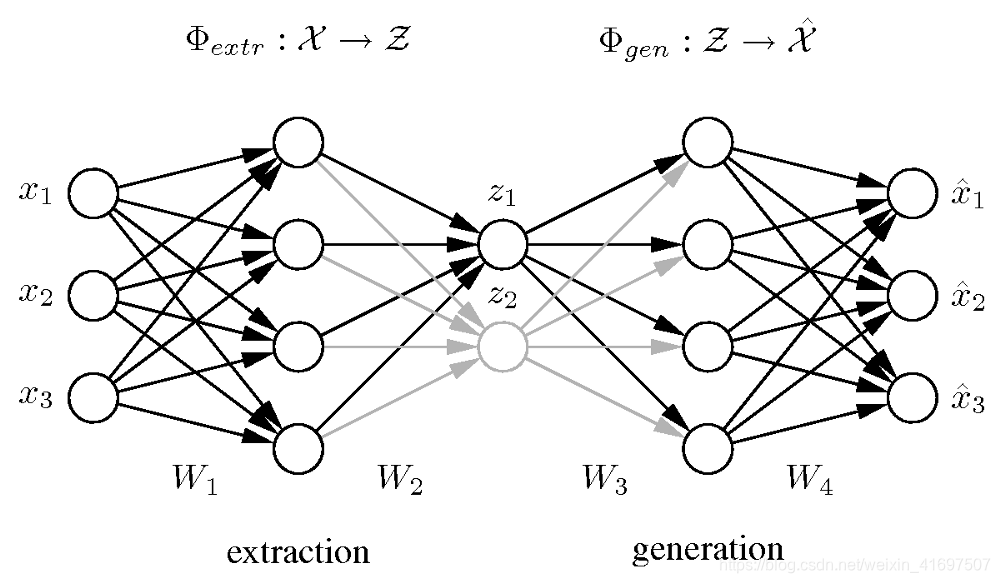
This is a generic, practical approach that can be applied to most machine learning problems:

下一步是对问题进行分类。
按输入分类:如果是标记数据,则是监督学习问题。 如果它是用于查找结构的未标记数据,那么这是一个无监督的学习问题。 如果解决方案意味着通过与环境交互来优化目标函数,那么这就是强化学习问题。
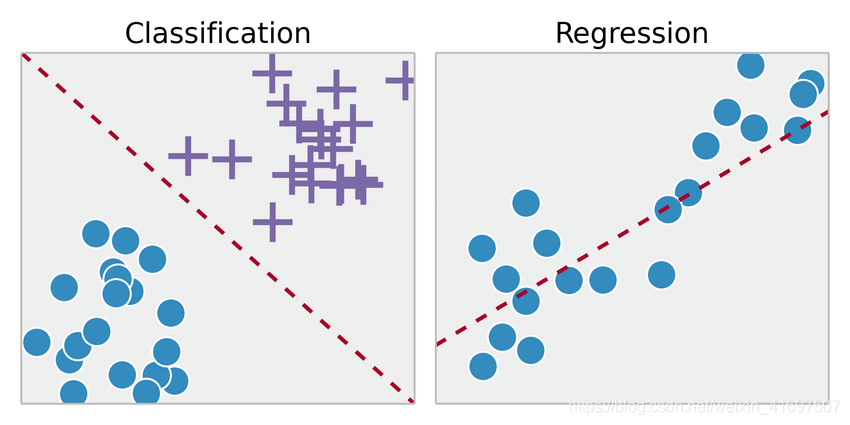
按输出分类:如果模型的输出是数字,那就是回归问题。 如果模型的输出是一个类,那就是分类问题。 如果模型的输出是一组输入组,则这是一个聚类问题。
数据本身不是最终游戏,而是整个分析过程中的原材料。 成功的公司不仅可以捕获并访问数据,而且还能够获得能够推动更好决策的洞察力,从而实现更好的客户服务,竞争优势和更高的收入增长。 理解数据的过程在为正确的问题选择正确算法的过程中起着关键作用。 一些算法可以使用较小的样本集,而其他算法则需要大量和大量的样本。 某些算法使用分类数据,而其他算法则使用数字输入。
在此步骤中,有两个重要任务是使用描述性统计数据理解数据,并通过可视化和绘图来理解数据。
数据处理的组件包括预处理,分析,清理,它通常还涉及将来自不同内部系统和外部源的数据汇总在一起。
将数据从原始状态转换为适合建模的状态的传统思想是特征工程适用的地方。转换数据和特征工程实际上可能是同义词。 这是后一概念的定义。 特征工程是将原始数据转换为更能代表预测模型的基础问题的特征的过程,从而提高了对看不见的数据的模型准确性。
在对问题进行分类并理解数据之后,下一个里程碑是确定在合理的时间内适用且实用的算法。 影响模型选择的一些因素是:
-
模型的准确性。
-
模型的可解释性。
-
模型的复杂性。
-
模型的可扩展性。
-
构建,培训和测试模型需要多长时间?
-
使用该模型进行预测需要多长时间?
-
模型是否符合业务目标?
-
4-Implement machine learning algorithms.
设置机器学习管道,使用一组精心选择的评估标准比较数据集上每个算法的性能。 另一种方法是在不同的数据集子组上使用相同的算法。 对此的最佳解决方案是执行一次或运行服务,在添加新数据时间隔执行此操作。
优化超参数,网格搜索,随机搜索和贝叶斯优化有三种选择。
机器学习任务的类型
监督学习之所以如此命名,是因为人类可以作为指导教授算法应该得出什么结论。 监督学习要求算法的可能输出已知,并且用于训练算法的数据已经标记有正确的答案。 如果输出是实数,我们称任务回归。 如果输出来自有限数量的值,这些值是无序的,那么它就是分类。
无监督的机器学习与某些人称之为真正的人工智能的方式更为一致 - 计算机可以学习如何识别复杂的过程和模式而无需人工提供指导。 关于物体的信息较少,特别是火车组没有标记。 可以观察到对象组之间的一些相似性,并将它们包含在适当的簇中。 有些对象可能与所有集群有很大不同,这样这些对象就会异常。

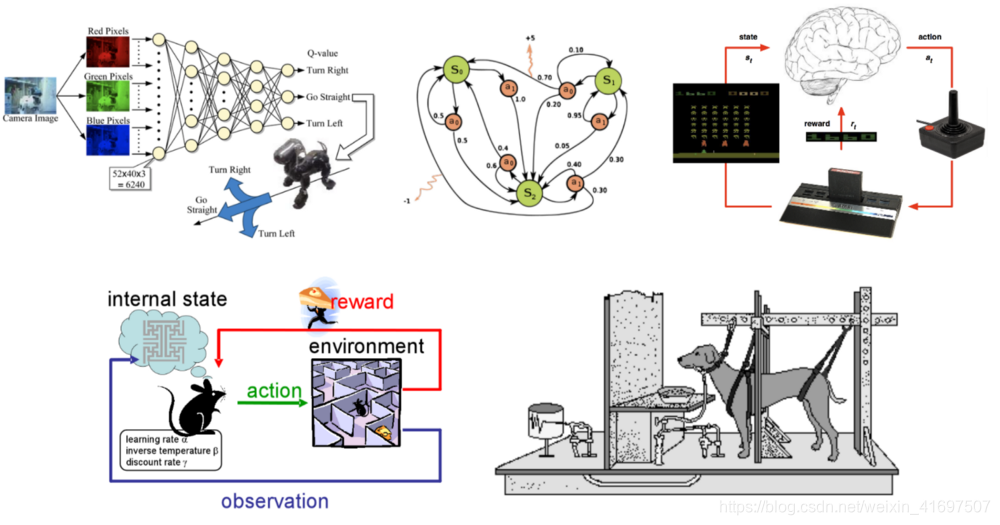
强化学习是指面向目标的算法,它学习如何在多个步骤中实现复杂目标或沿特定维度最大化。 例如,通过多次移动最大化游戏中赢得的积分。 它与监督学习的不同之处在于,在监督学习中,训练数据具有关键作用,因此模型用正确答案本身训练,而在强化学习中,没有答案,但强化剂决定如何做 执行给定的任务。 在没有训练数据集的情况下,必然要从其经验中学习。
-
Commonly used machine learning algorithms
-
1-线性回归
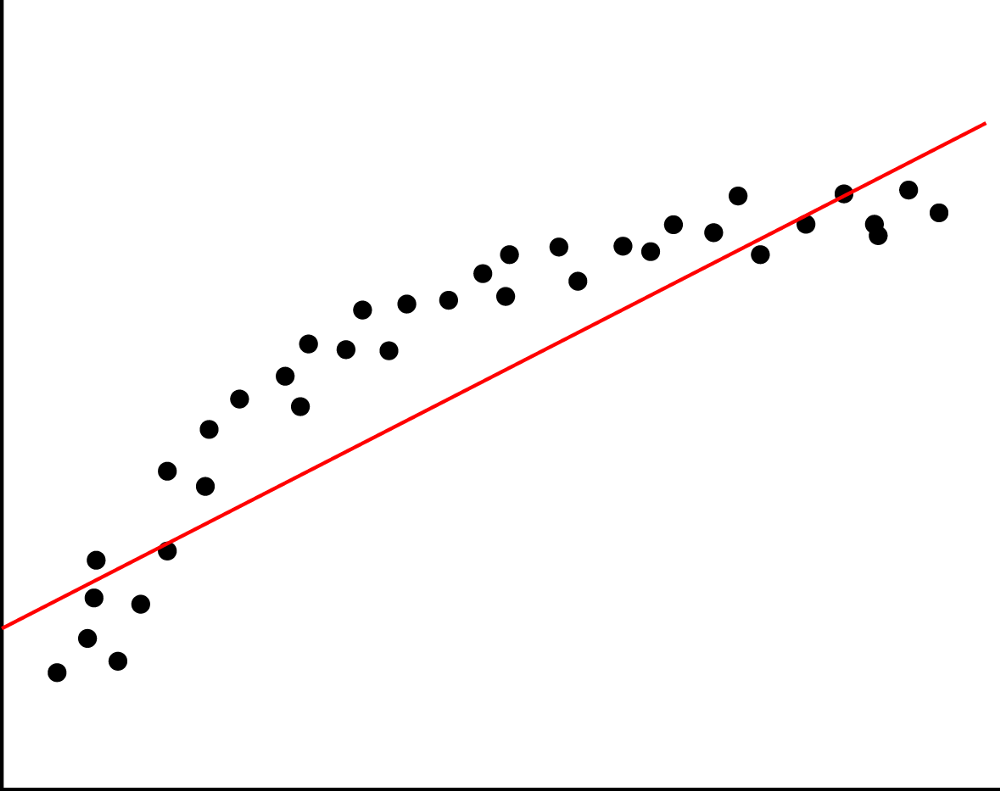
线性回归是一种统计方法,可以汇总和研究两个连续(定量)变量之间的关系:一个变量,表示为X,被视为自变量。表示为y的另一个变量被视为因变量。线性回归使用一个自变量X来解释或预测因变量y的结果,而多元回归使用两个或多个自变量根据损失函数预测结果,如均方误差(MSE)或平均绝对误差( MAE)。因此,无论何时告诉您预测当前正在运行的流程的未来价值,您都可以使用回归算法。尽管这种算法很简单,但是当有数千个特征时,它可以很好地工作,例如,在自然语言处理中有一袋词或n-gram。更复杂的算法会过度拟合许多特征而不是庞大的数据集,而线性回归则提供了不错的质量。但是,如果功能多余,则不稳定。
-
2-Logistic回归
不要将这些分类算法与回归方法混淆,以便在标题中使用回归。 Logistic回归执行二进制分类,因此标签输出是二进制的。 当输出变量是分类时,我们也可以将逻辑回归视为线性回归的一个特例,其中我们使用赔率对数作为因变量。 什么是逻辑回归真棒? 它采用线性特征组合并对其应用非线性函数(sigmoid),因此它是神经网络的一个小实例!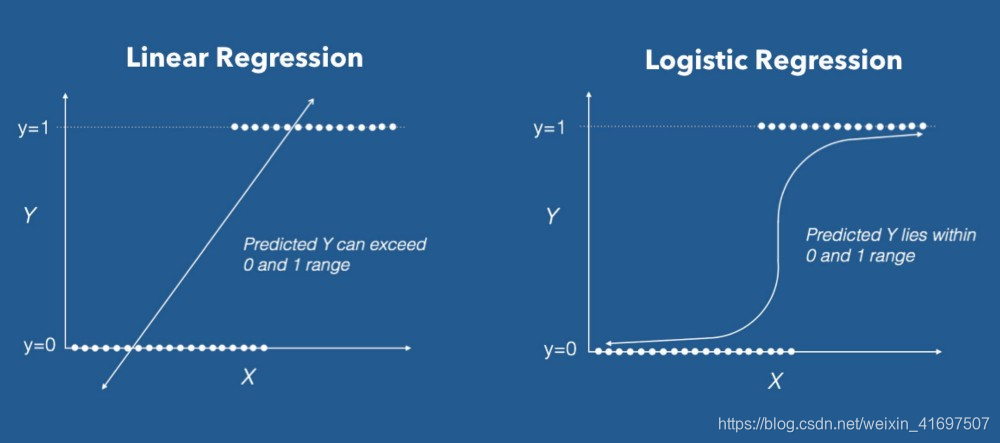
-
#3-K-means
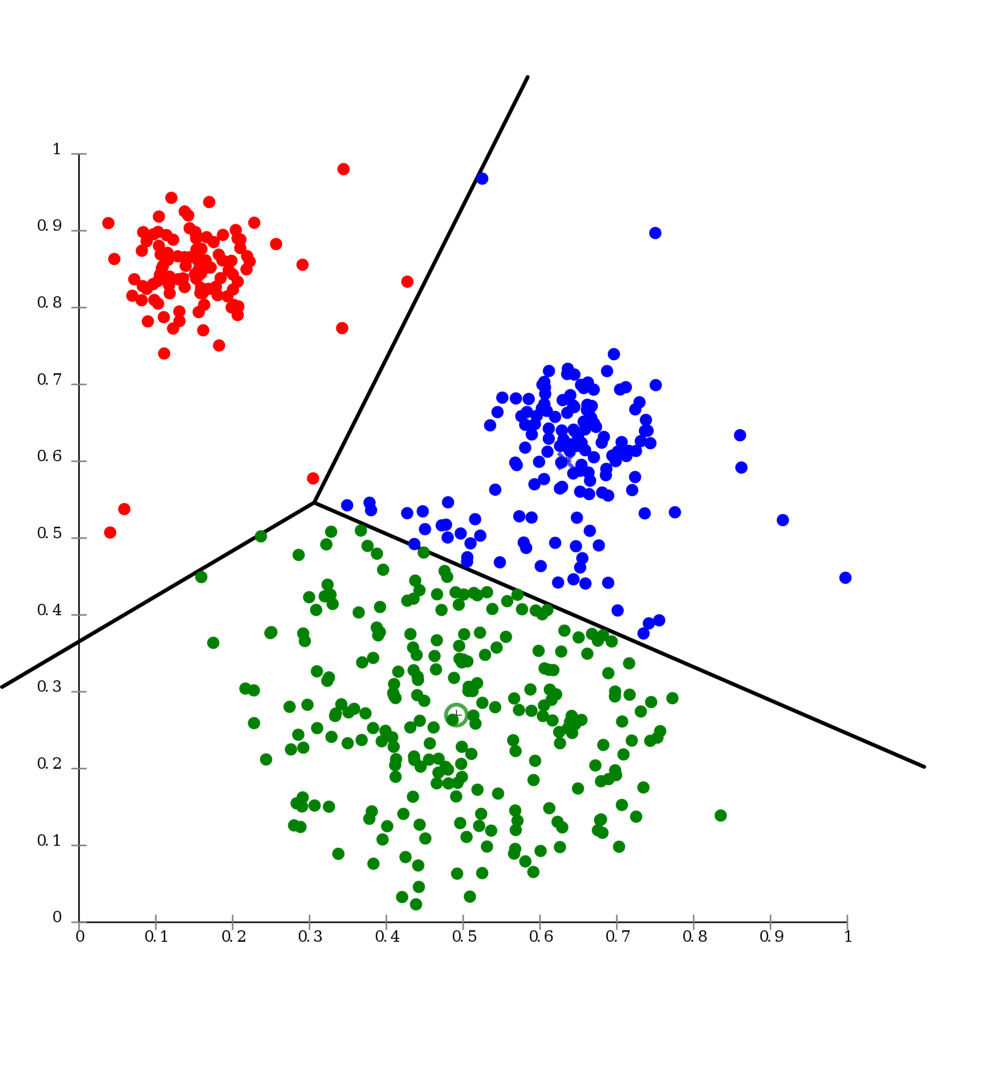
假设您有很多数据点(水果的测量值),并且您想将它们分成苹果和梨两组。 K均值聚类是一种聚类算法,用于自动将大组划分为更小的组。
之所以出现这个名称是因为您在我们的示例K = 2中选择了K个组。您可以取这些组的平均值来提高组的准确性(平均值等于平均值,您可以多次执行此操作)。群集只是群组的另一个名称。
假设你有13个数据点,实际上是7个苹果和6个梨,(但你不知道这个),你想把它们分成两组。对于这个例子,让我们假设所有梨都比所有苹果都大。您选择两个随机数据点作为起始位置。然后,将这些点与所有其他点进行比较,找出最接近的起始位置。这是你在聚类上的第一次传递,这是最慢的部分。
你有你的初始组,但因为你随机选择,你可能不准确。假设你在一组中有六个苹果和一个梨,在另一组中有两个苹果和四个梨。因此,您可以将一个组中所有点的平均值用作该组的新起点,并对另一个组执行相同操作。然后再次进行群集以获取新组。
成功!因为平均值更接近每个群集的大多数,所以在第二个群集中,您将所有苹果放在一个群组中,所有梨子放在另一个群集中。你怎么知道你做完了?您执行平均值并再次执行组,并查看是否有任何点更改了组。没有,所以你完成了。否则,你会再去。
- #4-KNN
直奔,两人寻求完成不同的目标。 K-最近邻是分类算法,其是监督学习的子集。 K-means是一种聚类算法,它是无监督学习的一个子集。
如果我们有足球运动员的数据集,他们的位置和他们的测量数据,并且我们想要在我们有测量但没有位置的新数据集中为足球运动员分配位置,我们可能使用K-最近邻居。
另一方面,如果我们有足球运动员的数据集需要根据相似性分组为K个不同的组,我们可能会使用K-means。相应地,K在每种情况下也意味着不同的东西!
在K-最近邻居中,K表示在确定新玩家位置时投票的邻居的数量。检查K = 5的示例。如果我们有一个新的足球运动员需要一个位置,我们将数据集中的五个足球运动员与最接近我们的新足球运动员的测量值进行对比,我们让他们对我们应该分配新球员的位置进行投票。
在K-means中,K表示我们最终想要拥有的簇数。如果K = 7,那么在我的数据集上运行算法后,我将拥有七个足球运动员群体或不同的群体。最后,两种不同的算法有两个非常不同的目的,但事实上它们都使用K可能会非常混乱。

- #5-支持向量机
SVM使用超平面(直线)来分隔两个不同标记的点(X和O)。 有时这些点不能被直接的东西分开,所以它需要将它们映射到更高维度的空间(使用内核!),在那里它们可以被直接的东西分开(超平面!)。 这看起来像原始空间上的曲线,即使它在更高维度的空间中确实是一个直线的东西!

-
#6-随机森林
假设我们想知道何时投资宝洁,那么基于过去一个月的几个数据,我们有三个选择买入,卖出和持有,如开盘价,收盘价,价格和成交量的变化
想象一下,你有很多条目,900点数据。
我们希望建立一个决策树来决定最佳策略,例如,如果股票价格的变化比前一天高出10%,那么我们购买该股票的数量就会很高。 但我们不知道使用哪些功能,我们有很多。
因此,我们采用随机的一组度量和随机抽样的训练集,并构建决策树。 然后我们使用不同的随机测量集和每次随机数据样本多次进行相同的操作。 最后,我们有许多决策树,我们使用它们来预测价格,然后根据简单多数决定最终预测。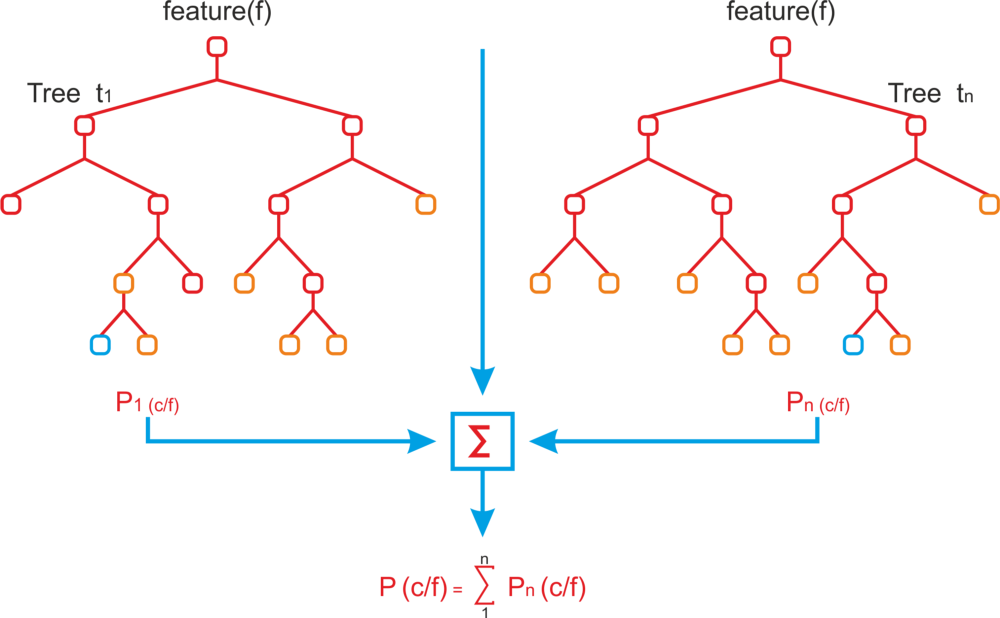
-
#7-神经网络
神经网络是一种人工智能。 神经网络背后的基本思想是模拟计算机内部大量密集互连的脑细胞,使其能够学习东西,识别模式,并以类似人的方式做出决策。 关于神经网络的惊人之处在于,它不需要对其进行编程就可以明确地学习:它可以自己学习,就像大脑一样!
一方面是神经网络,就有输入。 这可能是图片,无人机的数据或Go板的状态。 另一方面,有神经网络想要做的输出。 在它们之间,它们之间有节点和连接。 连接的强度决定了根据输入调用的输出。