首先来看一下堆和栈的区别
栈区:
1.每个线程包含一个栈区,栈中只保存基础数据类型的值和对象以及基础数据的引用
2.每个栈中的数据(基础数据类型和对象引用)都是私有的,其他栈不能访问。
3.通过栈帧从处理器那里获取支持,堆栈指针若向下移动,则分配新的内存;若向上移动,则释放那些内存。栈中的数据必虚要有确切大小和生命周期,因为JAVA编译器必须生成相应的代码,以便上下移动堆栈指针,这一约束限制了程序的灵活性。
4、栈中的数据是共享的,没有重复的,这里这个概念不要弄错,例如int a = 6,会先去栈中看看存不存在6这个值,如果存在就将a指向这个值,如果不存在就会添加6这个值,然后将a指向6。接着int b = 6,创建完b的引用变量后,发现栈中存在6这个数据,就把b指向6,而不会新建6这个数据,这样a和b会共享6这个数据。所以栈中的值是没有重复的。
5、当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆区:
1.存储的全部是对象,每个对象都包含一个与之对应的class的信息。(class的目的是得到操作指令)
2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身 。所有new出来的东西。
3.与栈不同,编译器不需要知道要从堆里分配多少存储区域,也不必知道存储的数据在堆里存活多长时间。因此,在堆里分配存储有很大的灵活性。当你需要创建一个对象的时候,只需要new写一行简单的代码,当执行这行代码时,会自动在堆里进行存储分配。当然,为这种灵活性必须要付出相应的代码。用堆进行存储分配比用堆栈进行存储存储需要更多的时间。
4.堆中的数据都有初始值,引用类型的初始值为null。
5.当存储在堆内存的对象实例变为垃圾后,会在java垃圾回收器空闲时进行回收。
栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。
堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
这里我们就知道为什么局部变量和对象引用存储在栈中,因为局部变量和对象引用的生命周期就是它所在的大括号,脱离了他所在的大括号,就变成了垃圾,就可以被垃圾回收器回收。
而成员变量和对象本身不知道生命周期就存放在堆中。
User user = new User();
这个操作,会将user引用存储在栈中,new User()这个对象存储在堆中。
接着我们来看一下 == 与equals的区别。
最近看面试题的时候经常发现这么一道经典的题,那就是==与equals的区别,但是发现看了几遍之后老是忘,看来好几记性还是不如烂笔头,就在这里做个总结。
我们平常都说 == 比较的是地址值,而equals比较的是内容。
其实==比较的是栈中的数据是否相同,equals是用来比较堆中的数据是否相同。
接下来看一个int类型例子,我们来想一下输出结果
//这些变量都是局部变量
int a = 200;
Integer b = 200;
Integer c = 200;
Integer b2 = 100;
Integer c2 = 100;
System.out.println(a==b);
System.out.println(b==c);
System.out.println(b2==c2);
System.out.println(b.equals(c));
System.out.println(b2.equals(c2));
接下来公布结果:
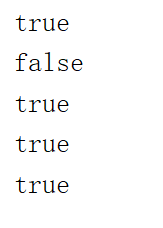
首先来看a==b,基本类型和包装类类型比较,包装类会先自动拆箱变成基本类型之后进行比较,而局部变量中的基本类型是存储在栈中的,栈中的数据不会重复,所以就为true。
接着是b == c和b2 == c2,两个包装类类型比较,那么为什么都是包装类型比较,一个为真,一个为假呢?这里其实Integer有一个常量池的概念,Integer的常量池维护了-128到127这255个数字,在这之间的数据会直接从常量池中取,超出这个范围才会新new对象。而100在这中间,所以他们取出的是同一个对象,所以是true。而200不在这个范围,他们取出的是两个对象,所以为false。
最后是equals的比较,Integer重写了equals方法,比较的是值的大小,所以值相同就为真。