- 回归:在建模的过程中需同时具备自变量x和因变量y,属于有监督的学习算法。输出变量为连续型。
- 主要介绍线性回归,岭回归和LASSO回归。
线性回归:
- 思想:误差项达到最小的转换为误差平方和最小(最小二乘法的思路)
- PYTHON的实现:stasmodels.api.formula.ols;predict(exog=None)
- 重点:
假设检验:f检验和t检验
f检验:p为变量,n为行,p和n-p-1分别为RSS和ESS的自由度。模型拟合得好,ESS就会越小,RSS则会越大,F统计量也会越大。当计算的F统计值大于F分布的理论值时拒绝原假设,即认为是显著的,即回归模型的偏回归系数都不全为0.
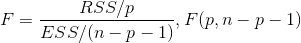
t检验:每个偏回归系数的t统计量由估计值coef和标准误差std err的商所得,每个统计量值都对应着概率值p,通常概率小于0.05时表示拒绝原假设,该自变量对因变量具有显著意义。
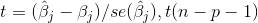
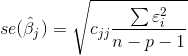
模型诊断:正态性,多重共线,线性相关,异常值,独立性
正态性:模型的前提是假设残差项服从正态分布,即要求因变量服从正态分布。具体方法,直方图,PP图,QQ图。statsmodels.api.ProbPlot。
多重共线性:由方差膨胀因子VIF鉴定,大于10,存在多重共线性,大于100,存在严重的多重共线性。存在时考虑删除变量/重新选择模型。statsmodels.stats.outliers_influence.variance_inflation_factor。
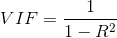
线性相关:确保用于建模的自变量和因变量之间存在线性关系。Pearson相关系数;散点图pairplot。相关系数大于0.8是高度相关。
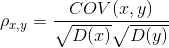
异常值:学生化残差:残差除以标准差之后的值。基于get_influence方法的resid_studentized_external,一般大于2的认为为异常值。
独立性检验:对因变量的独立性检验,Durbin-Watson,在2左右。
方差齐性检验:要求残差项的方差不随自变量的变动而呈现某种趋势。图形法;回归模型的预测。
岭回归:
- 思想:的到系数的前提是矩阵可逆,实际中会出现自变量个数多于样本量或者自变量间存在多重共线性的情况,会使行列式的结果为0或者近似为0,思路,在线性回归模型的目标函数上添加L2正则项(乘法项)。klearn.linear_model.Ridge。目标函数如下:

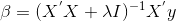
根据凸优化的相关知识,目标函数的最小化问题等价于:
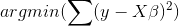
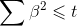
- 重要:确定lambda的值。可视化(sklearn.linear_model.Ridge,当回归系数随着lamda的值的增加二区域稳定的点);交叉验证(sklearn.linear_model.RidgeCV,均方误差)。


- tips:均方误差RMSE越小时模型的预测效果越好。sklearn.metrics.mean_squared_error;numpy.sqrt
Lasso回归:
- 思想:岭回归中添加的L2正则惩罚项,最终导致偏回归系数的缩减,但不管怎么缩减,无法降低模型的复杂度,而LASSO会将一些不重要的回归系数直接缩减为0。惩罚项中的平方改为了绝对值。由于在0处不可导,最小二乘法失效,使用坐标轴下降法,使函数在每个坐标轴上均达到最小值,则函数在全局上达到最小值。sklearn.linear_model.Lasso。
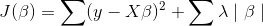
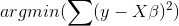
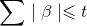
- 重要:确定lambda的值方法和岭回归一样也是可视化和交叉验证。sklearn.linear.Lasso;sklearn.linear.LassoCV。


- tips:和岭回归的到的模型一样,均方误差RMSE越小时越好。