版权声明:我是南七小僧,微信: to_my_love ,2020年硕士毕业,寻找 自然语言处理,图像处理,软件开发等相关工作,欢迎交流思想碰撞。 https://blog.csdn.net/qq_25439417/article/details/87689500

# -*- coding: utf-8 -*- """ Created on Mon Feb 18 19:13:53 2019 @author: Lenovo """ import pandas as pd import numpy as np #import itertools from keras.layers import * from keras.models import * from keras.utils import plot_model NUM_SAMPLES = 1000 BATCH_SIZE = 64 EPOCH = 200 txt = pd.read_table('cmn.txt',header=None).iloc[:NUM_SAMPLES,:,] txt.columns=['inputs','targets'] txt['targets'] = txt['targets'].apply(lambda x: '\t'+x+'\n') input_texts = txt.inputs.values.tolist() target_texts = txt.targets.values.tolist() targets_characters = sorted(list(set(txt.targets.unique().sum()))) inputs_characters = sorted(list(set(txt.inputs.unique().sum()))) input_dict = {char:index for index,char in enumerate(inputs_characters)} input_dict_reverse = {index:char for index,char in enumerate(inputs_characters)} target_dict = {char:index for index,char in enumerate(targets_characters)} target_dict_reverse = {index:char for index,char in enumerate(targets_characters)} OUTPUT_FEATURE_LENGTH = len(targets_characters) INPUT_FEATURE_LENGTH = len(inputs_characters) #input_dict = zip( list(range(len(inputs_characters ))),inputs_characters ) #input_dict = {v:k for k,v in input_dict } #target_dict = zip( list(range(len(targets_characters ))),targets_characters ) #target_dict = {v:k for k,v in target_dict } #encoder输入、decoder输入输出初始化为三维向量 encoder_input = np.zeros((NUM_SAMPLES,300,INPUT_FEATURE_LENGTH)) decoder_input = np.zeros((NUM_SAMPLES,300,OUTPUT_FEATURE_LENGTH)) decoder_output = np.zeros((NUM_SAMPLES,300,OUTPUT_FEATURE_LENGTH)) #encoder的输入向量one-hot for seq_index,seq in enumerate(input_texts): for char_index, char in enumerate(seq): encoder_input[seq_index,char_index,input_dict[char]] = 1 #decoder的输入输出向量one-hot,训练模型时decoder的输入要比输出晚一个时间步,这样才能对输出监督 for seq_index,seq in enumerate(target_texts): for char_index,char in enumerate(seq): decoder_input[seq_index,char_index,target_dict[char]] = 1.0 if char_index > 0: decoder_output[seq_index,char_index-1,target_dict[char]] = 1.0 def create_model(n_input,n_output,n_units): #训练阶段 #encoder encoder_input = Input(shape = (None, n_input)) #encoder输入维度n_input为每个时间步的输入xt的维度,这里是用来one-hot的英文字符数 encoder = LSTM(n_units, return_state=True) #n_units为LSTM单元中每个门的神经元的个数,return_state设为True时才会返回最后时刻的状态h,c _,encoder_h,encoder_c = encoder(encoder_input) encoder_state = [encoder_h,encoder_c] #保留下来encoder的末状态作为decoder的初始状态 #decoder decoder_input = Input(shape = (None, n_output)) #decoder的输入维度为中文字符数 decoder = LSTM(n_units,return_sequences=True, return_state=True) #训练模型时需要decoder的输出序列来与结果对比优化,故return_sequences也要设为True decoder_output, _, _ = decoder(decoder_input,initial_state=encoder_state) #在训练阶段只需要用到decoder的输出序列,不需要用最终状态h.c decoder_dense = Dense(n_output,activation='softmax') decoder_output = decoder_dense(decoder_output) #输出序列经过全连接层得到结果 #生成的训练模型 model = Model([encoder_input,decoder_input],decoder_output) #第一个参数为训练模型的输入,包含了encoder和decoder的输入,第二个参数为模型的输出,包含了decoder的输出 #推理阶段,用于预测过程 #推断模型—encoder encoder_infer = Model(encoder_input,encoder_state) #推断模型-decoder decoder_state_input_h = Input(shape=(n_units,)) decoder_state_input_c = Input(shape=(n_units,)) decoder_state_input = [decoder_state_input_h, decoder_state_input_c]#上个时刻的状态h,c decoder_infer_output, decoder_infer_state_h, decoder_infer_state_c = decoder(decoder_input,initial_state=decoder_state_input) decoder_infer_state = [decoder_infer_state_h, decoder_infer_state_c]#当前时刻得到的状态 decoder_infer_output = decoder_dense(decoder_infer_output)#当前时刻的输出 decoder_infer = Model([decoder_input]+decoder_state_input,[decoder_infer_output]+decoder_infer_state) return model, encoder_infer, decoder_infer model_train, encoder_infer, decoder_infer = create_model(INPUT_FEATURE_LENGTH, OUTPUT_FEATURE_LENGTH, 256) plot_model(to_file='model.png',model=model_train,show_shapes=True) plot_model(to_file='encoder.png',model=encoder_infer,show_shapes=True) plot_model(to_file='decoder.png',model=decoder_infer,show_shapes=True) model_train.compile(optimizer='rmsprop', loss='categorical_crossentropy') model_train.summary() model_train.fit([encoder_input,decoder_input],decoder_output,batch_size=BATCH_SIZE,epochs=EPOCH,validation_split=0.2) model.save('eng-chinese.h5') encoder_infer.save('eng-chinese_encoder_infer.h5') decoder_infer.save('eng-chinese_decoder_infer.h5') def predict_chinese(source,encoder_inference, decoder_inference, n_steps, features): #先通过推理encoder获得预测输入序列的隐状态 state = encoder_inference.predict(source) #第一个字符'\t',为起始标志 predict_seq = np.zeros((1,1,features)) predict_seq[0,0,target_dict['\t']] = 1 # print(state) output = '' #开始对encoder获得的隐状态进行推理 #每次循环用上次预测的字符作为输入来预测下一次的字符,直到预测出了终止符 for i in range(n_steps):#n_steps为句子最大长度 #给decoder输入上一个时刻的h,c隐状态,以及上一次的预测字符predict_seq yhat,h,c = decoder_inference.predict([predict_seq]+state) #注意,这里的yhat为Dense之后输出的结果,因此与h不同 char_index = np.argmax(yhat[0,-1,:]) char = target_dict_reverse[char_index] output += char state = [h,c]#本次状态做为下一次的初始状态继续传递 predict_seq = np.zeros((1,1,features)) predict_seq[0,0,char_index] = 1 if char == '\n':#预测到了终止符则停下来 break return output for i in range(900,1000): test = encoder_input[i:i+1,:,:]#i:i+1保持数组是三维 # print(test) out = predict_chinese(test,encoder_infer,decoder_infer,300,OUTPUT_FEATURE_LENGTH) #print(input_texts[i],'\n---\n',target_texts[i],'\n---\n',out) print(input_texts[i]) print(out)参考资料:
训练时的流程:
预测时的流程: 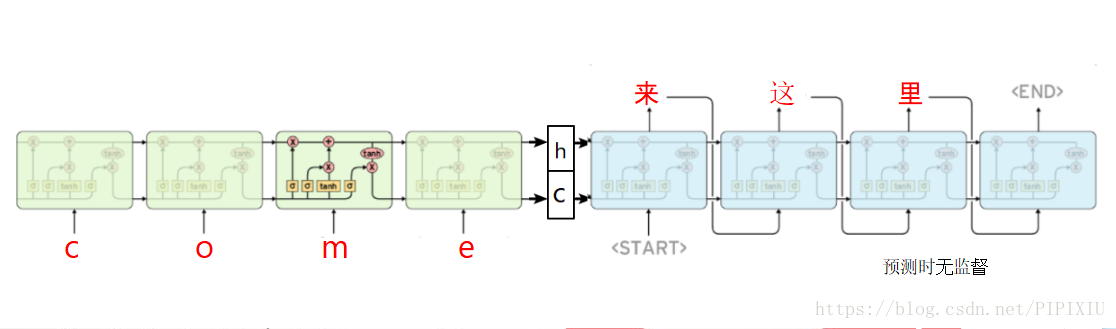

预测的时候,由于无法一次性为decoder输入全部input,因此每一次重置输入Input为上一个词【遮蔽其他位置,只有上一个词为1,其他全为0】,然后循环predict ,因此这个时候输出为【1,1,868】,868位中文tags数量,所以取argmax后,为当前时间步上 概率最大的那个tags。
而训练的时候,因为用训练集所以把decoder的input全部一次性输入完毕了,所以输出为整个句子的onehot tags,所以可以做反向传播,当做多分类。