摘要
话不多说我们先上需求
模拟登录丁香园,并抓取论坛页面所有的人员基本信息与回复帖子内容。
丁香园论坛:http://www.dxy.cn/bbs/thread/626626#626626 。
这个任物有一个知识点 就是cookies 的使用下面我们来介绍一下cookies 是什么
Cookie 是您造访过的网站所建立的档案,可储存您的浏览资讯,提供您更流畅方便的网路使用体验。启用 Cookie 后,网站就可让您保持登入状态、记住您的网站偏好设定,并提供您与所在地相关的内容。
Cookie 分为以下两类:
第一方 Cookie 是由您浏览的网站所建立,也就是网址列中所显示的网站。
第三方 Cookie 是由其他网站所建立。这类网站通常是在您浏览的网站上提供部分内容 (例如广告或图片)
的其他网站。
根据上面的解释 我们可以知道cookies是用来储存我们浏览器的浏览资讯,那我们该如何找到带有登陆资讯的cookies呢??请仓考以下流程:
- 打开chrome
- 连接到目标网站 并完成登陆
- 登陆成功之后F12 叫出工程人员模式 之后按F5

找到network并选取XHR标签
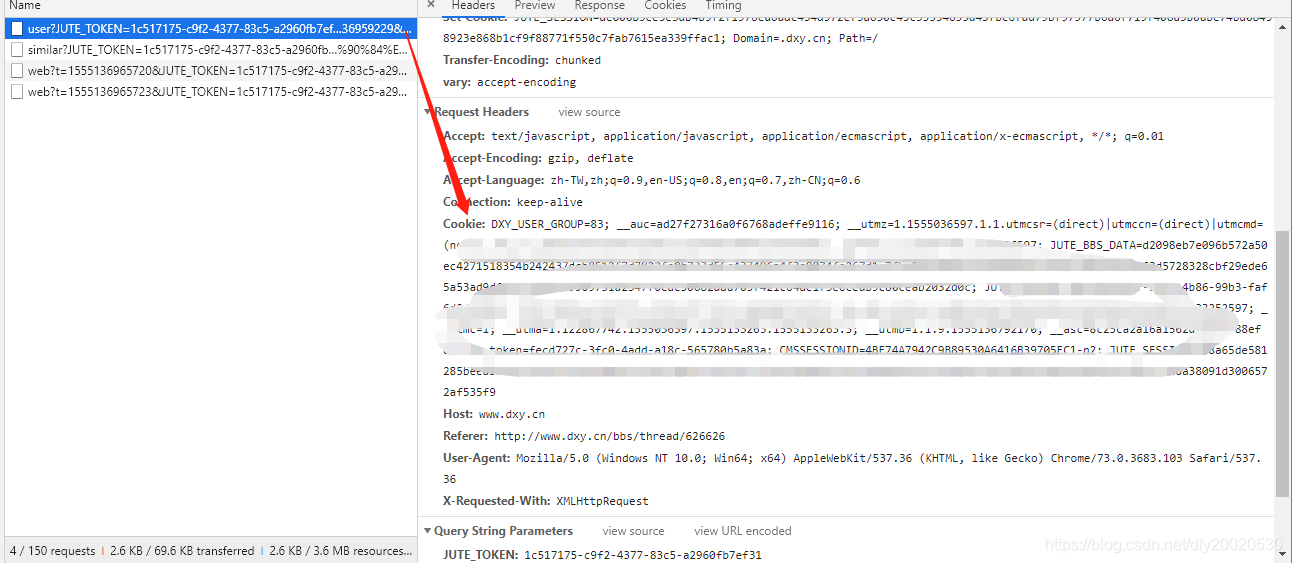
之后找到这里的cookie 就是我们的目标了 复制下来 在requests 里面添加cookies
cookies = {
'cookie': '你的cookies'
}
url = 'http://www.dxy.cn/bbs/thread/626626#626626'
req = requests.get(url, cookies=cookies) #
完整代码请参考实作
实作
import requests
from bs4 import BeautifulSoup
import selenium
class Taks7:
def __init__(self):
pass
def get_info(self):
data = {}
data2 = {}
cookies = {
'cookie': 'your cookie'
}
url = 'http://www.dxy.cn/bbs/thread/626626#626626'
req = requests.get(url, cookies=cookies) #
soup = BeautifulSoup(req.text, 'html.parser')
title = soup.find('title')
data['title'] = title.text
author_say_tags = soup.find('meta', attrs={'property': "og:description"})
author_say_tag = author_say_tags.attrs
author_say = author_say_tag['content']
details = soup.find_all('div', attrs={'class': 'info clearfix'})
user_atten = soup.find_all('div', attrs={'class': 'user_atten'})
auth_name = soup.find_all('div', attrs={'class': "auth"})
data['author_say'] = author_say
recoverys = soup.find_all('td', attrs={'class': "postbody"})
for i in range(len(recoverys)):
data['auth_name'] = auth_name[i].text
data['user_atten'] = user_atten[i].text.strip().split()
data['info_clearfix'] = details[i].text.replace('\n', '')
data['recovery'] = recoverys[i].text.strip()
print(data)
a = Taks7().get_info()