目录

1. 数据载入与总览
1.1 数据加载
#绘图工具
import matplotlib.pyplot as plt
%matplotlib inline
#数据处理工具
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#数据路径自己指定,本案例数据路径就在当前文件夹下面子文件夹usa_elect中
contb1 = pd.read_csv('./usa_elect/contb_01.csv')
contb2 = pd.read_csv('./usa_elect/contb_02.csv')
contb3 = pd.read_csv('usa_elect/contb_03.csv')
1.2 数据集成
#axis = 0 表示在行方向进行集成
contb = pd.concat([contb1,contb2,contb3],axis = 0)
1.3 数据预览
#查看前5行数据
contb.head()

字段解释:
cand_nm :候选人姓名
contbr_nm : 捐赠人姓名
contbr_st :捐赠人所在州
contbr_employer : 捐赠人所在公司
contbr_occupation : 捐赠人职业
contb_receipt_amt :捐赠数额(美元)
contb_receipt_dt : 捐款的日期
#查看数据形状
contb.shape
输出:(1001733, 7)
说明数据共计1001733行数据,共7列属性
#该方法查看数据总览
#查看数据的信息,包括每个字段的名称、非空数量、字段的数据类型等
contb.info()
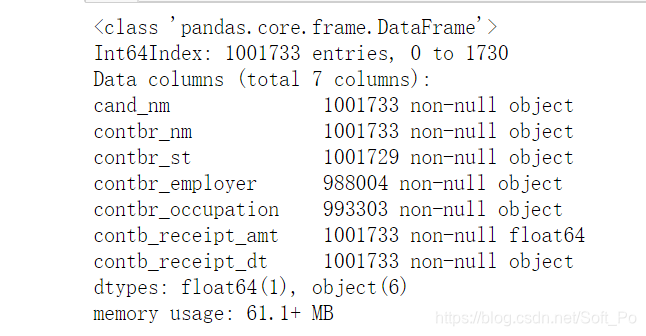
通过info我们可以知道contbr_employer和contbr_occupation与contbr_st存在空数据
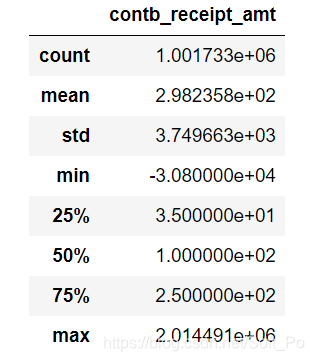
#用统计学指标快速描述数值型属性的概要
contb.describe()
2. 数据预处理
2.1 空值处理
#属性contbr_employer存在空数据,有可能因为忘记填写或者保密等等原因
#使用fillna方法填充固定值:NOT PROVIDE
contb['contbr_employer'].fillna('NOT PROVIDE',inplace = True)
#对属性contbr_occupation职业进行数据填充
contb['contbr_occupation'].fillna('NOT PROVIDE',inplace = True)
#对属性contbr_st进行数据填充
contb['contbr_st'].fillna('NOT PROVIDE',inplace = True)
此时我们的数据contb已经不存在空数据了
2.2 数据变换
2.2.1 字典映射进行转换:党派分析
#通过搜索引擎等途径,获取到每个总统候选人的所属党派,建立字典parties,候选人名字作为键,所属党派作为对应的值
parties = {'Bachmann, Michelle': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'Huntsman, Jon': 'Republican',
'Johnson, Gary Earl': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Obama, Barack': 'Democrat',
'Paul, Ron': 'Republican',
'Pawlenty, Timothy': 'Republican',
'Perry, Rick': 'Republican',
"Roemer, Charles E. 'Buddy' III": 'Republican',
'Romney, Mitt': 'Republican',
'Santorum, Rick': 'Republican'}