UVALIVE 4875
In Olden Days, before digital typesetting (before Babbage, even), typesetting was an art, practiced
by highly skilled craftsmen. Certain character combinations, such as a-e or f-i were typeset as a single
character, called a ligature, to save space and to make the characters look better together on the printed
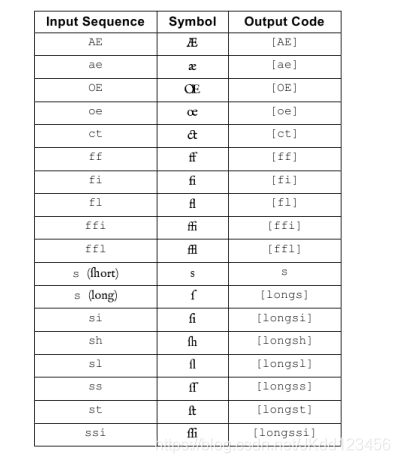
page (the ligatures for a-e and f-i were ‘ae’ and ‘fi’, respectively; the table below lists all possible ligature
combinations).
In addition, there were two different versions of the lowercase letter ‘s’: the “long s” (ß) and the
“short s”. Only the short s is used today. The rules for when to use which version are odd, but
straightforward:
-
Short s is used at the end of a word, or before punctuation within a word, such as a hyphen or
apostrophe: programs, success, hocus-pocus, revis’d. (programs, ßucceßs, hocus-pocus, revis’d) -
Short s is used before the letters ‘f’, ‘b’, or ‘k’: transfer, husband, ask, successful. (transfer,
husband, ask, ßucceßsful) -
Long s is used everywhere else, except. . .
-
It is possible that a compound word consists of a word ending in a double s followed by a word
beginning with s (this is the only situation where the sequence “sss” occurs in English text).
In this case, the middle s is set short and the other two are set long: crossstitch, crossstaff.
(croßsßtitch, croßsßaff)
Note that a “word” is not the same thing as an “identifier.” While identifiers can contain punctuation
marks such as ‘ ’ or ‘$’, words can contain only letters (at least as far as typographers are
concerned). Therefore, identifiers like “radius3” and “ adios amigo” would be typeset as “radius3”
and “adios amigo,” respectively, rather than “radiuß3” and “adioß amigo.”
Input
The first line of input contains a single integer P (1 ≤ P ≤ 1000), which is the number of data sets
that follow. Each data set consists of a single line containing the data set number, followed by a space,
followed by a string of no more than 1000 characters.
Output
For each data set, print the data set number, a space, and the input string, with the appropriate ligature
and “long s” codes substituted into the string.
The table on the above shows the code strings to use for each symbol or ligature (note that the
short s remains unchanged on output; note also that ‘AE’ and ‘OE’ are the only uppercase ligatures):
Note that the rules for the use of long and short s can combine with these ligatures in interesting
(and not always obvious) ways. For example, the input word ‘crossstitch’ becomes
‘cro[longs]s[longst]itch’, not ‘cro[longs]s[longs]titch’.

考虑的细节太多,认真才可以啊
题意:
主要有以下几种情况:
1、表格中的左边一列要按照右边一列的格式输出 [****]
其中对 Oe、oE、OE 等都输出[OE]、oe 输出 [oe]
Ae、aE、AE 等都输出[AE]、ae 输出 [ae]
2、对 s 的处理情况:
①:如果出现了 sss ,则前两个输出 [longs]s ,后一个留作与下一个字符的判断
(如果下一个可能是t,就会输出 [longst] ,而不是 [longs]t )
②:如果出现了 ssi ,则输出 [longssi]
③:位于一个单词结尾或者句子结尾的s ( 即最后一个字符为空格 或者 下标 = len - 1)
在 f、b、k 之前的s、在除字母之外的字符之前的s (包括符号和数字等)
都是 short s ,按照s输出
④:如果下一个字符为 t、h、i、l 按照 long s 输出
⑤:如果下一个(pos)字符为也s (大多数卡在了这一种情况的考虑上)
①:需要重新考虑 ③的情况
②:如果不满足③,按照 [longss] 输出
⑥:如果是这种情况 sssa 另 pos = 2
满足 s[pos] 等与 ‘s’
此时应该输出 [longs]
还需要注意:
当输入完两个字符的时候需要下标的移动
注意下标的界限
CODE:
#include <iostream>
#include <cstdio>
#include <cmath>
#include <cstring>
#include <algorithm>
#include <set>
#include <map>
#include <queue>
typedef long long LL;
using namespace std;
#define memset(a,n) memset(a,n,sizeof(a))
#define INF 0x3f3f3f3f
const LL MAX = 1e7+10;
int main()
{
char t[][5]={"AE","ae","OE","oe","ct","ff","fi","fl","ffi","ffl"};
char s[1010],c[5];
int p,k;
cin>>p;
while(p--){
cin>>k;
getchar();
gets(s);
int len=strlen(s);
int flag=0;
printf("%d ",k);
for(int i=0;i<len;i++)
{
flag=0;
memset(c,0);
if(i<len-2){
if(s[i]=='f'){
if(s[i+1]=='f'&&s[i+2]=='i'){
printf("[ffi]");
i+=2;
continue;
}
if(s[i+1]=='f'&&s[i+2]=='l'){
printf("[ffl]");
i+=2;
continue;
}
}
}
if(i<len-1){
c[0]=s[i];
c[1]=s[i+1];
// cout<<(char)c[0]<<"***"<<(char)c[1]<<endl;
for(int j=0;j<10;j++){
if(strcmp(t[j],c)==0){
printf("[%s]",c);
i++;
flag=1;
break;
}
}
if(flag)
continue;
if(strcmp(c,"aE")==0||strcmp(c,"Ae")==0){
printf("[AE]");
i+=1;
continue;
}
if(strcmp(c,"Oe")==0||strcmp(c,"oE")==0){
printf("[OE]");
i+=1;
continue;
}
}
if(s[i]=='s')
{
if(i<len-2){
if(s[i+1]=='s'&&s[i+2]=='s'){
printf("[longs]s");
i+=1;
continue;
}
if(s[i+1]=='s'&&s[i+2]=='i'){
printf("[longssi]");
i+=2;
continue;
}
}
if(i<len-1){
if(s[i+1]=='32'||i==len-1||s[i+1]<'a'||s[i+1]>'z'){
printf("s");
continue;
}
if(s[i+1]=='f'||s[i+1]=='b'||s[i+1]=='k'){
printf("s");
continue;
}
if(s[i+1]=='i'||s[i+1]=='h'||s[i+1]=='l'||s[i+1]=='t')
{
printf("[longs%c]",s[i+1]);
i++;
continue;
}
if(s[i+1]=='s')
{
if(i+1==len-1||s[i+2]==' '||s[i+2]<'a'||s[i+2]>'z'){
printf("[longs]s");
i++;
continue;
}
if(i<len-2)
{
if((s[i+2]=='f'||s[i+2]=='b'||s[i+2]=='k')){
printf("[longs]s");
i++;
continue;
}
}
printf("[longss]");
i++;
continue;
}
if(s[i-1]=='s'&&s[i-2]=='s'&&i>1){
printf("[longs]");
continue;
}
printf("[longs]");
continue;
}
}
printf("%c",s[i]);
}
printf("\n");
}
}