目录
RabbitMQ特点
RabbitMQ是部署最广泛的消息代理,也是AMQP(Advanced Message Queuing Protocol,高级消息队列协议)的标准实现;它有一下特点:
- 支持多种消息传递协议,消息队列,传递确认机制,灵活的路由消息到队列,多种交换类型
- 可在许多操作系统及云环境中运行,并为大多数流行语言提供各种开发工具
- 可插拔身份认证授权,支持TLS(Transport Layer Security, 安全传输层协议)和LDAP(Lightweight Directory Access Protocol,轻量目录访问协议)。轻量且容易部署到内部、私有云或公有云中。
- 也可以部署在分布式和联合配置中,以满足高规模、高可用性的要求
- 有专门的用于管理和监督的http-API、命令行工具和UI
RabbitMQ结构
vhost虚拟主机
一个broker里可以开设多个虚拟主机;类似于许多流行web服务器使用的“虚拟主机”,并且提供AMQP实体所在的完全隔离的环境(用户组,exchange,queue等)。AMQP客户端指定在AMQP连接协商期间要使用的虚拟主机。
channel 消息通道
在客户端的每个连接里,可以建立多个channel, 每个channel代表一个会话任务。(定义exchange, 定义queue,绑定队列和exchange,publishMessage...都是在channel中完成的)
AMQP(使用TCP进行可靠传递)Connection(连接)通常是长期存在的,AMQP连接使用身份验证,可以用TLS、SSL进行保护。当应用程序不需要连接到AMQP代理的时,应关闭AMQP连接,而不是突然关闭底层TCP连接。
如果直接在TCP基础上进行数据流动,频繁的建立关闭TCP连接会消耗很多系统资源并使配置防火墙变得更加困难,而且TCP连接数量有限额。所以AMQP在TCP连接的基础上建立了channel(通道,特定通道和另一个通道上的通信完全分开,所以每个AMQP方法还带有一个通道号,客户端通过该通道号确定该方法针对的通道)。
exchange消息交换机
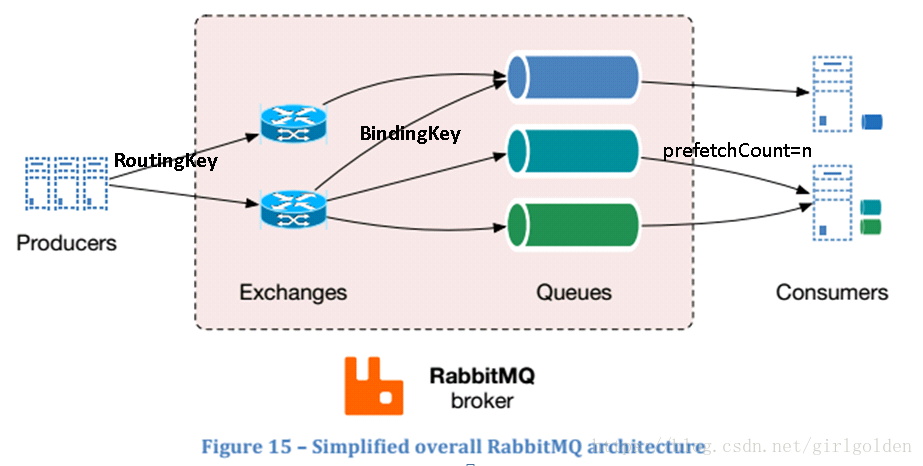
exchange是发送消息的AMQP实体。它接收消息(生产者-->交换机时产生RoutingKey)并将其按照自己的交换类型和某种规则(Binding;在绑定queue和Exchange的时候产生BindingKey;当RoutingKey与BindingKey相同时就会发送到相应队列中)路由到0个或多个队列。
交换机的类型
| Direct exchange | (Empty string) and amq.direct (RoutingKey === BindingKey) |
| Fanout exchange | amq.fanout (路由到所有绑到该exchange的queue) |
| Topic exchange | amq.topic (BindingKey与RoutingKey匹配) |
| Headers exchange | amq.match (and amq.headers in RabbitMQ) (不依赖BindingKey和RoutingKey,根据Headers属性,headers中属性的值等于绑定时指定的值,则消息匹配) |
交换机的几个重要属性
- Name
- Durability: 交换机可以是持久化的也可以是瞬时的。当broker重启时持久化的exchange仍旧存在,而瞬时的exchange则只能在broker上线后重新提交声明。
- Auto-delete: 当没有一个队列绑定到该交换机时,则删除该交换机。
- Arguments: (可选,根据插件和特定于代理的功能使用)
注: default exchange是broker 预先声明的没有名字(空string)的直接交换机。它有一个特殊的属性,这对简单的应用程序非常有用: 创建的每个队列都使用和队列名相同的BindingKey来绑定到该exchange上。(所以default exchange看起来好像能直接把消息发给队列一样,即使技术上根本不是看起来的那样)
Queue任务队列
1. 任务队列的主要思想
避免立即执行资源密集型任务并且要等待一个任务完成后才能执行下一个。RabbitMQ将任务封装成消息发送到队列中;后台运行的进程或线程取出这些任务并执行。使用任务队列能够轻松地并行工作,若任务积压过多,可以运行更多程或线程解决。如果后台运行了多个进程或线程,name这些进程或线程共享这些任务。这个概念在Web应用程序中特别有用,因为在一个短的http请求窗口中无法处理复杂的任务。例如:连续有n个get请求,而每个get请求耗时10s。。。。。。
2. 循环调度
默认情况下, RabbitMQ会按顺序将消息发给下一个消费者,这样每个消费者将获得相同数量的消息。
3. 均衡调度
不难看出循环调度性能并不太好。比如当1,3,5任务处理复杂2.4.6任务超简单,分到135的A忙的要死分到246的B闲的发毛,这明显浪费了资源,而且RabbitMQ对这种情况一无所知(它不会查看消费者未确认消息的数量,只盲目循环发消息),仍旧均匀的发送消息。
为了避免这种情况,可以设置prefetch=1来要告诉RabbitMQ: 在一个worker处理完一条消息并回ack后才向它发新的消息。如果这个worker在忙碌,就把消息发给另外一个不忙的worker。
若所有worker都在忙碌, 队列可能会被填满。此时可以添加更多worker或者采用其他策略。
4. 消息确认
为了更加可靠的传递消息,保证消息永不丢失,RabbitMQ提供了消息 确认机制。消费者发回ack(acknowledgement)告诉RabbitMQ已经收到并处理了某消息,RabbitMQ可以自由删除那个消息了。若一个消费者没有发送ack就死亡了(channel关闭、connection关闭、或者TCP connection断了),那么RabbitMQ就可以了解到那条消息没被处理妥当,然后把那条消息重新排队。如果有其他消费者在线,RabbitMQ就会立即把那条消息发给另一个消费者。这样就保证了即使process偶尔死亡,消息 不会丢失。
这里没有消息超时一说,当消费者死亡后RabbitMQ会重新发送消息,即使处理一条消息要耗费非常非常长的时间。
默认情况下,消息确认机制是打开的。ack必须在收到的消息的同一信道上发送,否则会导致通道级协议异常。
忘记发送ack,会导致严重后果。当客户端退出时,消息会被重复传递,但RabbitMQ会消耗越来越多的内存,因为它不能释放没有收到ack的消息。在linux上,可以使用rabbitmqctl 打印message_unacknowledged 信息来debug这种错误:sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
在Windows上可以用 rabbitmqctl.bat list_queues name messages_ready messages_unacknowledged
5. 消息持久化
RabbitMQ消息持久化,即数据写到磁盘上。需要exchange,queue,消息(投递时指定delivery_mode)都持久化。如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的。如果exchange和queue两者之间有一个持久化,一个非持久化,就不允许建立绑定。
注: 将消息标记为持久化并不能完全保证消息不会丢失。一、RabbitMQ接受消息但并未保存时,仍有一个短暂时间;二、RabbitMQ不会为每条消息执行fsync(2)——它可能只是保存到缓存而不是真正写入了磁盘。如果需要更高级别,需要使用发布者确认机制(publisher confirms)。
6. 任务队列的几个重要属性
- Name
- Durable: 持久化(持久化到磁盘)后,当代理重启后该队列依旧存在。队列的持久性不会使路由到该队列的消息持久。如果代理被删除然后重新启动,则在代理启动期间将重新声明持久队列,但是,只会 恢复持久性消息。
- Excusive : 仅由一个连接使用,当该连接关闭时就删除队列。
- Auto-delete : 当没有消费者订阅时,删除队列。
- Arguments : (可选,由插件和特定于代理的功能使用,例如消息TTL,队列长度限制等)