Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介
网站爬虫由浅入深:慢慢来
分析:

链接的URL分析:

数据格式:
爬虫基本架构模型:
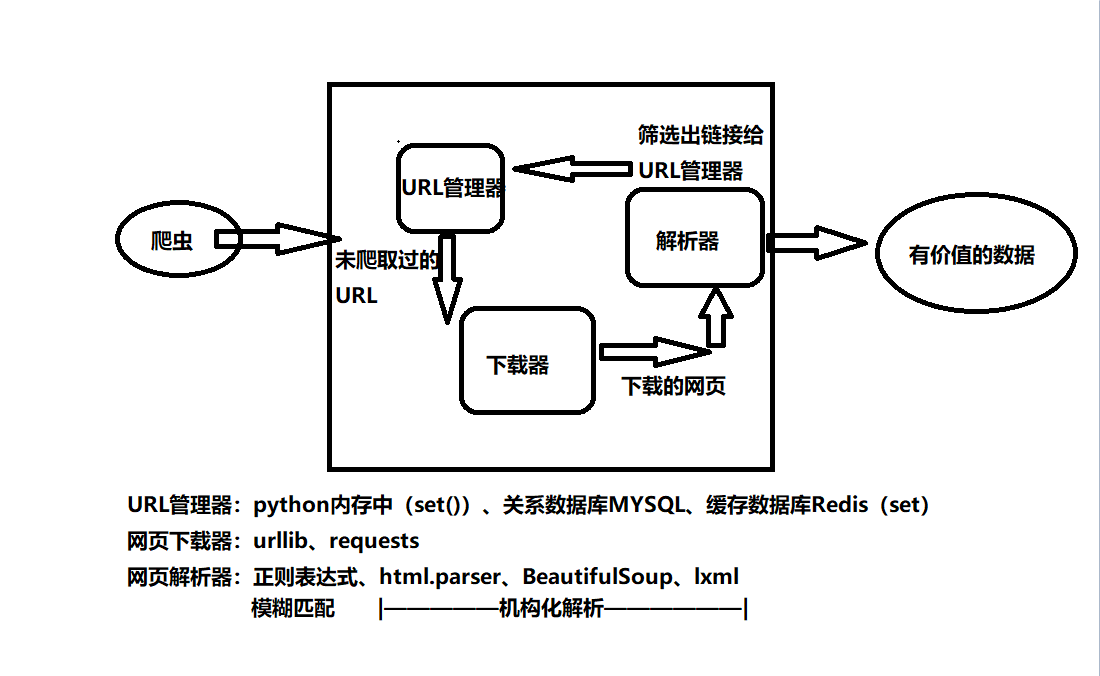
本爬虫架构:

源代码:
# coding:utf8
# author:Jery
# datetime:2019/4/12 19:22
# software:PyCharm
# function:爬取百度百科关键词python1000个相关网页——标题和简介
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup
class SpiderMain(object):
def __init__(self):
self.urls = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.outputer = DataOutputer()
# 主爬虫,调度四个类的方法执行爬虫
def crawl(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("crawl 第{} :{} ".format(count, new_url))
html_content = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_content)
# 新网页的url及数据
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 1000:
break
count += 1
except:
print(" crawl failed! ")
self.outputer.output_html()
# URL管理器,实现URL的增加与删除
class UrlManager:
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url)
# 下载网页源代码
class HtmlDownloader:
def download(self, url):
if url in None:
return
response = urlopen(url)
if response.getcode() != 200:
return
return response.read()
# 下载网页所需内容
class HtmlParser:
def parse(self, page_url, html_content):
if page_url is None or html_content is None:
return
soup = BeautifulSoup(html_content, 'lxml', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
links = soup.find_all('a', href=re.compile(r'/view/.*'))
for link in links:
new_url = "https://baike.baidu.com" + link['href']
new_urls.add(new_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
# <dl class="lemmaWgt-lemmaTitle lemmaWgt-lemmaTitle-">
# <dd class="lemmaWgt-lemmaTitle-title">
# <h1>Python</h1>
title_node = soup.find("dl", {"class": "lemmaWgt-lemmaTitle lemmaWgt-lemmaTitle-"}).dd.h1
res_data['title'] = title_node.get_text()
summary_node = soup.find('div', {"class": "lemma-summary"})
res_data['summary'] = summary_node.get_text()
return res_data
# 将所搜集数据输出至html的表格中
class DataOutputer:
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
output = open('output.html', 'w')
output.write("<html>")
output.write("<body>")
output.write("<table>")
for data in self.datas:
output.write("<tr>")
output.write("<td>{}</td>".format(data['url']))
output.write("<td>{}</td>".format(data['title'].encode('utf-8')))
output.write("<td>{}</td>".format(data['summary'].encode('utf-8')))
output.write("</tr>")
output.write("</table>")
output.write("<body>")
output.write("</html>")
output.close()
if __name__ == '__main__':
root_url = "https://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.crawl(root_url)