简介:
Spark 的 调试方法 按类型可以分为三类: 调试Client 端、调试Spark Driver 和 调试 Spark Executor。画图工具(dia 0.97+git,http://live.gnome.org/Dia)
一、内容介绍
1. 调试Client如下:
./bin/spark-class 里添加命令:export JAVA_OPTS="${JAVA_OPTS} -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=28082"
修改命令:$RUNNER -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main $JAVA_OPTS "$@"
2. 调试Spark Driver 和 调试 Spark Executor 如下:
在 HiBench/conf/spark.conf 文件里添加如下配置即可(测试不能同时打开driver 和 executor,测试单独开启其中任一个成功,另外需要跑到的地方最好提前设置断点,如果跑到的地方没有设置断点,Step Over/Into/Out 会很慢。):
spark.driver.extraJavaOptions -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=28080
spark.executor.extraJavaOptions -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005
spark.shuffle.sort.bypassMergeThreshold 200
二 、Driver 断点设置
1. 设置HiBench/conf/spark.conf 文件
spark.driver.extraJavaOptions -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=28080
2. 运行 ${HIBENCH_HOME}/bin/workloads/micro/terasort/spark/run.sh,会提示
Listening for transport dt_socket at address: 28080
3. 配置 Intellij IDEA 里的 remote debug 参数:
第一次添加:(从菜单里进入Run->Debug-> + ->Remote,其中+代表Add New Configuration)

配置参数:

或者编辑:(从菜单里进入Run->Edit Configuratios)

添加driver 的 远程配置:
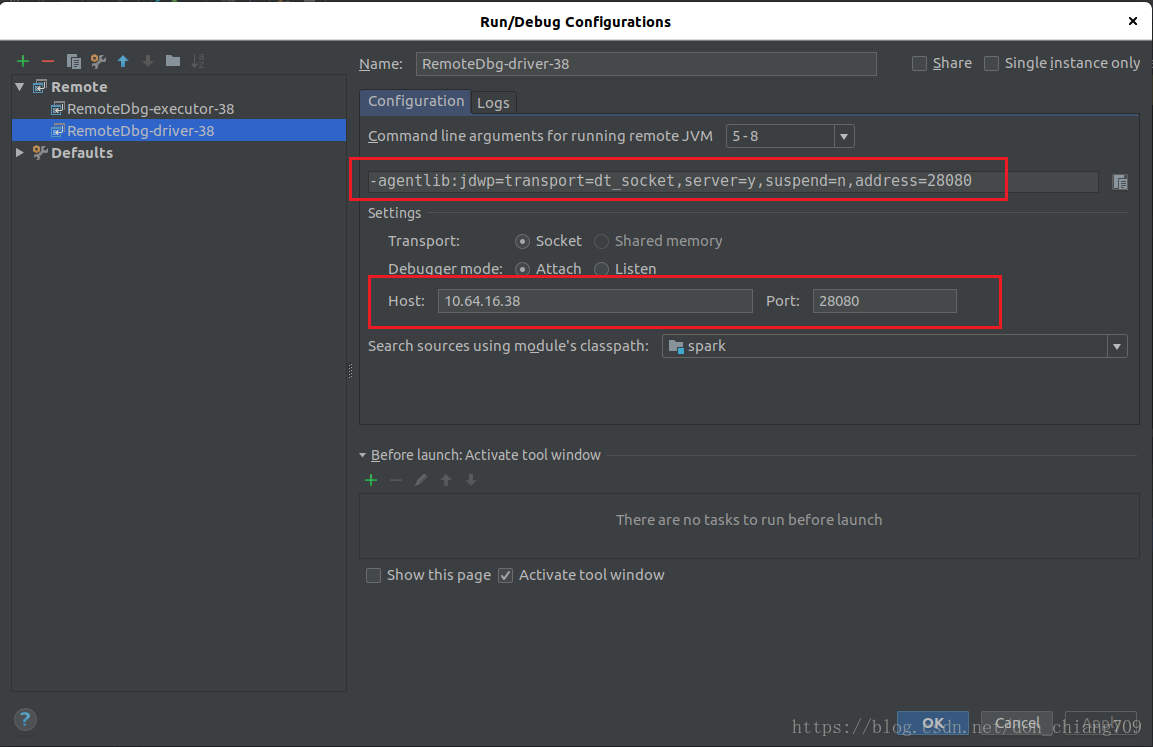
预先设置好断点(右键点击行号右边即可),如下(打勾的表示有效断点):

点击IDEA 里的 debug 按钮,IDEA会远程连接 实际运行的spark 节点:

连接后运行到你设置的断点可能需要等一会,之后Debugger窗口会显示如下:
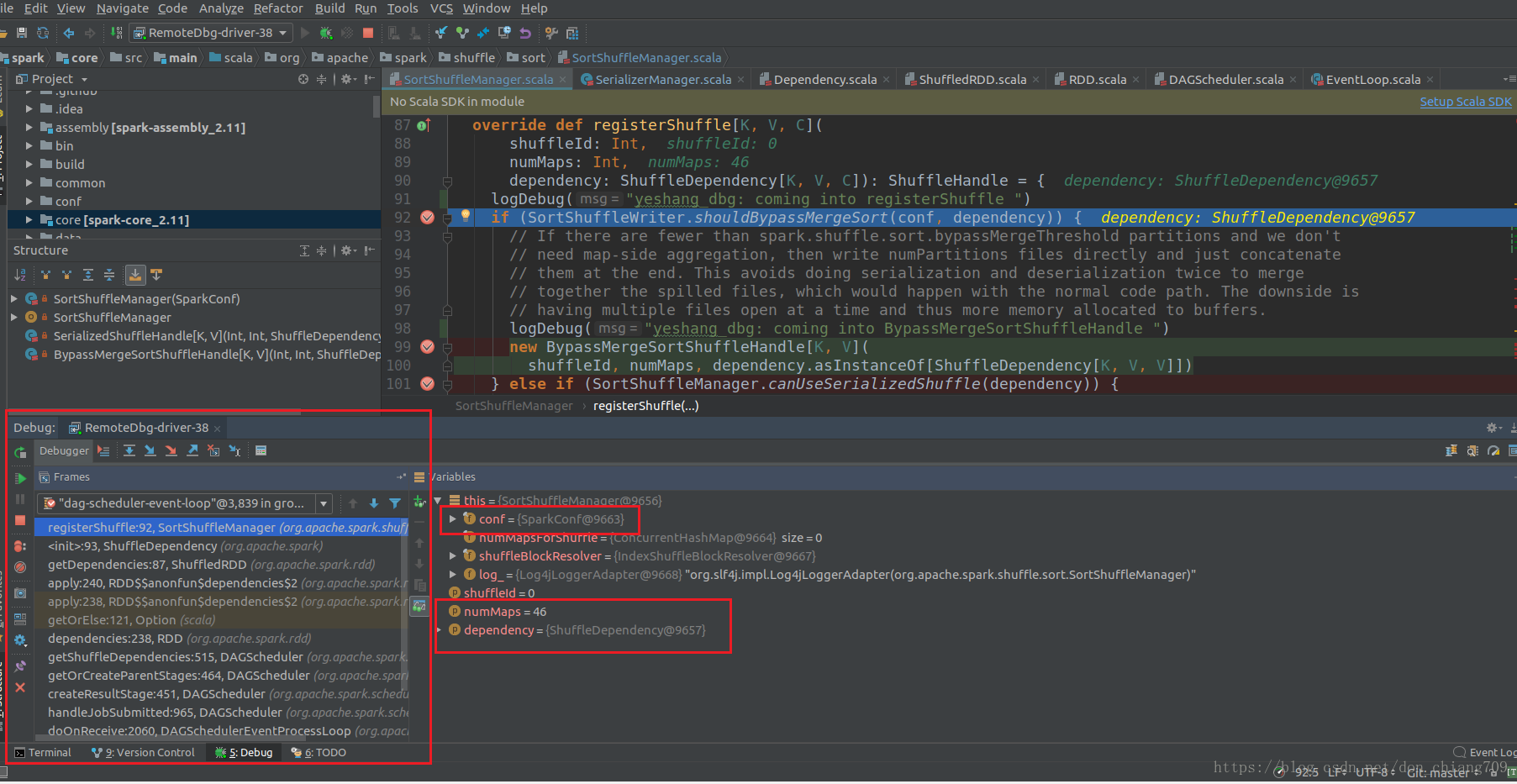
点击展开变量可以查看各种变量值:
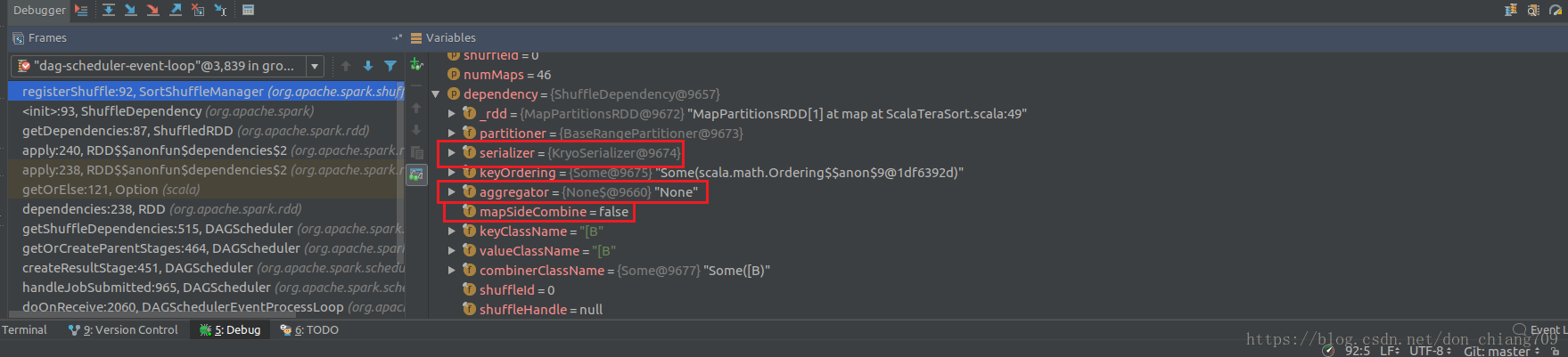
接下来可以使用 F6 单步跟踪,F7 为跳出函数,F5 为 进入函数。
4。修改IDEA里的代码,需要编译后部署到remote 节点,才能生效(不知道是否有其它好方法?)
编译:./dev/make-distribution.sh --name dbg-shuffle-hadoop2.7 --tgz -Phadoop-2.7 -Phive-thriftserver -Pyarn -Pkubernetes
部署: scp spark-2.5.0-SNAPSHOT-bin-dbg-shuffle-hadoop2.7.tgz [email protected]:~/download/Spark/
5. 查看该文件代码的历史修改,右键单击,选择Git -> Show History
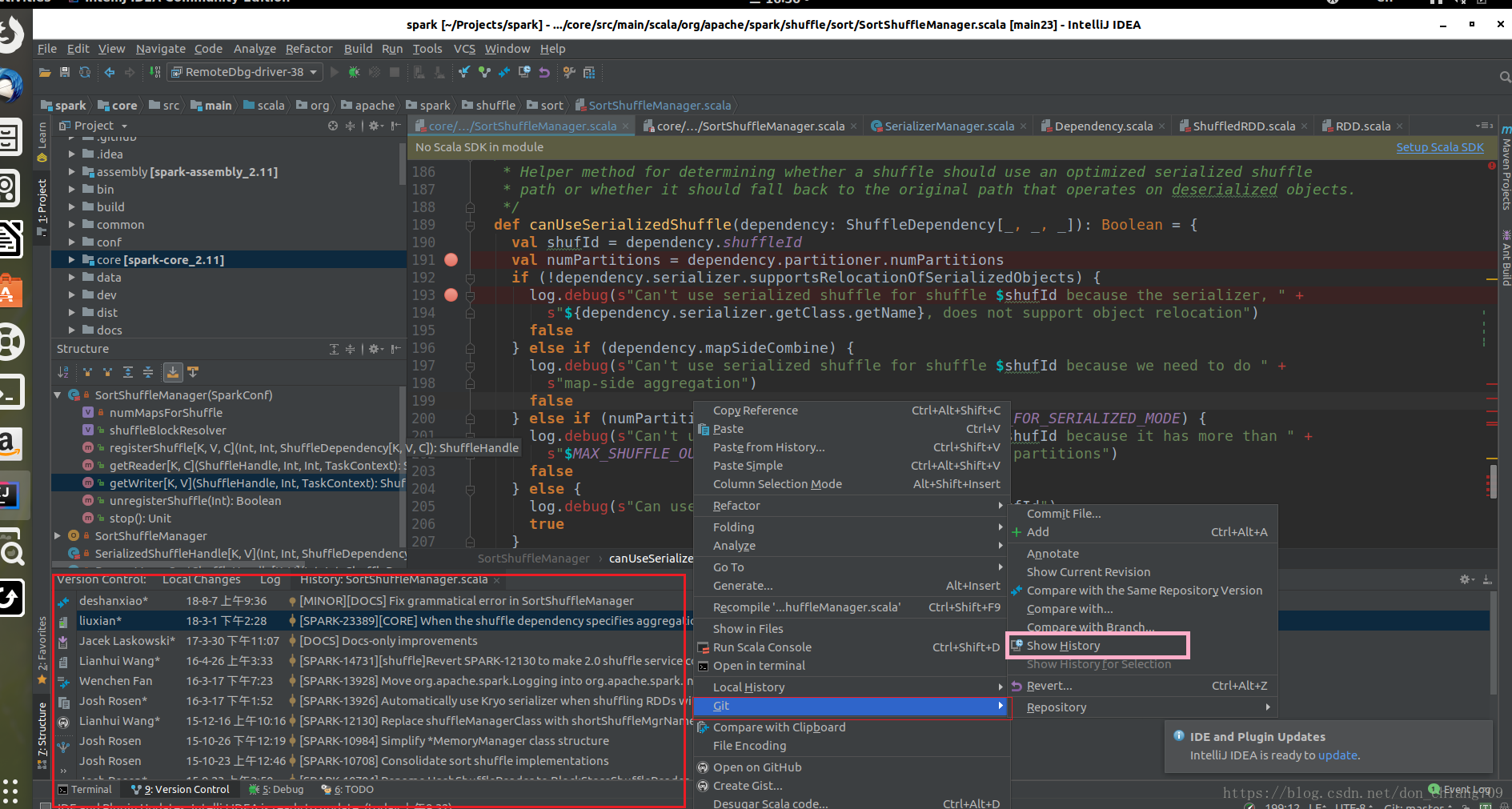
在左下角的Version Control 窗口选择一个commit版本右击,选择 Show Diff

这时会弹出这次commit 版本的diff 文件对比
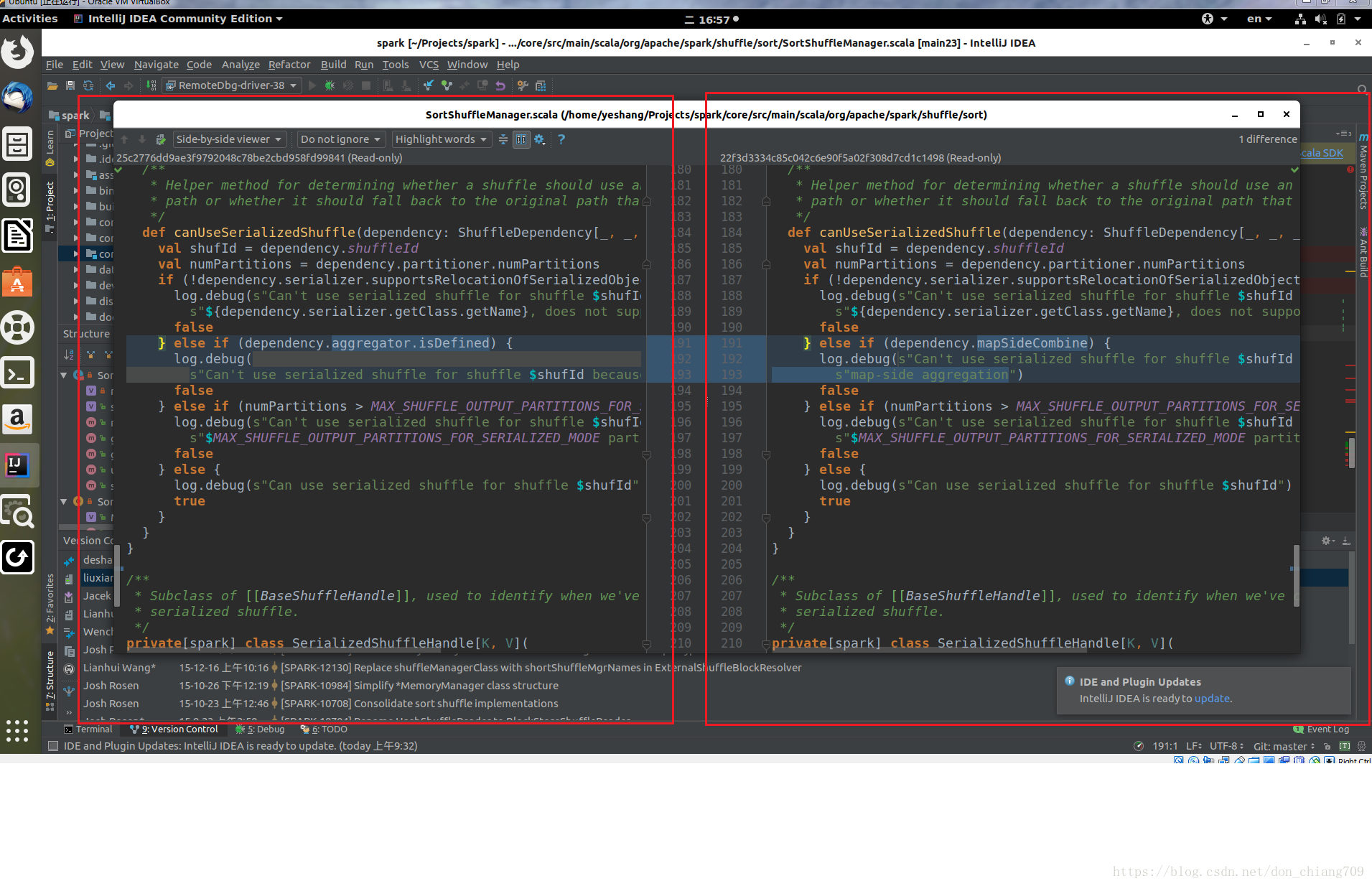
三 、Executor 断点设置
1. 设置HiBench/conf/spark.conf 文件,确保spark.executor.instances为1(多executor测试没成功)
hibench.yarn.executor.num 1
spark.executor.instances 1
spark.executor.memory 4g
spark.executor.extraJavaOptions -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005
2. 设置HiBench/conf/hibench.conf 文件,为了减少断点的循环次数
hibench.default.map.parallelism 2
hibench.default.shuffle.parallelism 1
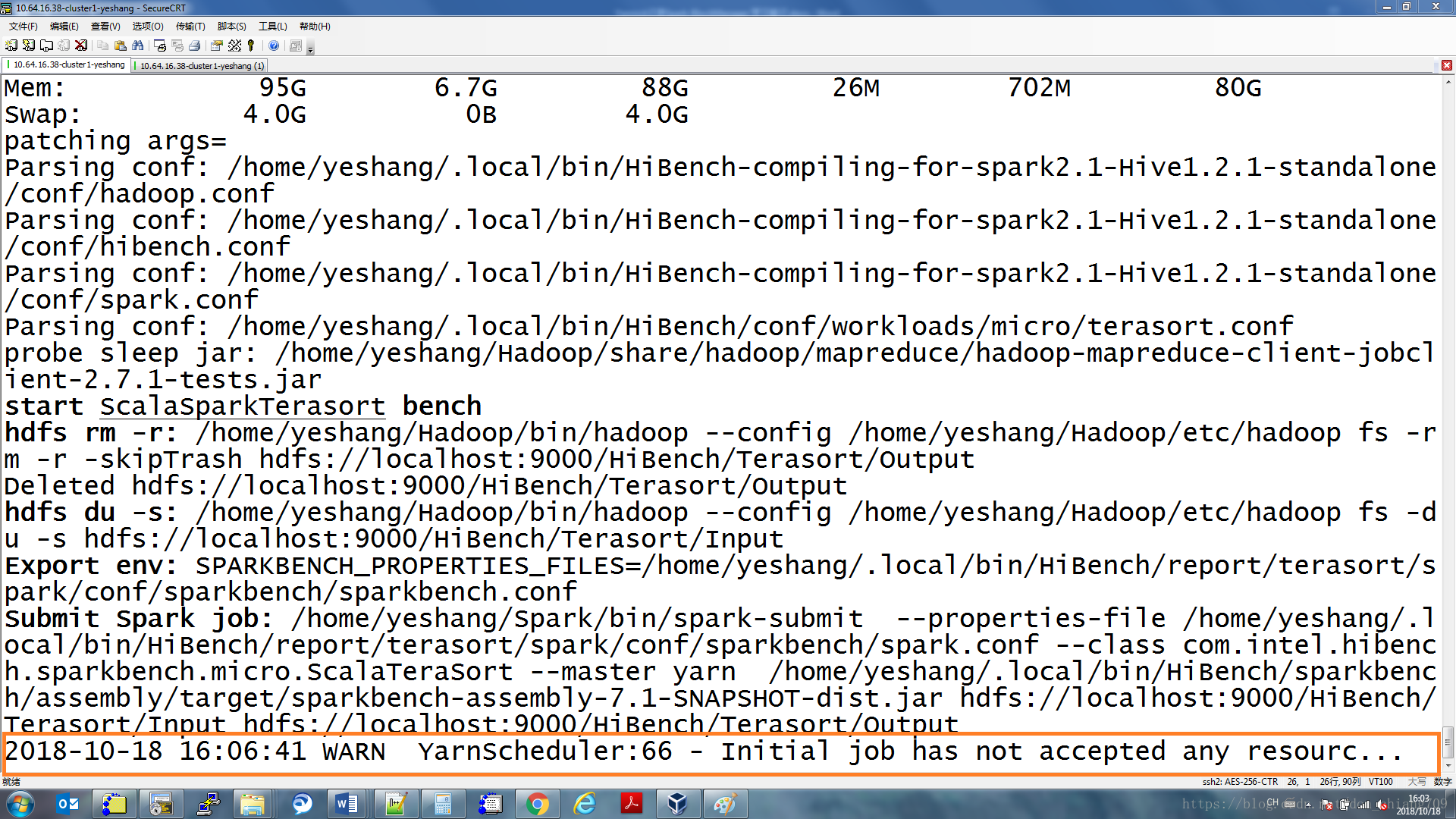
3. Remote Server(真正运行Spark的服务器)等待IDEA连接如下(并没有打印Listening for transport dt_socket at address: 5005)
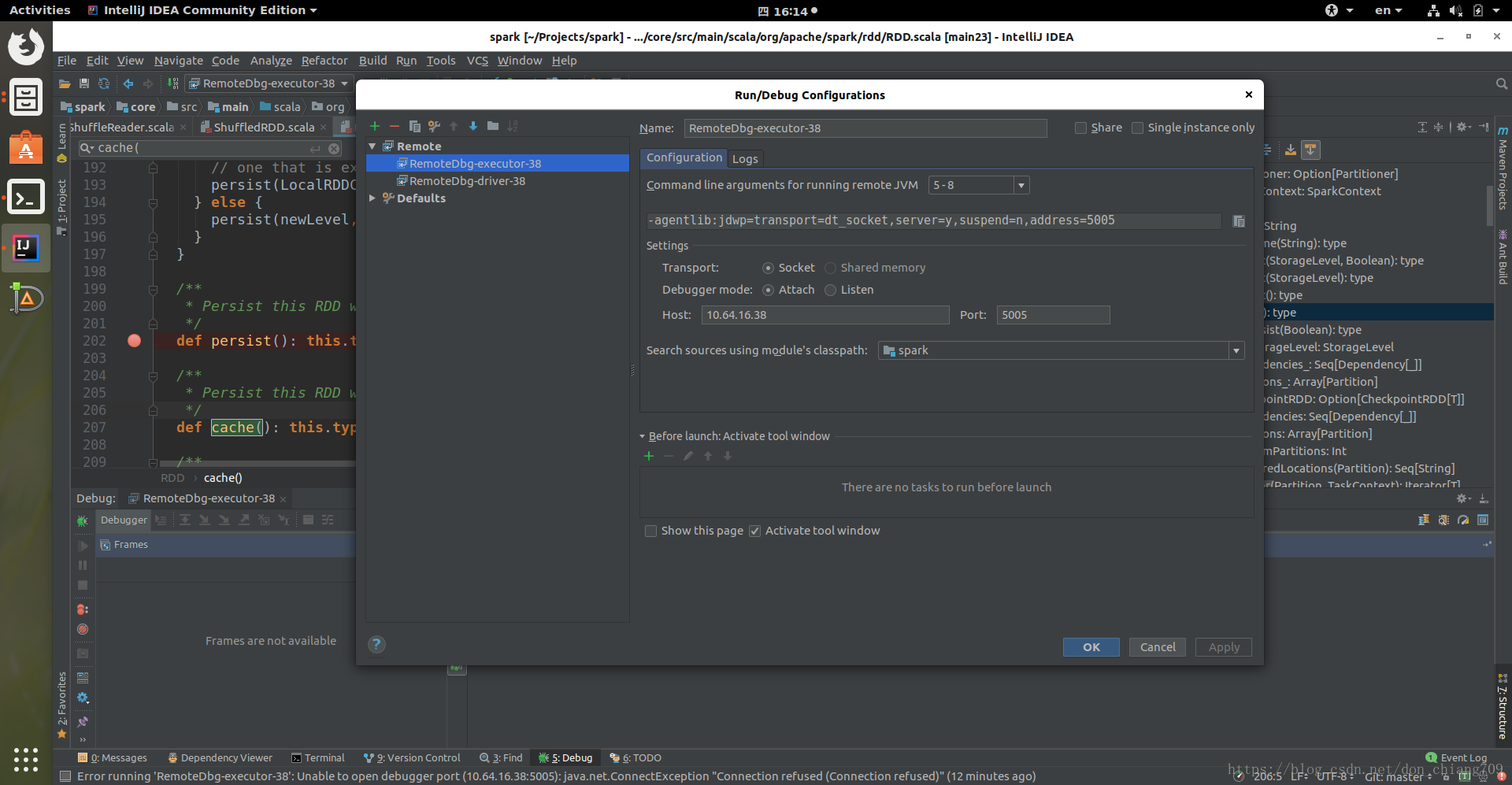
4. IDEA 的设置如下:
四、联合使用 spark-shell 与IDEA Executor 断点
1)、把 hadoop目录etc/hadoop下面的 *-sit.xml复制到${SPARK_HOME}的conf下面.
2)、在.bashrc脚本文件里 添加 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop,并运行source .bashrc
3)、在IDEA 里设置Executor debug 配置(参考三 、Executor 断点设置 ),然后用如下参数启动spark-shell:
spark-shell --properties-file /home/yeshang/.local/bin/HiBench/report/terasort/spark/conf/sparkbench/spark.conf --master yarn
4) 、在IDEA 里设置断点(例如,diskStore.put),在scala里运行如下代码
import org.apache.spark.storage.StorageLevel
sc.setLogLevel("INFO")
val textFile = spark.read.textFile("hdfs://localhost:9000/HiBench/Terasort/Input/part-m-00000")
textFile.persist(StorageLevel.MEMORY_AND_DISK)
textFile.count()
sc.getConf.get("spark.executor.memory")
textFile.unpersist()
5)显示监听的JVM断点时所有的线程及断点的Memory和Overhead

五、联合使用 JProfiler 与IDEA JProfiler 插件
1). 下载并 运行 jprofiler_linux_10_1_4.sh,到register页参考 https://www.jb51.net/softjc/608655.html
2)在IDEA里选择setting->plugins搜索并安装 jprofiler插件,设置setting->tools->jprofiler的运行程序路径

3)在IDEA里启动 JProfiler

六、Maven工程的cannnot resolve symbol 错误(包括scala基本库不能识别,Spark的LogicalPlan也不能识别)
建好工程后,源代码文件了红色代码(类或者方法) 表示cannnot resolve symbol
1. File->Settings 里,重新设置maven的安装路径和

2. File->Project Structure->Global Libraries里重新设置Scala里库路径

3. 检查JDK 是否设置

4. 删除 File->Project Structure->Libraries里的所有Maven库,点击Maven Projects里的Reimport All Maven Projects重建Index
参考: