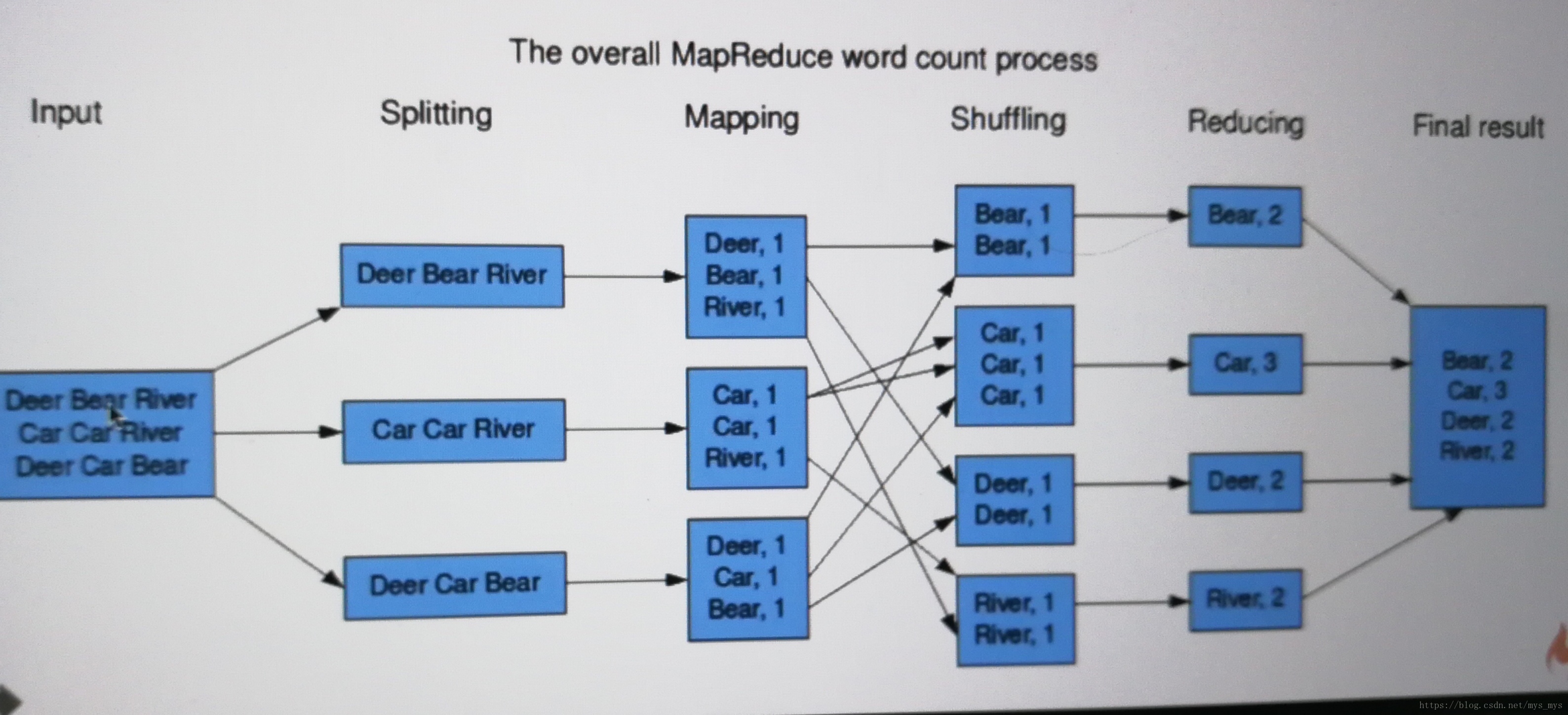
- Hadoop MapReduce:基于YARN的大数据量并行处理系统,也就是实现分布式计算的框架
五、Hadoop核心组件之HDFS
HDFS特点:
- 扩展性:可以直接水平扩展,机器不够用时,直接增加机器即可
- 容错性:以多副本的方式存储在多个节点上
- 海量数据存储:将文件切分成指定大小的数据块并以多副本的存储在多个机器上,默认的数据块大小是128M
- 数据切分、多副本、容错等操作对用户是透明的,用户无需关注底层的数据切分
六、Hadoop核心组件之资源调度系统YARN
YARN:Yet Another Resource Negotiator
负责整个集群资源的管理和调度
特点:扩展性、容错性、多框架资源统一调度
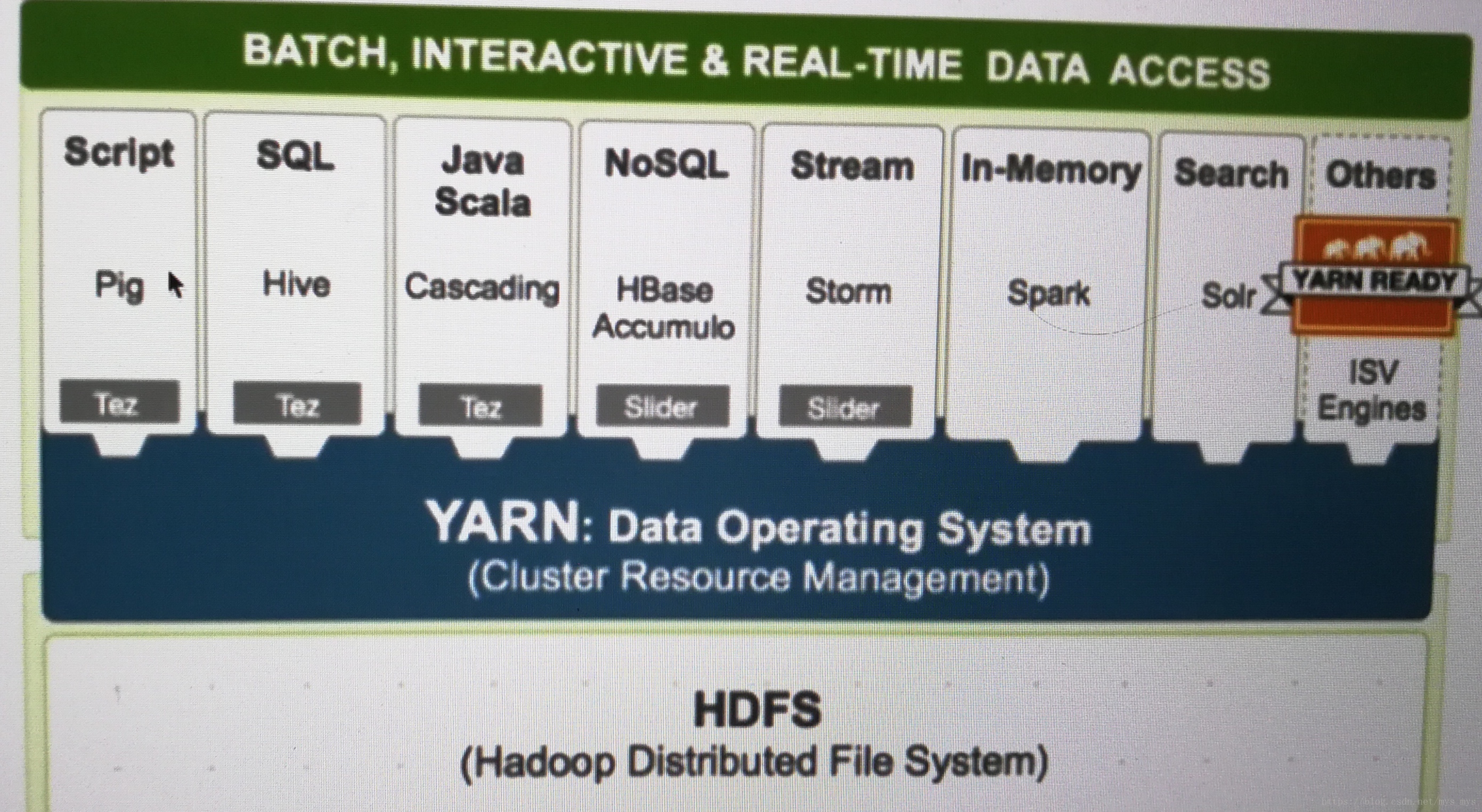
七、、Hadoop核心组件之分布式计算框架MapReduce
MapReduce特点:
扩展性、容错性、海量数据离线处理
八、Hadoop发展史
Hadoop十年解读与发展预测
九、Hadoop优势
1)高可靠性
- 数据存储:数据块多副本
- 数据计算:重新调度作业计算
2)展性:存储、计算资源不够时,可以横向的线性扩展机器
- 一个集群可以包含数以干计的节点
3)其他
- 存储在廉价机器上,降低成本
- 成熟的生态圈
十、Hadoop生态圈
1)狭义的Hadoop与广义的Hadoop:
扫描二维码关注公众号,回复:
3559492 查看本文章

- 狭义的Hadoop:是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台,也就是Hadoop框架
- 广义的Hadoop:指的是Hadoop生态系统,Hadoop生态系统是一个很庞大的概念,Hadoop框架是其中最重要最基础的一个部分。生态系统中的每一子系统只解决某一个特定的问题域(甚至可能很窄),不搞统一型的一个全能系统,而是小而精的多个小系统。
2)Hadoop生态系统的特点:
- 开源以及社区活跃
- 包括了大数据数理的方方面面
- 成熟的生态圈
3)Hadoop常用发行版及选型
- 原生态的Apache Hadoop
- CDH:Cloudera Distributed Hadoop
- HDP:Hortonworks Data Platform
注:选择版本的时候尽量保持一致,例如hive选择了cdh5.7.0的话,那么其他框架也要选择cdh5.7.0,不然有可能会发生jar包的冲突。