正则表达式***
概述

分类

基本语法
元字符
^ 匹配字符串的开头 $ 匹配字符串的末尾。 . 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 [...] 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' [^...] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 re* 匹配0个或多个的表达式。 re+ 匹配1个或多个的表达式。 re? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 re{ n} 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 re{ n,} 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 a| b 匹配a或b (re) 匹配括号内的表达式,也表示一个组
一些基本模式:
\w 匹配数字字母下划线 \W 匹配非数字字母下划线,包括中文字 \s 匹配任意空白字符,等价于 [\t\n\r\f]。 \S 匹配任意非空字符 \d 匹配任意数字,等价于 [0-9]。 \D 匹配任意非数字 \A 匹配字符串开始 \Z 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 \z 匹配字符串结束 \G 匹配最后匹配完成的位置。 \b 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 \B 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。



重复

![]()

#Python正则表达式里的单行re.S和多行re.M模式 参考:https://www.cnblogs.com/pugang/p/10123285.html #单行模式下,点号(.)匹配了包括换行符在内的所有字符。所以,更本质的说法是:单行模式re.DOTALL/re.S改变了点号(.)的匹配行为 #多行模式下,^除了匹配整个字符串的起始位置,还匹配换行符后面的位置;$除了匹配整个字符串的结束位置,还匹配换行符前面的位置.



贪婪与非贪婪*

正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志: 修饰符 描述 re.I 使匹配对大小写不敏感(IgnoreCase)(re.DOTALL) re.L 做本地化识别(locale-aware)匹配 re.M 多行匹配,影响 ^ 和 $(Multiline)(re.MULTILINE) re.S 使 . 匹配包括换行在内的所有字符(Singleline) re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. re.X 忽略表达式中的空白字符,如果要使用空白字符用转义,#可以用来做注释(re.VERBOSE)
练习1
IP地址


import socket nw = socket.inet_aton('192.168.05.001') print(nw,socket.inet_ntoa(nw))

练习2
选出含有ftp的链接,且文件类型是gz或者xz的文件名


Python的正则表达式
python使用re模块提供了正则表达式处理的能力
常量
常量 说明 re.M/re.MULTILINE 多行模式 re.S/re.DOTALL 单行模式 re.I/re.IGNORECASE 忽略大小写 re.X/re.VERBOSE 忽略表达式中的空白字符 #使用|位或运算开启多项选择,如下例: >>>import re >>> a = 'This is the first line.\nThis is the second line.\nThis is the third line.' >>> re.findall(r'^This.*?line.$', a, flags=re.DOTALL+re.MULTILINE) ['This is the first line.', 'This is the second line.', 'This is the third line.'] >>> re.findall(r'^This.*?line.$', a, flags=re.DOTALL | re.MULTILINE) ['This is the first line.', 'This is the second line.', 'This is the third line.']
方法
编译

单次匹配

import re s = '''bottle\nbag\nbig\napple''' # for x in enumerate(s): # if x[0]%8==0: # print() # print(x,end=' ') # print('\n') #match:尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none result = re.match('b',s) print(1,result) result = re.match('a',s) print(2,result) #先编译,然后使用正则表达式对象 regex = re.compile('a') result = regex.match(s)#依旧重头开始找 print(3,result) result = regex.match(s,15)#把索引15作为开始找 print(4,result) #search:扫描整个字符串并返回第一个成功的匹配 result = re.search('a',s)#search(pattern, string, flags=0): print(5,result) regex = re.compile('b') result = regex.search(s,1) print(6,result) regex = re.compile('^b',re.M)#不管是不是多行模式,找到就返回 result =regex.search(s)#search(self, string, pos=0, endpos=-1): print(7,result) #fullmatch:要完全匹配才会返回非None result = re.fullmatch('bag',s) print(8,result) regex = re.compile('bag') result = regex.fullmatch(s) print(9,result) result = regex.fullmatch(s,7,10) print(10,result)
全部匹配

import re s = '''bottle\nbag\nbig\napple''' #findall方法 result = re.findall('^b.*',s) print(1,result) regex = re.compile('^b.*',re.S)#单行模式结果:['bottle\nbag\nbig\napple'] result = regex.findall(s) print(2,result) regex = re.compile('^b.*',re.M)#多行模式结果:['bag', 'big'] result = regex.findall(s,7) print(3,result) result =re.finditer('^b.*',s) print(4,result) #finditer result = regex.finditer(s) print(type(result))
匹配替换

分割字符串

分组


练习
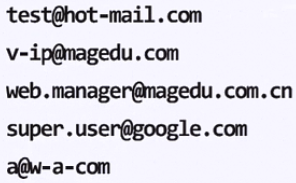
1.匹配邮箱地址
2.匹配html标记的内容

3.匹配URL