论文地址
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
Abstract
- Despite great progress, existing
methods seem to have a strong bias towards
low- or high-order interactions, or require expertise
feature engineering. - The proposed model,
DeepFM, combines the power of factorization machines
for recommendation and deep learning for
feature learning in a new neural network architecture.
1 Introduction
- a linear model lacks the ability
to learn feature interactions, and a common practice is
to manually include pairwise feature interactions in its feature
vector. Such a method is hard to generalize to model
high-order feature interactions or those never or rarely appear
in the training data - While in principle FM can model
high-order feature interaction, in practice usually only order-
2 feature interactions are considered due to high complexity. - CNN-based models are biased to the interactions
between neighboring features while RNN-based
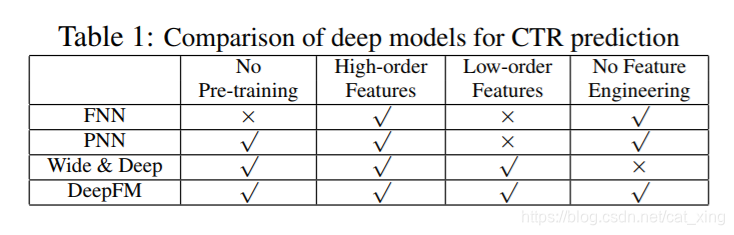
models are more suitable for click data with sequential dependency. - (FNN). This model pre-trains FM before applying
DNN, thus limited by the capability of FM. - PNN and FNN, like other deep
models, capture little low-order feature interactions, which
are also essential for CTR prediction. - In
this paper, we show it is possible to derive a learning model
that is able to learn feature interactions of all orders in an endto-end
manner, without any feature engineering besides raw
features.
We propose a new neural network model DeepFM (Figure 1) that
integrates the architectures of FM and deep neural networks (DNN)。It
models low-order feature interactions like FM and models high-order
feature interactions like DNN. Unlike the wide & deep model [Cheng et
al., 2016], DeepFM can be trained endto-end without any feature
engineering.DeepFM can be trained efficiently because its wide part and deep part, unlike [Cheng et al., 2016], share the same input and also the
embedding vector. In [Cheng et al., 2016], the input vector can be of
huge size as it includes manually designed pairwise feature
interactions in the input vector of its wide part, which also greatly
increases its complexity.We evaluate DeepFM on both benchmark data and commercial data, which shows consistent improvement over existing models for CTR prediction.
2 Our Approach
2.1 DeepFM
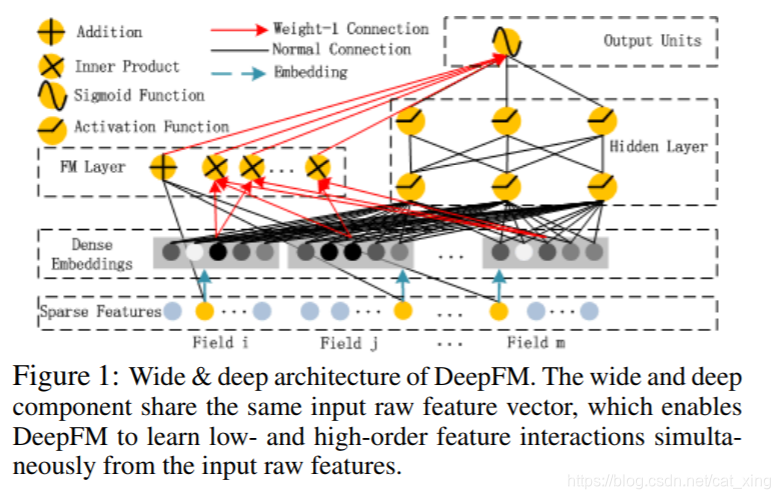
- DeepFM
consists of two components, FM component and deep component,
that share the same input.
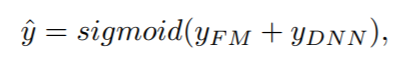
FM Component

Deep Component

- Specifically, the raw feature
input vector for CTR prediction is usually highly sparse3
,
super high-dimensional4
, categorical-continuous-mixed, and
grouped in fields (e.g., gender, location, age). - This suggests
an embedding layer to compress the input vector to a lowdimensional,
dense real-value vector before further feeding
into the first hidden layer, otherwise the network can be overwhelming
to train.

- while
the lengths of different input field vectors can be different,their embeddings are of the same size (k); - the latent feature
vectors (V ) in FM now server as network weights which
are learned and used to compress the input field vectors to the
embedding vectors. - we eliminate the need of pre-training by FM
and instead jointly train the overall network in an end-to-end
manner


- FM component and deep component
share the same feature embedding,which brings two
important benefits: 1) it learns both low- and high-order feature
interactions from raw features; 2) there is no need for expertise
feature engineering of the input, as required in Wide
& Deep [Cheng et al., 2016].
2.2 Relationship with the other Neural Networks



3 Experiments
3.1 Experiment Setup
Datasets

Evaluation Metrics
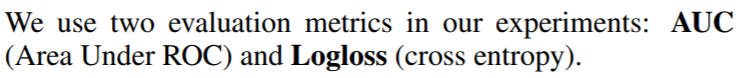
Model Comparison
We compare 9 models in our experiments: LR, FM, FNN,
PNN (three variants), Wide & Deep, and DeepFM.
Parameter Settings

3.2 Performance Evaluation
Efficiency Comparison
- We compare the efficiency of different
models on Criteo dataset by the following formula:


Effectiveness Comparison
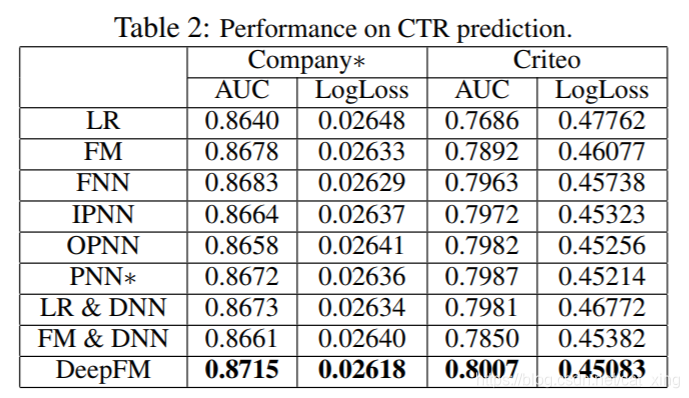
- Learning feature interactions improves the performance
of CTR prediction model. - Learning high- and low-order feature interactions simultaneously
and properly improves the performance
of CTR prediction model - Learning high- and low-order feature interactions simultaneously
while sharing the same feature embedding
for high- and low-order feature interactions learning
improves the performance of CTR prediction model.
3.3 Hyper-Parameter Study
Activation Function
relu is more appropriate than tanh for
all the deep models, except for IPNN. Possible reason is that
relu induces sparsity.
Dropout
The result shows that adding reasonable
randomness to model can strengthen model’s robustness.
Number of Neurons per Layer
an over-complicated model is easy to overfit
In our
dataset, 200 or 400 neurons per layer is a good choice.
Number of Hidden Layers
increasing number of hidden layers
improves the performance of the models at the beginning,
however, their performance is degraded if the number of hidden
layers keeps increasing. This phenomenon is also because
of overfitting.
Network Shape
- We test four different network shapes: constant, increasing,
decreasing, and diamond. - the “constant” network
shape is empirically better than the other three options, which
is consistent with previous studies
4 Related Work
5 Conclusions
- it does not need any pre-training;
- it learns both high- and low-order feature interactions;
- it introduces a sharing strategy of feature embedding to avoid
feature engineering.
There are two interesting directions for future study. One
is exploring some strategies (such as introducing pooling layers)
to strengthen the ability of learning most useful highorder
feature interactions. The other is to train DeepFM on a
GPU cluster for large-scale problems.