Deep-Q-learning
1,Q-Learning与深度学习结合思路
q-table存在一个问题,真实情况的state可能无穷多,这样q-table就会无限大,解决这个问题的办法是通过神经网络实现q-table。输入state,输出不同action的q-value。
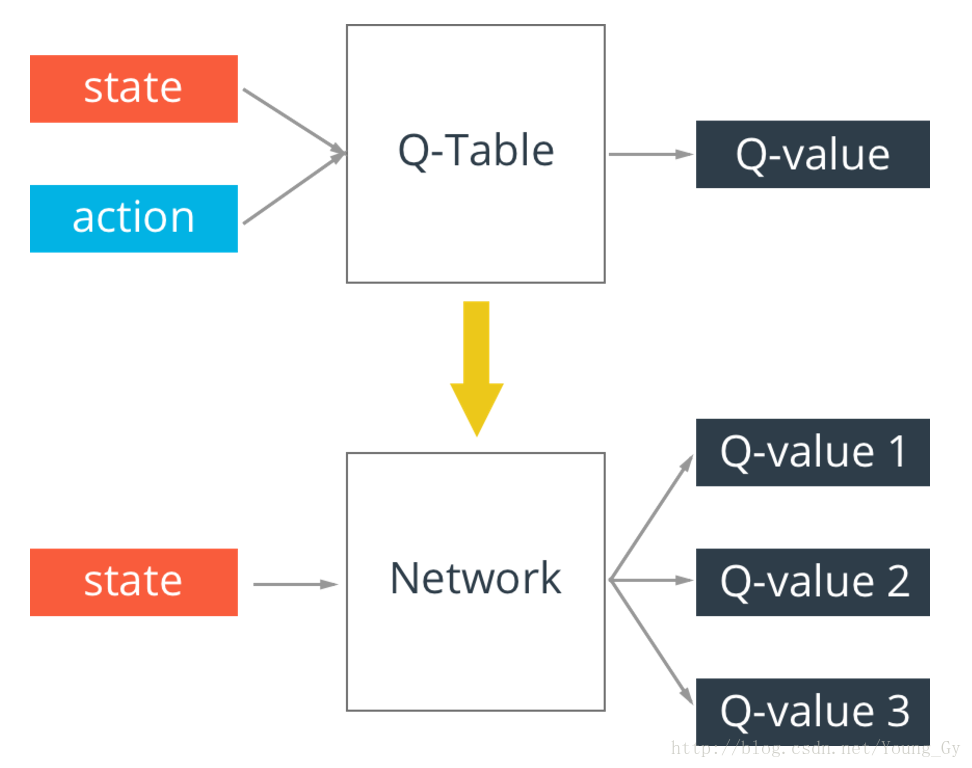
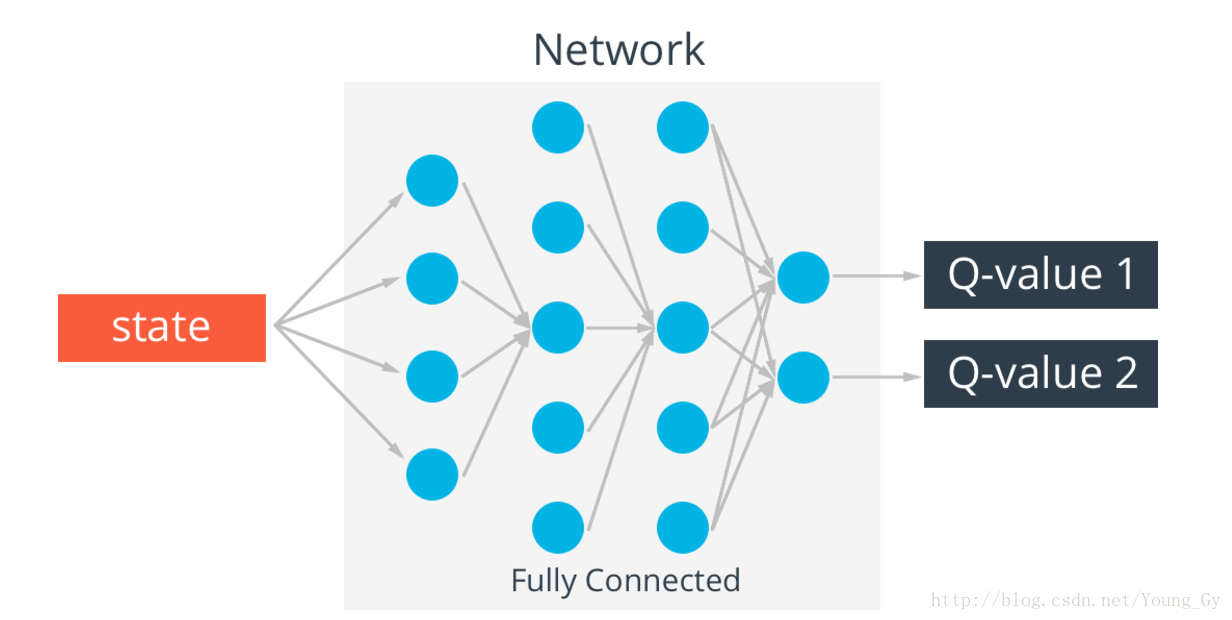
Q-Learning与神经网络结合使用就是 Deep Q-Network,简称 DQN。在现实中,状态的数量极多,并且需要人工去设计特征(状态的特征),而且一旦特征设计不好,则得不到想要的结果。
神经网络正是能处理解决这个问题(状态数量太多,且状态特征难以设计),取代原来 Q 表的功能。
当神经网络与Q-Learning结合使用的时候,又会碰到几个问题:
(1).loss 要怎么计算?
增强学习是试错学习(Trail-and-error),由于没有直接的指导信息,智能体要以不断与环境进行交互,通过试错的方式来获得最佳策略。
Q-Learning正是其中的一种,所以Q值表中表示的是当前已学习到的经验。而根据公式计算出的 Q 值是智能体通过与环境交互及自身的经验总结得到的一个分数(即:目标 Q 值)。
最后使用目标 Q 值(target_q)去更新原来旧的 Q 值(q)。
而目标 Q 值与旧的 Q 值的对应关系,正好是监督学习神经网络中结果值与输出值的对应关系。
所以,loss = (target_q - q)^2
即:整个训练过程其实就是 Q 值(q)向目标 Q 值(target_q)逼近的过程。
(2).训练样本哪来?
在 DQN 中有 Experience Replay 的概念,就是经验回放。
就是先让智能体去探索环境,将经验(记忆)池累积到一定程度,在随机抽取出一批样本进行训练。
为什么要随机抽取?因为智能体去探索环境时采集到的样本是一个时间序列,样本之间具有连续性,如果每次得到样本就更新Q值,受样本分布影响,会对收敛造成影响。
Experience replay
强化学习由于state之间的相关性存在稳定性的问题,解决的办法是在训练的时候存储当前训练的状态到记忆体MM,更新参数的时候随机从MM中抽样mini-batch进行更新。
具体地,MM中存储的数据类型为 <s,a,r,s′><s,a,r,s′>,MM有最大长度的限制,以保证更新采用的数据都是最近的数据。
Exploration - Exploitation
- Exploration:在刚开始训练的时候,为了能够看到更多可能的情况,需要对action加入一定的随机性。
- Exploitation:随着训练的加深,逐渐降低随机性,也就是降低随机action出现的概率。
2,模拟流程
1.随机初始化一个状态 s,初始化记忆池,设置观察值。
2.循环遍历(是永久遍历还是只遍历一定次数这个自己设置):
(1)根据策略选择一个行为(a)。
(2)执行该行动(a),得到奖励(r)、执行该行为后的状态 s`和游戏是否结束 done。
(3)保存 s, a, r, s`, done 到记忆池里。
(4)判断记忆池里的数据是否足够(即:记忆池里的数据数量是否超过设置的观察值),如果不够,则转到(5)步。
① 在记忆池里随机抽取出一部分数据做为训练样本。
② 将所有训练样本的 s`做为神经网络的输入值,进行批量处理,得到 s`状态下每个行为的 q 值的表。
③ 根据公式计算出 q 值表对应的 target_q 值表。
公式:Q(s, a) = r + Gamma * Max[Q(s`, all actions)]
④ 使用 q 与 target_q 训练神经网络。
(5)判断游戏是否结束。
① 游戏结束,给 s 随机设置一个状态,再执行(1),(2),(3),(4)。
① 未结束,则当前状态 s 更新为 s`(意思就是当前的状态变成 s`,以当前的 s`去action,得到r,得到执行该行为后的状态 s`和游戏是否结束 done)。