1、分配更多的资源
分配更多资源:性能调优的王道,就是增加和分配更多的资源,性能和速度上的提升,是显而易见的;基本上,在一定范围之内,增加资源与性能的提升,是成正比的;写完了一个复杂的spark作业之后,进行性能调优的时候,首先第一步,我觉得,就是要来调节最优的资源配置;在这个基础之上,如果说你的spark作业,能够分配的资源达到了你的能力范围的顶端之后,无法再分配更多的资源了,公司资源有限;那么才是考虑去做后面的这些性能调优的点。
问题:
1、分配哪些资源?
2、在哪里分配这些资源?
3、为什么多分配了这些资源以后,性能会得到提升?
答案:
1、分配哪些资源?executor、cpu per executor、memory per executor、driver memory
2、在哪里分配这些资源?在我们在生产环境中,提交spark作业时,用的spark-submit shell脚本,里面调整对应的参数
/usr/local/spark/bin/spark-submit \
--class cn.spark.sparktest.core.WordCountCluster \
--num-executors 3 \ 配置executor的数量
--driver-memory 100m \ 配置driver的内存(影响不大)
--executor-memory 100m \ 配置每个executor的内存大小
--executor-cores 3 \ 配置每个executor的cpu core数量
/usr/local/SparkTest-0.0.1-SNAPSHOT-jar-with-dependencies.jar \3、调节到多大,算是最大呢?
第一种,Spark Standalone,公司集群上,搭建了一套Spark集群,你心里应该清楚每台机器还能够给你使用的,大概有多少内存,多少cpu core;那么,设置的时候,就根据这个实际的情况,去调节每个spark作业的资源分配。比如说你的每台机器能够给你使用4G内存,2个cpu core;20台机器;executor,20;4G内存,2个cpu core,平均每个executor。
第二种,Yarn。资源队列。资源调度。应该去查看,你的spark作业,要提交到的资源队列,大概有多少资源?500G内存,100个cpu core;executor,50;10G内存,2个cpu core,平均每个executor。
一个原则,你能使用的资源有多大,就尽量去调节到最大的大小(executor的数量,几十个到上百个不等;executor内存;executor cpu core)
4、为什么调节了资源以后,性能可以提升?

2、调节并行度
并行度:其实就是指的是,Spark作业中,各个stage的task数量,也就代表了Spark作业的在各个阶段(stage)的并行度。
如果不调节并行度,导致并行度过低,会怎么样?
假设,现在已经在spark-submit脚本里面,给我们的spark作业分配了足够多的资源,比如50个executor,每个executor有10G内存,每个executor有3个cpu core。基本已经达到了集群或者yarn队列的资源上限。
task没有设置,或者设置的很少,比如就设置了,100个task。50个executor,每个executor有3个cpu core,也就是说,你的Application任何一个stage运行的时候,都有总数在150个cpu core,可以并行运行。但是你现在,只有100个task,平均分配一下,每个executor分配到2个task,ok,那么同时在运行的task,只有100个,每个executor只会并行运行2个task。每个executor剩下的一个cpu core,就浪费掉了。
你的资源虽然分配足够了,但是问题是,并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。
合理的并行度的设置,应该是要设置的足够大,大到可以完全合理的利用你的集群资源;比如上面的例子,总共集群有150个cpu core,可以并行运行150个task。那么就应该将你的Application的并行度,至少设置成150,才能完全有效的利用你的集群资源,让150个task,并行执行;而且task增加到150个以后,即可以同时并行运行,还可以让每个task要处理的数据量变少;比如总共150G的数据要处理,如果是100个task,每个task计算1.5G的数据;现在增加到150个task,可以并行运行,而且每个task主要处理1G的数据就可以。
很简单的道理,只要合理设置并行度,就可以完全充分利用你的集群计算资源,并且减少每个task要处理的数据量,最终,就是提升你的整个Spark作业的性能和运行速度。
1、task数量,至少设置成与Spark application的总cpu core数量相同(最理想情况,比如总共150个cpu core,分配了150个task,一起运行,差不多同一时间运行完毕)
2、官方是推荐,task数量,设置成spark application总cpu core数量的2~3倍,比如150个cpu core,基本要设置task数量为300~500;
实际情况,与理想情况不同的,有些task会运行的快一点,比如50s就完了,有些task,可能会慢一点,要1分半才运行完,所以如果你的task数量,刚好设置的跟cpu core数量相同,可能还是会导致资源的浪费,因为,比如150个task,10个先运行完了,剩余140个还在运行,但是这个时候,有10个cpu core就空闲出来了,就导致了浪费。那如果task数量设置成cpu core总数的2~3倍,那么一个task运行完了以后,另一个task马上可以补上来,就尽量让cpu core不要空闲,同时也是尽量提升spark作业运行的效率和速度,提升性能。
3、如何设置一个Spark Application的并行度?
spark.default.parallelism
SparkConf conf = new SparkConf()
.set("spark.default.parallelism", "500")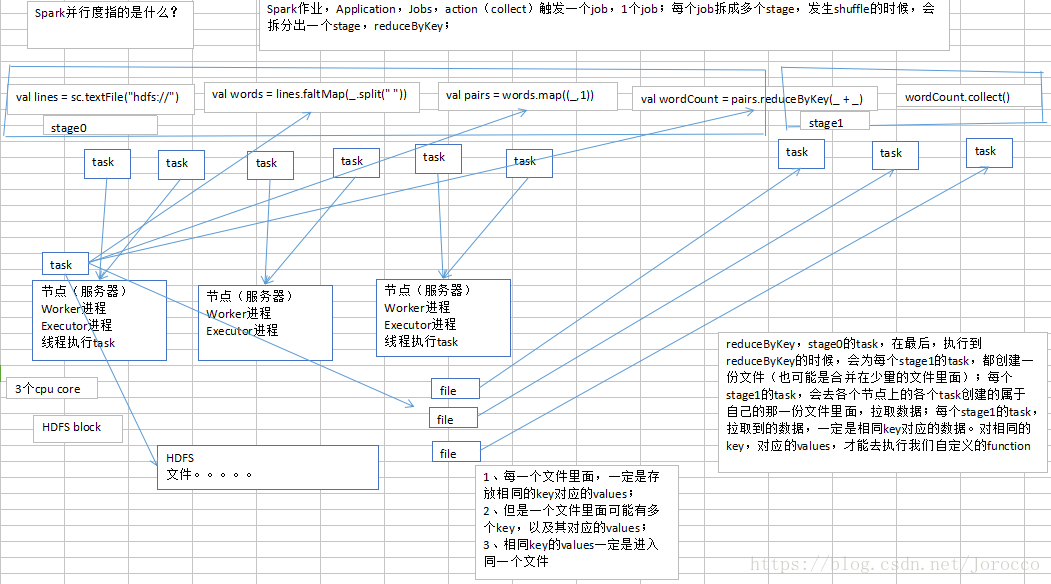
3、重构RDD和RDD持久化
第一,RDD架构重构与优化
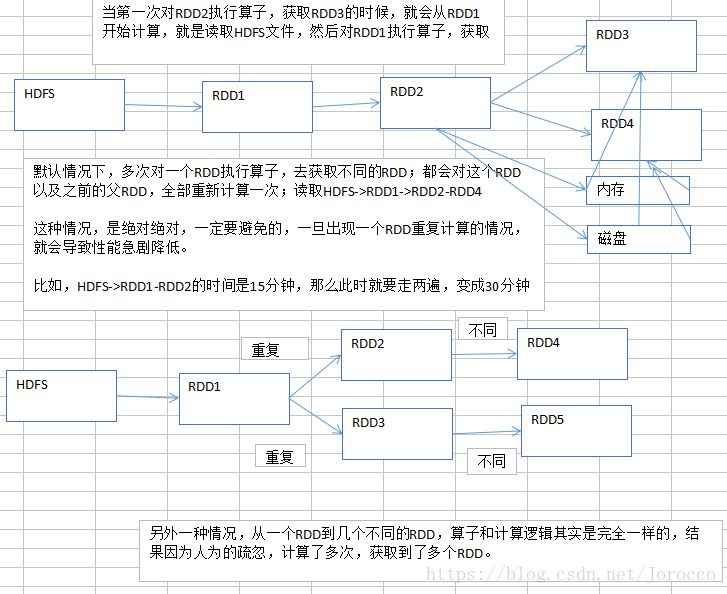
尽量去复用RDD,差不多的RDD,可以抽取称为一个共同的RDD,供后面的RDD计算时,反复使用。
第二,公共RDD一定要实现持久化
北方吃饺子,现包现煮。你人来了,要点一盘饺子。馅料+饺子皮+水->包好的饺子,对包好的饺子去煮,煮开了以后,才有你需要的熟的,热腾腾的饺子。
现实生活中,饺子现包现煮,当然是最好的了;但是Spark中,RDD要去“现包现煮”,那就是一场致命的灾难。
对于要多次计算和使用的公共RDD,一定要进行持久化。
持久化,也就是说,将RDD的数据缓存到内存中/磁盘中,(BlockManager),以后无论对这个RDD做多少次计算,那么都是直接取这个RDD的持久化的数据,比如从内存中或者磁盘中,直接提取一份数据。
第三,持久化,是可以进行序列化的
如果正常将数据持久化在内存中,那么可能会导致内存的占用过大,这样的话,也许,会导致OOM内存溢出。
当纯内存无法支撑公共RDD数据完全存放的时候,就优先考虑,使用序列化的方式在纯内存中存储。将RDD的每个partition的数据,序列化成一个大的字节数组,就一个对象;序列化后,大大减少内存的空间占用。
序列化的方式,唯一的缺点就是,在获取数据的时候,需要反序列化。
如果序列化纯内存方式,还是导致OOM,内存溢出;就只能考虑磁盘的方式,内存+磁盘的普通方式(无序列化)。
内存+磁盘,序列化
第四,为了数据的高可靠性,而且内存充足,可以使用双副本机制,进行持久化
持久化的双副本机制,持久化后的一个副本,因为机器宕机了,副本丢了,就还是得重新计算一次;持久化的每个数据单元,存储一份副本,放在其他节点上面;从而进行容错;一个副本丢了,不用重新计算,还可以使用另外一份副本。
这种方式,仅仅针对你的内存资源极度充足
/*
* 持久化,就是对RDD调用persist()方法,并传入一个持久化级别
*
* 如果是persist(StorageLevel.MEMORY_ONLY())级别就是纯内存,无序列化,那么就可以用cache()方法来替代
*
* StorageLevel.MEMORY_ONLY_SER() 第二选择
* StorageLevel.MEMORY_AND_DISK() 第三选择
* StorageLevel.MEMORY_AND_DISK_SER() 第四选择
* StorageLevel.DISK_ONLY() 第五选择
*
* 如果内存充足,需要使用双副本高可靠机制
* 选择后缀带_2的策略,如:StorageLevel.MEMORY_ONLY_2()
*
*
* */
//持久化,sessionid2actionRDD数据仅存内存,后面要用到sessionid2actionRDD就只会从内存中获取,而不会从头到尾去执行以便
//以便生成sessionid2actionRDD的过程
sessionid2actionRDD=sessionid2actionRDD.persist(StorageLevel.MEMORY_ONLY());4、广播大变量
大变量的瓶颈分析
如果你是从哪个表里面读取了一些维度数据,比方说,所有商品品类的信息,在某个算子函数中要使用到。100M。
1000个task就是100G(1000*100M)的数据,网络传输。集群瞬间因为这个原因消耗掉100G的内存。
还算小的。如果你是从哪个表里面读取了一些维度数据,比方说,所有商品品类的信息,在某个算子函数中要使用到。100M。
1000个task。100G的数据,网络传输。集群瞬间因为这个原因消耗掉100G的内存。
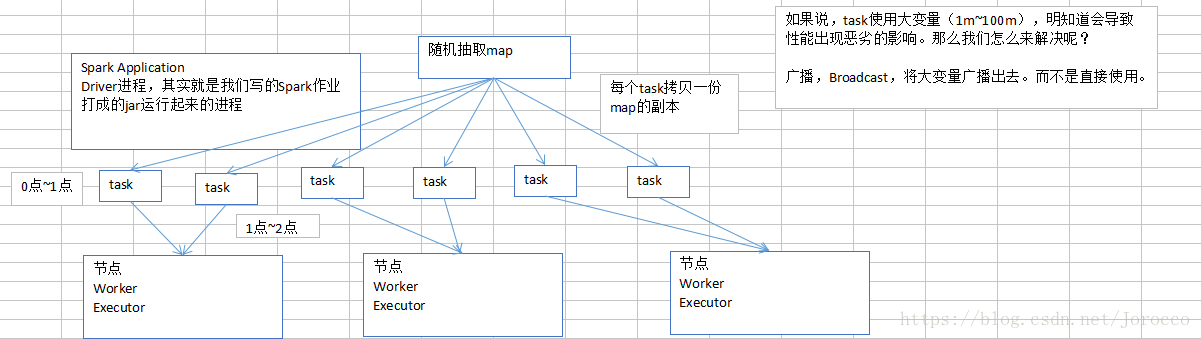
这种默认的,task执行的算子中,使用了外部的变量,每个task都会获取一份变量的副本,有什么缺点呢?在什么情况下,会出现性能上的恶劣的影响呢?
map,本身是不小,存放数据的一个单位是Entry,还有可能会用链表的格式的来存放Entry链条。所以map是比较消耗内存的数据格式。
比如,map是1M。总共,你前面调优都调的特好,资源给的到位,配合着资源,并行度调节的绝对到位,1000个task。大量task的确都在并行运行。
这些task里面都用到了占用1M内存的map,那么首先,map会拷贝1000份副本,通过网络传输到各个task中去,给task使用。总计有1G的数据,会通过网络传输。网络传输的开销,不容乐观啊!!!网络传输,也许就会消耗掉你的spark作业运行的总时间的一小部分。
map副本,传输到了各个task上之后,是要占用内存的。1个map的确不大,1M;1000个map分布在你的集群中,一下子就耗费掉1G的内存。对性能会有什么影响呢?
不必要的内存的消耗和占用,就导致了,你在进行RDD持久化到内存,也许就没法完全在内存中放下;就只能写入磁盘,最后导致后续的操作在磁盘IO上消耗性能;
你的task在创建对象的时候,也许会发现堆内存放不下所有对象,也许就会导致频繁的垃圾回收器的回收,GC。GC的时候,一定是会导致工作线程停止,也就是导致Spark暂停工作那么一点时间。频繁GC的话,对Spark作业的运行的速度会有相当可观的影响。
广播变量原理
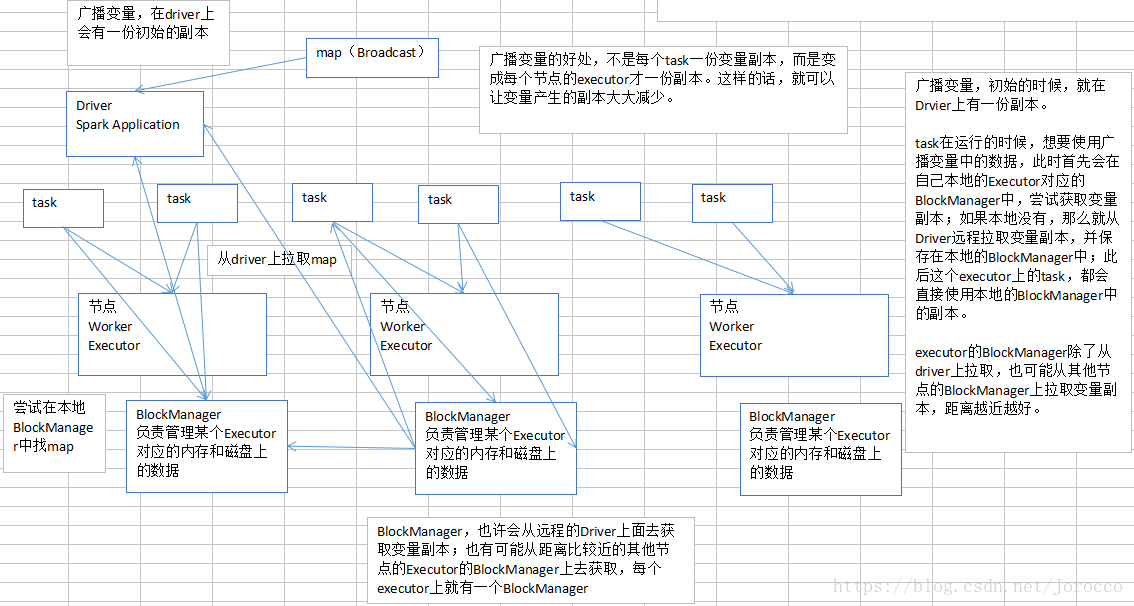
举例来说,(虽然是举例,但是基本都是用我们实际在企业中用的生产环境中的配置和经验来说明的)。50个executor,1000个task。一个map,10M。
默认情况下,1000个task,1000份副本。10G的数据,网络传输,在集群中,耗费10G的内存资源。
如果使用了广播变量。50个execurtor,50个副本。500M的数据,网络传输,而且不一定都是从Driver传输到每个节点,还可能是就近从最近的节点的executor的bockmanager上拉取变量副本,网络传输速度大大增加;500M的内存消耗。
10000M,500M,20倍。20倍~以上的网络传输性能消耗的降低;20倍的内存消耗的减少。
对性能的提升和影响,还是很客观的。
虽然说,不一定会对性能产生决定性的作用。比如运行30分钟的spark作业,可能做了广播变量以后,速度快了2分钟,或者5分钟。但是一点一滴的调优,积少成多。最后还是会有效果的。
没有经过任何调优手段的spark作业,16个小时;三板斧下来,就可以到5个小时;然后非常重要的一个调优,影响特别大,shuffle调优,2~3个小时;应用了10个以上的性能调优的技术点,JVM+广播,30分钟。16小时~30分钟。
广播变量的使用
//广播变量,就是用SparkContext的broadcast()方法传入要广播的变量即可
final Broadcast<Map<String, Map<String, List<Integer>>>>dateHourExtractMapBroadcast=
sc.broadcast(dateHourExtractMap);5、Kyro序列化
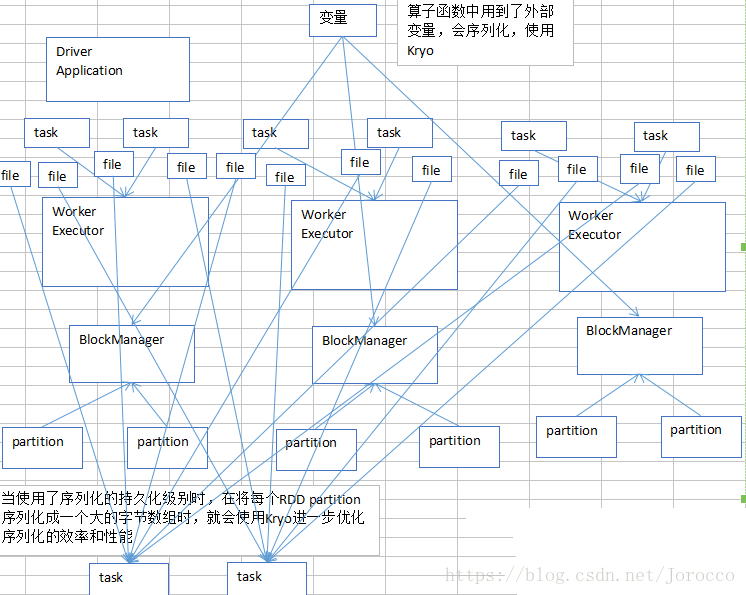
在进行stage间的task的shuffle操作时,节点与节点之间的task会互相大量通过网络拉取和传输文件,此时,这些数据既然通过网络传输,也是可能要序列化的,就会使用Kryo。
还可以进一步优化,优化这个序列化格式
默认情况下,Spark内部是使用Java的序列化机制,ObjectOutputStream / ObjectInputStream,对象输入输出流机制,来进行序列化
这种默认序列化机制的好处在于,处理起来比较方便;也不需要我们手动去做什么事情,只是,你在算子里面使用的变量,必须是实现Serializable接口的,可序列化即可。
但是缺点在于,默认的序列化机制的效率不高,序列化的速度比较慢;序列化以后的数据,占用的内存空间相对还是比较大。
可以手动进行序列化格式的优化
Spark支持使用Kryo序列化机制。Kryo序列化机制,比默认的Java序列化机制,速度要快,序列化后的数据要更小,大概是Java序列化机制的1/10。
所以Kryo序列化优化以后,可以让网络传输的数据变少;在集群中耗费的内存资源大大减少。
Kryo序列化机制,一旦启用以后,会生效的几个地方:
1、算子函数中使用到的外部变量
2、持久化RDD时进行序列化,StorageLevel.MEMORY_ONLY_SER
3、shuffle
1、算子函数中使用到的外部变量,使用Kryo以后:优化网络传输的性能,可以优化集群中内存的占用和消耗
2、持久化RDD,优化内存的占用和消耗;持久化RDD占用的内存越少,task执行的时候,创建的对象,就不至于频繁的占满内存,频繁发生GC。
3、shuffle:可以优化网络传输的性能
Kryo使用步骤
SparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
首先第一步,在SparkConf中设置一个属性,spark.serializer,org.apache.spark.serializer.KryoSerializer类;
Kryo之所以没有被作为默认的序列化类库的原因,就要出现了:主要是因为Kryo要求,如果要达到它的最佳性能的话,那么就一定要注册你自定义的类(比如,你的算子函数中使用到了外部自定义类型的对象变量,这时,就要求必须注册你的类,否则Kryo达不到最佳性能)。
第二步,注册你使用到的,需要通过Kryo序列化的,一些自定义类,SparkConf.registerKryoClasses()
项目中的使用:
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(new Class[]{CategorySortKey.class})6、fastutil的使用
fastutil的介绍
fastutil介绍:
fastutil是扩展了Java标准集合框架(Map、List、Set;HashMap、ArrayList、HashSet)的类库,提供了特殊类型的map、set、list和queue;
fastutil能够提供更小的内存占用,更快的存取速度;我们使用fastutil提供的集合类,来替代自己平时使用的JDK的原生的Map、List、Set,好处在于,fastutil集合类,可以减小内存的占用,并且在进行集合的遍历、根据索引(或者key)获取元素的值和设置元素的值的时候,提供更快的存取速度;
fastutil也提供了64位的array、set和list,以及高性能快速的,以及实用的IO类,来处理二进制和文本类型的文件;
fastutil最新版本要求Java 7以及以上版本;
fastutil的每一种集合类型,都实现了对应的Java中的标准接口(比如fastutil的map,实现了Java的Map接口),因此可以直接放入已有系统的任何代码中。
fastutil还提供了一些JDK标准类库中没有的额外功能(比如双向迭代器)。
fastutil除了对象和原始类型为元素的集合,fastutil也提供引用类型的支持,但是对引用类型是使用等于号(=)进行比较的,而不是equals()方法。
fastutil尽量提供了在任何场景下都是速度最快的集合类库。
Spark中应用fastutil的场景:
1、如果算子函数使用了外部变量;那么第一,你可以使用Broadcast广播变量优化;第二,可以使用Kryo序列化类库,提升序列化性能和效率;第三,如果外部变量是某种比较大的集合,那么可以考虑使用fastutil改写外部变量,首先从源头上就减少内存的占用,通过广播变量进一步减少内存占用,再通过Kryo序列化类库进一步减少内存占用。
2、在你的算子函数里,也就是task要执行的计算逻辑里面,如果有逻辑中,出现,要创建比较大的Map、List等集合,可能会占用较大的内存空间,而且可能涉及到消耗性能的遍历、存取等集合操作;那么此时,可以考虑将这些集合类型使用fastutil类库重写,使用了fastutil集合类以后,就可以在一定程度上,减少task创建出来的集合类型的内存占用。避免executor内存频繁占满,频繁唤起GC,导致性能下降。
关于fastutil调优的说明:
fastutil其实没有你想象中的那么强大,也不会跟官网上说的效果那么一鸣惊人。广播变量、Kryo序列化类库、fastutil,都是之前所说的,对于性能来说,类似于一种调味品,烤鸡,本来就很好吃了,然后加了一点特质的孜然麻辣粉调料,就更加好吃了一点。分配资源、并行度、RDD架构与持久化,这三个就是烤鸡;broadcast、kryo、fastutil,类似于调料。
比如说,你的spark作业,经过之前一些调优以后,大概30分钟运行完,现在加上broadcast、kryo、fastutil,也许就是优化到29分钟运行完、或者更好一点,也许就是28分钟、25分钟。
shuffle调优,15分钟;groupByKey用reduceByKey改写,执行本地聚合,也许10分钟;跟公司申请更多的资源,比如资源更大的YARN队列,1分钟。
fastutil的使用
第一步:在pom.xml中引用fastutil的包
<dependency>
<groupId>fastutil</groupId>
<artifactId>fastutil</artifactId>
<version>5.0.9</version>
</dependency>
速度比较慢,可能是从国外的网去拉取jar包,可能要等待5分钟,甚至几十分钟,不等
List<Integer> => IntList
基本都是类似于IntList的格式,前缀就是集合的元素类型;特殊的就是Map,Int2IntMap,代表了key-value映射的元素类型。除此之外,刚才也看到了,还支持object、reference。/*
* fastutil的使用很简单,比如List<Integer>的list,对应到fastutil,就是IntList
* */
Map<String,Map<String,IntList>>fastutilDateHourExtractMap=
new HashMap<String,Map<String,IntList>>();
for(Map.Entry<String, Map<String,List<Integer>>>dateHourExtractEntry:
dateHourExtractMap.entrySet()) {
String date=dateHourExtractEntry.getKey();
Map<String,List<Integer>>hourExtractMap=dateHourExtractEntry.getValue();
Map<String,IntList>fastutilHourExtractMap=new HashMap<String,IntList>();
for(Map.Entry<String, List<Integer>>hourExtractEntry:hourExtractMap.entrySet()) {
String hour=hourExtractEntry.getKey();
List<Integer>extractList=hourExtractEntry.getValue();
IntList fastutilExtractList=new IntArrayList();
for(int i=0;i<extractList.size();i++) {
fastutilExtractList.add(extractList.get(i));
}
fastutilHourExtractMap.put(hour, fastutilExtractList);
}
fastutilDateHourExtractMap.put(date, fastutilHourExtractMap);
}7、数据本地化等待时长调节
PROCESS_LOCAL:进程本地化,代码和数据在同一个进程中,也就是在同一个executor中;计算数据的task由executor执行,数据在executor的BlockManager中;性能最好
NODE_LOCAL:节点本地化,代码和数据在同一个节点中;比如说,数据作为一个HDFS block块,就在节点上,而task在节点上某个executor中运行;或者是,数据和task在一个节点上的不同executor中;数据需要在进程间进行传输
NO_PREF:对于task来说,数据从哪里获取都一样,没有好坏之分
RACK_LOCAL:机架本地化,数据和task在一个机架的两个节点上;数据需要通过网络在节点之间进行传输
ANY:数据和task可能在集群中的任何地方,而且不在一个机架中,性能最差
spark.locality.wait,默认是3s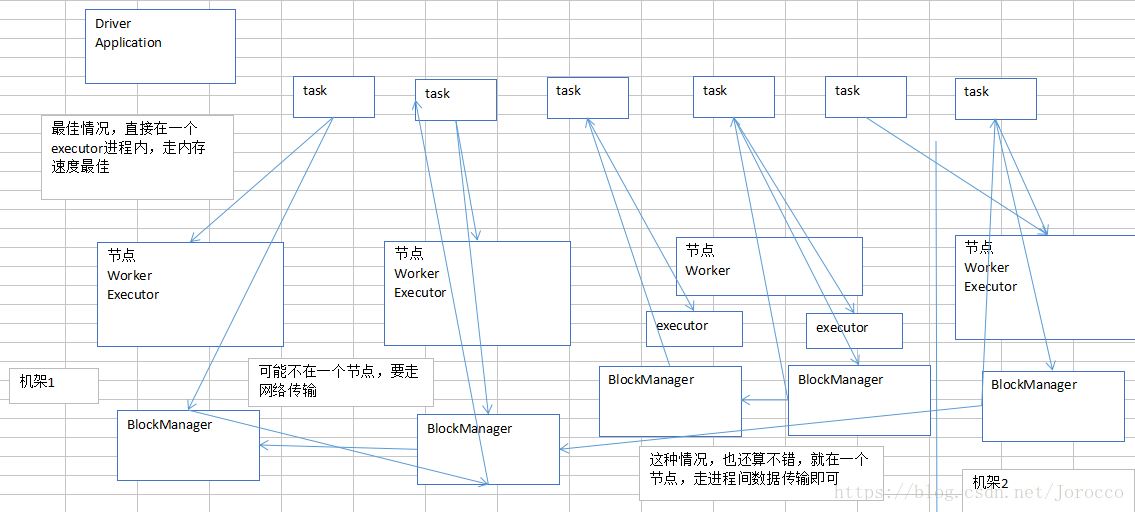
最差的就是这种跨机架拉取数据的方式了。速度非常慢,对性能的影响,相当大
Spark在Driver上,对Application的每一个stage的task,进行分配之前,都会计算出每个task要计算的是哪个分片数据,RDD的某个partition;Spark的task分配算法,优先,会希望每个task正好分配到它要计算的数据所在的节点,这样的话,就不用在网络间传输数据;
但是呢,通常来说,有时,事与愿违,可能task没有机会分配到它的数据所在的节点,为什么呢,可能那个节点的计算资源和计算能力都满了;所以呢,这种时候,通常来说,Spark会等待一段时间,默认情况下是3s钟(不是绝对的,还有很多种情况,对不同的本地化级别,都会去等待),到最后,实在是等待不了了,就会选择一个比较差的本地化级别,比如说,将task分配到靠它要计算的数据所在节点,比较近的一个节点,然后进行计算。
但是对于第二种情况,通常来说,肯定是要发生数据传输,task会通过其所在节点的BlockManager来获取数据,BlockManager发现自己本地没有数据,会通过一个getRemote()方法,通过TransferService(网络数据传输组件)从数据所在节点的BlockManager中,获取数据,通过网络传输回task所在节点。
对于我们来说,当然不希望是类似于第二种情况的了。最好的,当然是task和数据在一个节点上,直接从本地executor的BlockManager中获取数据,纯内存,或者带一点磁盘IO;如果要通过网络传输数据的话,那么实在是,性能肯定会下降的,大量网络传输,以及磁盘IO,都是性能的杀手。
我们什么时候要调节这个参数?
观察日志,spark作业的运行日志,推荐大家在测试的时候,先用client模式,在本地就直接可以看到比较全的日志。
日志里面会显示,starting task。。。,PROCESS LOCAL、NODE LOCAL
观察大部分task的数据本地化级别
如果大多都是PROCESS_LOCAL,那就不用调节了
如果是发现,好多的级别都是NODE_LOCAL、ANY,那么最好就去调节一下数据本地化的等待时长
调节完,应该是要反复调节,每次调节完以后,再来运行,观察日志
看看大部分的task的本地化级别有没有提升;看看,整个spark作业的运行时间有没有缩短
你别本末倒置,本地化级别倒是提升了,但是因为大量的等待时长,spark作业的运行时间反而增加了,那就还是不要调节了
怎么调节?
spark.locality.wait,默认是3s;6s,10s
默认情况下,下面3个的等待时长,都是跟上面那个是一样的,都是3s
spark.locality.wait.process
spark.locality.wait.node
spark.locality.wait.rack
new SparkConf()
.set("spark.locality.wait", "10")8、JVM调优
spark是用scala开发的。大家不要以为scala就跟java一点关系都没有了,这是一个很常见的错误。
spark的scala代码调用了很多java api。scala也是运行在java虚拟机中的。spark是运行在java虚拟机中的。
java虚拟机可能会产生什么样的问题:内存不足??!!
我们的RDD的缓存、task运行定义的算子函数,可能会创建很多对象。都可能会占用大量内存,没搞好的话,可能导致JVM出问题。
JVM调优(Java虚拟机):JVM相关的参数,通常情况下,如果你的硬件配置、基础的JVM的配置,都ok的话,JVM通常不会造成太严重的性能问题;反而更多的是,在troubleshooting中,JVM占了很重要的地位;JVM造成线上的spark作业的运行报错,甚至失败(比如OOM)。
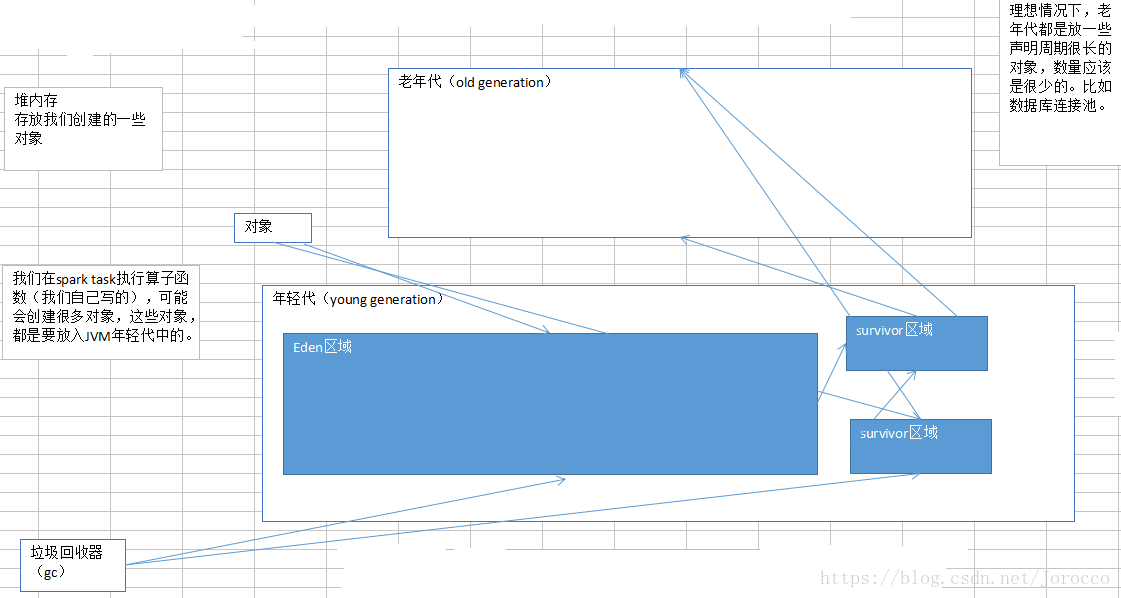
每一次放对象的时候,都是放入eden区域,和其中一个survivor区域;另外一个survivor区域是空闲的。
当eden区域和一个survivor区域放满了以后(spark运行过程中,产生的对象实在太多了),就会触发minor gc,小型垃圾回收。把不再使用的对象,从内存中清空,给后面新创建的对象腾出来点儿地方。
清理掉了不再使用的对象之后,那么也会将存活下来的对象(还要继续使用的),放入之前空闲的那一个survivor区域中。这里可能会出现一个问题。默认eden、survior1和survivor2的内存占比是8:1:1。问题是,如果存活下来的对象是1.5,一个survivor区域放不下。此时就可能通过JVM的担保机制(不同JVM版本可能对应的行为),将多余的对象,直接放入老年代了。
如果你的JVM内存不够大的话,可能导致频繁的年轻代内存满溢,频繁的进行minor gc。频繁的minor gc会导致短时间内,有些存活的对象,多次垃圾回收都没有回收掉。会导致这种短声明周期(其实不一定是要长期使用的)对象,年龄过大,垃圾回收次数太多还没有回收到,跑到老年代。
老年代中,可能会因为内存不足,囤积一大堆,短生命周期的,本来应该在年轻代中的,可能马上就要被回收掉的对象。此时,可能导致老年代频繁满溢。频繁进行full gc(全局/全面垃圾回收)。full gc就会去回收老年代中的对象。full gc由于这个算法的设计,是针对的是,老年代中的对象数量很少,满溢进行full gc的频率应该很少,因此采取了不太复杂,但是耗费性能和时间的垃圾回收算法。full gc很慢。
full gc / minor gc,无论是快,还是慢,都会导致jvm的工作线程停止工作,stop the world。简而言之,就是说,gc的时候,spark停止工作了。等着垃圾回收结束。
内存不充足的时候,问题:
1、频繁minor gc,也会导致频繁spark停止工作
2、老年代囤积大量活跃对象(短生命周期的对象),导致频繁full gc,full gc时间很长,短则数十秒,长则数分钟,甚至数小时。可能导致spark长时间停止工作。
3、严重影响咱们的spark的性能和运行的速度。
8.1 降低cache操作的内存占比
spark中,堆内存又被划分成了两块儿,一块儿是专门用来给RDD的cache、persist操作进行RDD数据缓存用的;另外一块儿,就是我们刚才所说的,用来给spark算子函数的运行使用的,存放函数中自己创建的对象。
默认情况下,给RDD cache操作的内存占比,是0.6,60%的内存都给了cache操作了。但是问题是,如果某些情况下,cache不是那么的紧张,问题在于task算子函数中创建的对象过多,然后内存又不太大,导致了频繁的minor gc,甚至频繁full gc,导致spark频繁的停止工作。性能影响会很大。
针对上述这种情况,大家可以在之前我们讲过的那个spark ui。yarn去运行的话,那么就通过yarn的界面,去查看你的spark作业的运行统计,很简单,大家一层一层点击进去就好。可以看到每个stage的运行情况,包括每个task的运行时间、gc时间等等。如果发现gc太频繁,时间太长。此时就可以适当调价这个比例。
降低cache操作的内存占比,大不了用persist操作,选择将一部分缓存的RDD数据写入磁盘,或者序列化方式,配合Kryo序列化类,减少RDD缓存的内存占用;降低cache操作内存占比;对应的,算子函数的内存占比就提升了。这个时候,可能,就可以减少minor gc的频率,同时减少full gc的频率。对性能的提升是有一定的帮助的。
一句话,让task执行算子函数时,有更多的内存可以使用。
SparkConf.set(spark.storage.memoryFraction,0.6) -> 0.5 -> 0.4 -> 0.28.2 executor堆外内存
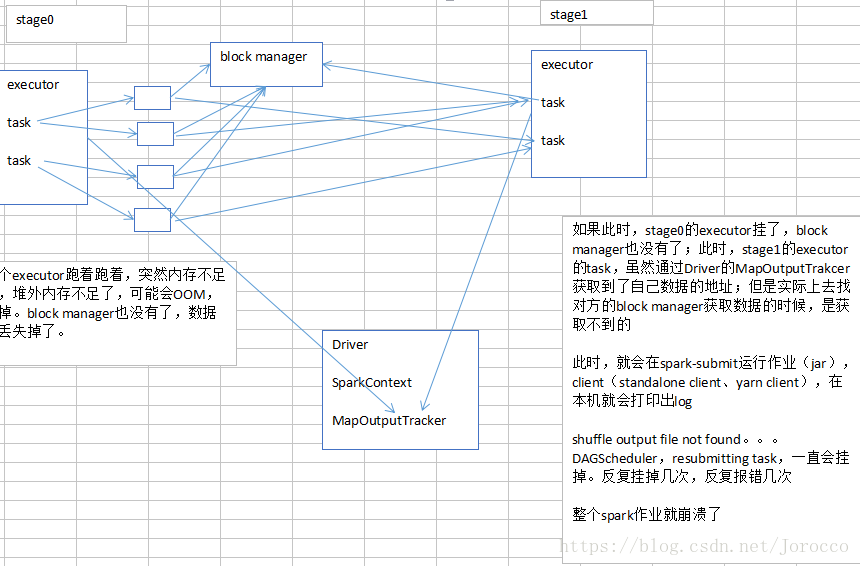
有时候,如果你的spark作业处理的数据量特别特别大,几亿数据量;然后spark作业一运行,时不时的报错,shuffle file cannot find,executor、task lost,out of memory(内存溢出);
可能是说executor的堆外内存不太够用,导致executor在运行的过程中,可能会内存溢出;然后可能导致后续的stage的task在运行的时候,可能要从一些executor中去拉取shuffle map output文件,但是executor可能已经挂掉了,关联的block manager也没有了;所以可能会报shuffle output file not found;resubmitting task;executor lost;spark作业彻底崩溃。
上述情况下,就可以去考虑调节一下executor的堆外内存。也许就可以避免报错;此外,有时,堆外内存调节的比较大的时候,对于性能来说,也会带来一定的提升。
/usr/local/spark/bin/spark-submit \
--class com.ibeifeng.sparkstudy.WordCount \
--num-executors 80 \
--driver-memory 6g \
--executor-memory 6g \
--executor-cores 3 \
--master yarn-cluster \
--queue root.default \
--conf spark.yarn.executor.memoryOverhead=2048 \
--conf spark.core.connection.ack.wait.timeout=300 \
/usr/local/spark/spark.jar \
${1}--conf spark.yarn.executor.memoryOverhead=2048
spark-submit脚本里面,去用--conf的方式,去添加配置;一定要注意!!!切记,不是在你的spark作业代码中,用new SparkConf().set()这种方式去设置,不要这样去设置,是没有用的!一定要在spark-submit脚本中去设置。
spark.yarn.executor.memoryOverhead(看名字,顾名思义,针对的是基于yarn的提交模式)
默认情况下,这个堆外内存上限大概是300多M;后来我们通常项目中,真正处理大数据的时候,这里都会出现问题,导致spark作业反复崩溃,无法运行;此时就会去调节这个参数,到至少1G(1024M),甚至说2G、4G
通常这个参数调节上去以后,就会避免掉某些JVM OOM的异常问题,同时呢,会让整体spark作业的性能,得到较大的提升。8.3 连接等待时长调节
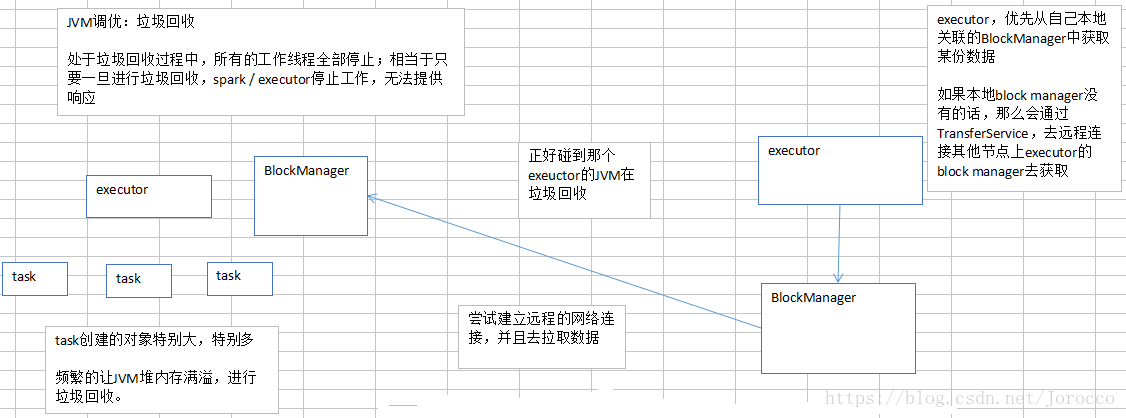
此时呢,就会没有响应,无法建立网络连接;会卡住;ok,spark默认的网络连接的超时时长,是60s;如果卡住60s都无法建立连接的话,那么就宣告失败了。
碰到一种情况,偶尔,偶尔,偶尔!!!没有规律!!!某某file。一串file id。uuid(dsfsfd-2342vs–sdf–sdfsd)。not found。file lost。
这种情况下,很有可能是有那份数据的executor在jvm gc。所以拉取数据的时候,建立不了连接。然后超过默认60s以后,直接宣告失败。
报错几次,几次都拉取不到数据的话,可能会导致spark作业的崩溃。也可能会导致DAGScheduler,反复提交几次stage。TaskScheduler,反复提交几次task。大大延长我们的spark作业的运行时间。
可以考虑调节连接的超时时长。
--conf spark.core.connection.ack.wait.timeout=300
spark-submit脚本,切记,不是在new SparkConf().set()这种方式来设置的。
spark.core.connection.ack.wait.timeout(spark core,connection,连接,ack,wait timeout,建立不上连接的时候,超时等待时长)
调节这个值比较大以后,通常来说,可以避免部分的偶尔出现的某某文件拉取失败,某某文件lost掉了。。。为什么在这里讲这两个参数呢?
因为比较实用,在真正处理大数据(不是几千万数据量、几百万数据量),几亿,几十亿,几百亿的时候。很容易碰到executor堆外内存,以及gc引起的连接超时的问题。file not found,executor lost,task lost。
调节上面两个参数,还是很有帮助的。
9、Shuffle调优
什么样的情况下,会发生shuffle?
在spark中,主要是以下几个算子:groupByKey、reduceByKey、countByKey、join等等。
什么是shuffle?
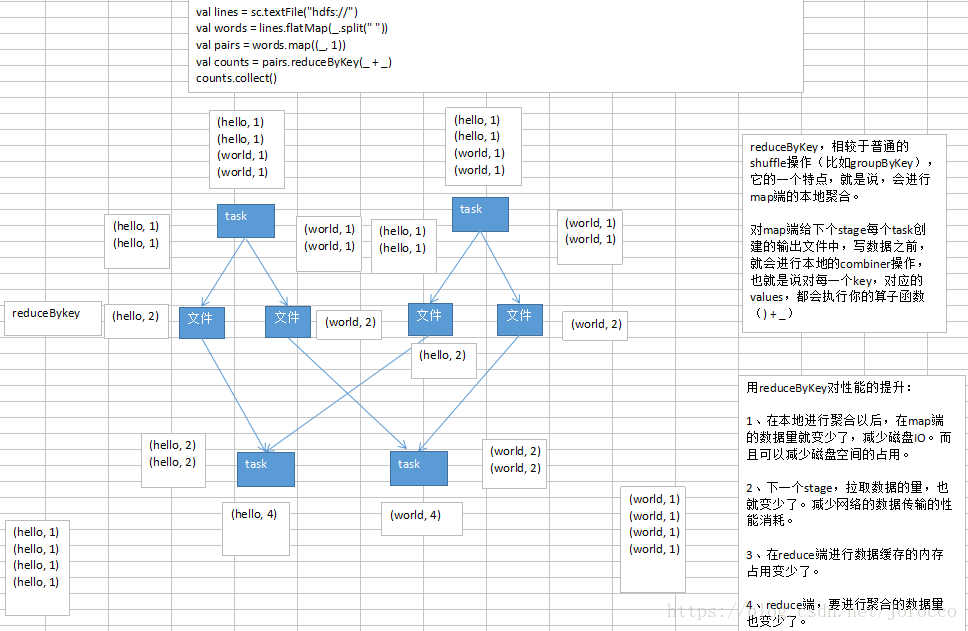
groupByKey,要把分布在集群各个节点上的数据中的同一个key,对应的values,都给集中到一块儿,集中到集群中同一个节点上,更严密一点说,就是集中到一个节点的一个executor的一个task中。
然后呢,集中一个key对应的values之后,才能交给我们来进行处理,<key, Iterable<value>>;reduceByKey,算子函数去对values集合进行reduce操作,最后变成一个value;countByKey,需要在一个task中,获取到一个key对应的所有的value,然后进行计数,统计总共有多少个value;join,RDD<key, value>,RDD<key, value>,只要是两个RDD中,key相同对应的2个value,都能到一个节点的executor的task中,给我们进行处理。
reduceByKey(_+_)问题在于,同一个单词,比如说(hello, 1),可能散落在不同的节点上;对每个单词进行累加计数,就必须让所有单词都跑到同一个节点的一个task中,给一个task来进行处理。
shuffle,一定是分为两个stage来完成的。因为这其实是个逆向的过程,不是stage决定shuffle,是shuffle决定stage。
reduceByKey(_+_),在某个action触发job的时候,DAGScheduler,会负责划分job为多个stage。划分的依据,就是,如果发现有会触发shuffle操作的算子,比如reduceByKey,就将这个操作的前半部分,以及之前所有的RDD和transformation操作,划分为一个stage;shuffle操作的后半部分,以及后面的,直到action为止的RDD和transformation操作,划分为另外一个stage。
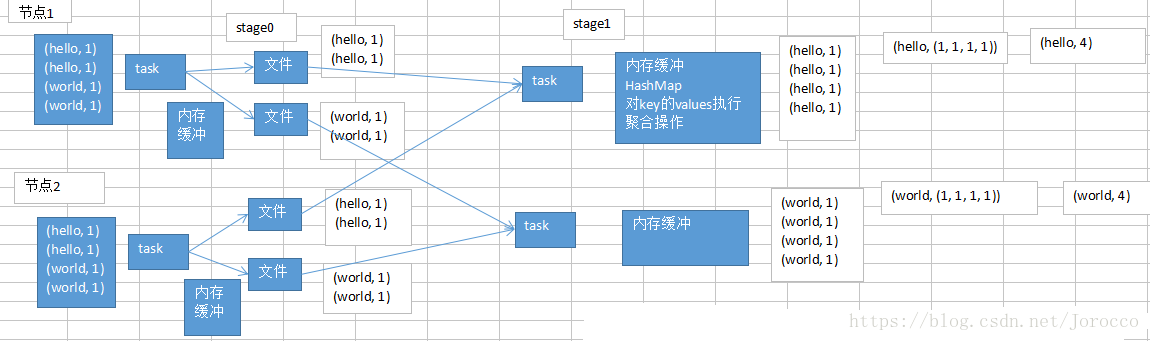
shuffle前半部分的task在写入数据到磁盘文件之前,都会先写入一个一个的内存缓冲,内存缓冲满溢之后,再spill溢写到磁盘文件中。
每一个shuffle的前半部分stage的task,每个task都会创建下一个stage的task数量相同的文件,比如下一个stage会有100个task,那么当前stage每个task都会创建100份文件;会将同一个key对应的values,一定是写入同一个文件中的;不同节点上的task,也一定会将同一个key对应的values,写入下一个stage,同一个task对应的文件中。
shuffle的后半部分stage的task,每个task都会从各个节点上的task写的属于自己的那一份文件中,拉取key, value对;然后task会有一个内存缓冲区,然后会用HashMap,进行key, values的汇聚;(key ,values);
task会用我们自己定义的聚合函数,比如reduceByKey(_+_),把所有values进行一对一的累加;聚合出来最终的值。就完成了shuffle。
9.1 Shuffle调优之合并map端输出文件
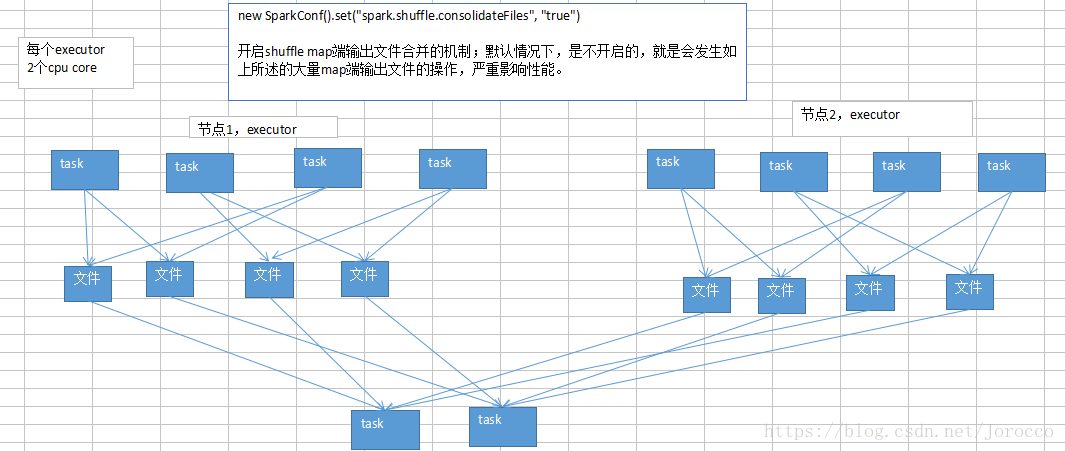
开启了map端输出文件的合并机制之后:
第一个stage,同时就运行cpu core个task,比如cpu core是2个,并行运行2个task;每个task都创建下一个stage的task数量个文件;
第一个stage,并行运行的2个task执行完以后;就会执行另外两个task;另外2个task不会再重新创建输出文件;而是复用之前的task创建的map端输出文件,将数据写入上一批task的输出文件中。
第二个stage,task在拉取数据的时候,就不会去拉取上一个stage每一个task为自己创建的那份输出文件了;而是拉取少量的输出文件,每个输出文件中,可能包含了多个task给自己的map端输出。
提醒一下(map端输出文件合并):
只有并行执行的task会去创建新的输出文件;下一批并行执行的task,就会去复用之前已有的输出文件;但是有一个例外,比如2个task并行在执行,但是此时又启动要执行2个task;那么这个时候的话,就无法去复用刚才的2个task创建的输出文件了;而是还是只能去创建新的输出文件。
要实现输出文件的合并的效果,必须是一批task先执行,然后下一批task再执行,才能复用之前的输出文件;负责多批task同时起来执行,还是做不到复用的。
开启了map端输出文件合并机制之后,生产环境上的例子,会有什么样的变化?
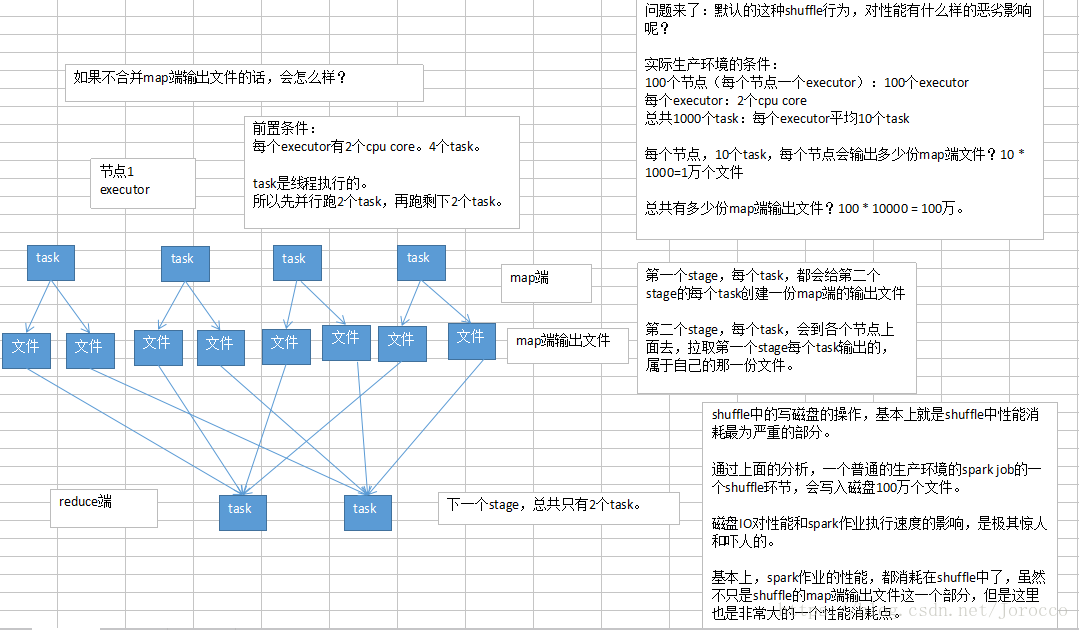
实际生产环境的条件:
100个节点(每个节点一个executor):100个executor
每个executor:2个cpu core
总共1000个task:每个executor平均10个task
每个节点,2个cpu core,有多少份输出文件呢?2 * 1000 = 2000个
总共100个节点,总共创建多少份输出文件呢?100 * 2000 = 20万个文件
相比较开启合并机制之前的情况,100万个
map端输出文件,在生产环境中,立减5倍!
合并map端输出文件,对咱们的spark的性能有哪些方面的影响呢?
1、map task写入磁盘文件的IO,减少:100万文件 -> 20万文件
2、第二个stage,原本要拉取第一个stage的task数量份文件,1000个task,第二个stage的每个task,都要拉取1000份文件,走网络传输;合并以后,100个节点,每个节点2个cpu core,第二个stage的每个task,主要拉取100 * 2 = 200个文件即可;网络传输的性能消耗是不是也大大减少
分享一下,实际在生产环境中,使用了spark.shuffle.consolidateFiles机制以后,实际的性能调优的效果:对于上述的这种生产环境的配置,性能的提升,还是相当的客观的。spark作业,5个小时 -> 2~3个小时。
大家不要小看这个map端输出文件合并机制。实际上,在数据量比较大,你自己本身做了前面的性能调优,executor上去->cpu core上去->并行度(task数量)上去,shuffle没调优,shuffle就很糟糕了;大量的map端输出文件的产生。对性能有比较恶劣的影响。
这个时候,去开启这个机制,可以很有效的提升性能。
9.2 Shuffle调优之调节map端内存缓冲与reduce端内存占比
spark.shuffle.file.buffer,默认32k
spark.shuffle.memoryFraction,0.2map端内存缓冲,reduce端内存占比;很多资料、网上视频,都会说,这两个参数,是调节shuffle性能的不二选择,很有效果的样子,实际上,不是这样的。
以实际的生产经验来说,这两个参数没有那么重要,往往来说,shuffle的性能不是因为这方面的原因导致的
但是,有一点点效果的,broadcast,数据本地化等待时长;这两个shuffle调优的小点,其实也是需要跟其他的大量的小点配合起来使用,一点一点的提升性能,最终很多个性能调优的小点的效果,汇集在一起之后,那么就会有可以看见的还算不错的性能调优的效果。
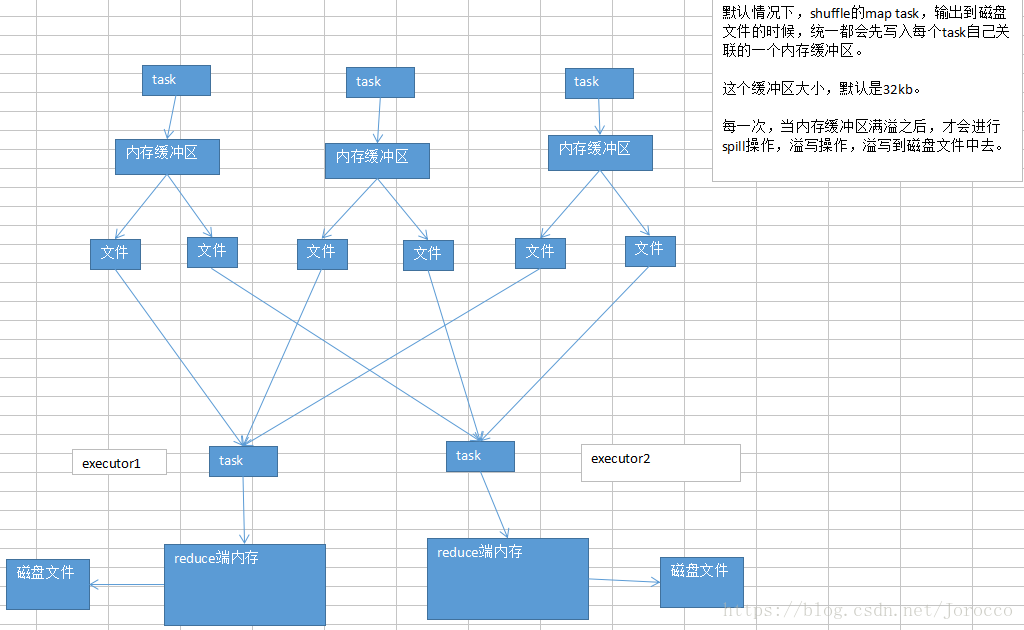
educe端task,在拉取到数据之后,会用hashmap的数据格式,来对各个key对应的values进行汇聚。
针对每个key对应的values,执行我们自定义的聚合函数的代码,比如_ + _(把所有values累加起来)
reduce task,在进行汇聚、聚合等操作的时候,实际上,使用的就是自己对应的executor的内存,executor(jvm进程,堆),默认executor内存中划分给reduce task进行聚合的比例,是0.2。
问题来了,因为比例是0.2,所以,理论上,很有可能会出现,拉取过来的数据很多,那么在内存中,放不下;这个时候,默认的行为,就是说,将在内存放不下的数据,都spill(溢写)到磁盘文件中去。
原理说完之后,来看一下,默认情况下,不调优,可能会出现什么样的问题?
默认,map端内存缓冲是每个task,32kb。
默认,reduce端聚合内存比例,是0.2,也就是20%。
如果map端的task,处理的数据量比较大,但是呢,你的内存缓冲大小是固定的。可能会出现什么样的情况?
每个task就处理320kb,32kb,总共会向磁盘溢写320 / 32 = 10次。
每个task处理32000kb,32kb,总共会向磁盘溢写32000 / 32 = 1000次。
在map task处理的数据量比较大的情况下,而你的task的内存缓冲默认是比较小的,32kb。可能会造成多次的map端往磁盘文件的spill溢写操作,发生大量的磁盘IO,从而降低性能。
reduce端聚合内存,占比。默认是0.2。如果数据量比较大,reduce task拉取过来的数据很多,那么就会频繁发生reduce端聚合内存不够用,频繁发生spill操作,溢写到磁盘上去。而且最要命的是,磁盘上溢写的数据量越大,后面在进行聚合操作的时候,很可能会多次读取磁盘中的数据,进行聚合。
默认不调优,在数据量比较大的情况下,可能频繁地发生reduce端的磁盘文件的读写。
这两个点之所以放在一起讲,是因为他们俩是有关联的。数据量变大,map端肯定会出点问题;reduce端肯定也会出点问题;出的问题是一样的,都是磁盘IO频繁,变多,影响性能。
调优:
调节map task内存缓冲:spark.shuffle.file.buffer,默认32k(spark 1.3.x不是这个参数,后面还有一个后缀,kb;spark 1.5.x以后,变了,就是现在这个参数)
调节reduce端聚合内存占比:spark.shuffle.memoryFraction,0.2
在实际生产环境中,我们在什么时候来调节两个参数?
看Spark UI,如果你的公司是决定采用standalone模式,那么狠简单,你的spark跑起来,会显示一个Spark UI的地址,4040的端口,进去看,依次点击进去,可以看到,你的每个stage的详情,有哪些executor,有哪些task,每个task的shuffle write和shuffle read的量,shuffle的磁盘和内存,读写的数据量;如果是用的yarn模式来提交,课程最前面,从yarn的界面进去,点击对应的application,进入Spark UI,查看详情。
如果发现shuffle 磁盘的write和read,很大。这个时候,就意味着最好调节一些shuffle的参数。进行调优。首先当然是考虑开启map端输出文件合并机制。
调节上面说的那两个参数。调节的时候的原则。spark.shuffle.file.buffer,每次扩大一倍,然后看看效果,64,128;spark.shuffle.memoryFraction,每次提高0.1,看看效果。
不能调节的太大,太大了以后过犹不及,因为内存资源是有限的,你这里调节的太大了,其他环节的内存使用就会有问题了。
调节了以后,效果?map task内存缓冲变大了,减少spill到磁盘文件的次数;reduce端聚合内存变大了,减少spill到磁盘的次数,而且减少了后面聚合读取磁盘文件的数量。
9.3 Shuffle性能调优之HashShuffleManager与SortShuffleManager
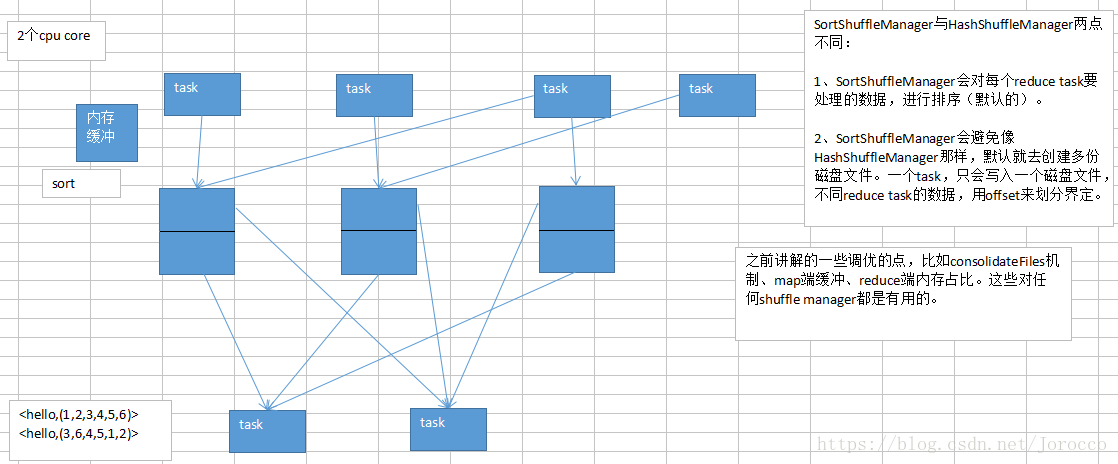
来一个总结,hash、sort、tungsten-sort。如何来选择?
1、需不需要数据默认就让spark给你进行排序?就好像mapreduce,默认就是有按照key的排序。如果不需要的话,其实还是建议搭建就使用最基本的HashShuffleManager,因为最开始就是考虑的是不排序,换取高性能;
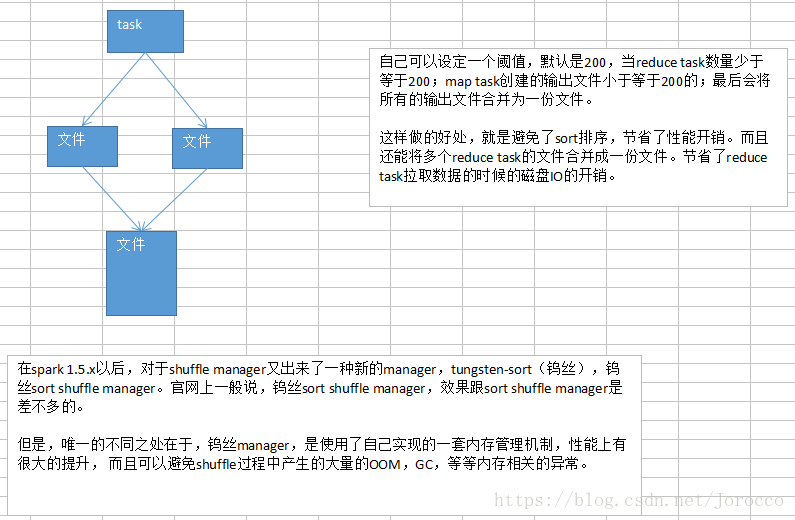
2、什么时候需要用sort shuffle manager?如果你需要你的那些数据按key排序了,那么就选择这种吧,而且要注意,reduce task的数量应该是超过200的,这样sort、merge(多个文件合并成一个)的机制,才能生效。但是这里要注意,你一定要自己考量一下,有没有必要在shuffle的过程中,就做这个事情,毕竟对性能是有影响的。
3、如果你不需要排序,而且你希望你的每个task输出的文件最终是会合并成一份的,你自己认为可以减少性能开销;可以去调节bypassMergeThreshold这个阈值,比如你的reduce task数量是500,默认阈值是200,所以默认还是会进行sort和直接merge的;可以将阈值调节成550,不会进行sort,按照hash的做法,每个reduce task创建一份输出文件,最后合并成一份文件。(这个参数,其实我们通常不会在生产环境里去使用,也没有经过验证说,这样的方式,到底有多少性能的提升)
4、如果你想选用sort based shuffle manager,而且你们公司的spark版本比较高,是1.5.x版本的,那么可以考虑去尝试使用tungsten-sort shuffle manager。看看性能的提升与稳定性怎么样。
总结:
1、在生产环境中,不建议大家贸然使用第三点和第四点:
2、如果你不想要你的数据在shuffle时排序,那么就自己设置一下,用hash shuffle manager。
3、如果你的确是需要你的数据在shuffle时进行排序的,那么就默认不用动,默认就是sort shuffle manager;或者是什么?如果你压根儿不care是否排序这个事儿,那么就默认让他就是sort的。调节一些其他的参数(consolidation机制)。(80%,都是用这种)
spark.shuffle.manager:hash、sort、tungsten-sort
new SparkConf().set("spark.shuffle.manager", "hash")
new SparkConf().set("spark.shuffle.manager", "tungsten-sort")
// 默认就是,new SparkConf().set("spark.shuffle.manager", "sort")
new SparkConf().set("spark.shuffle.sort.bypassMergeThreshold", "550")10、算子调优
10.1 算子调优之MapPartitions
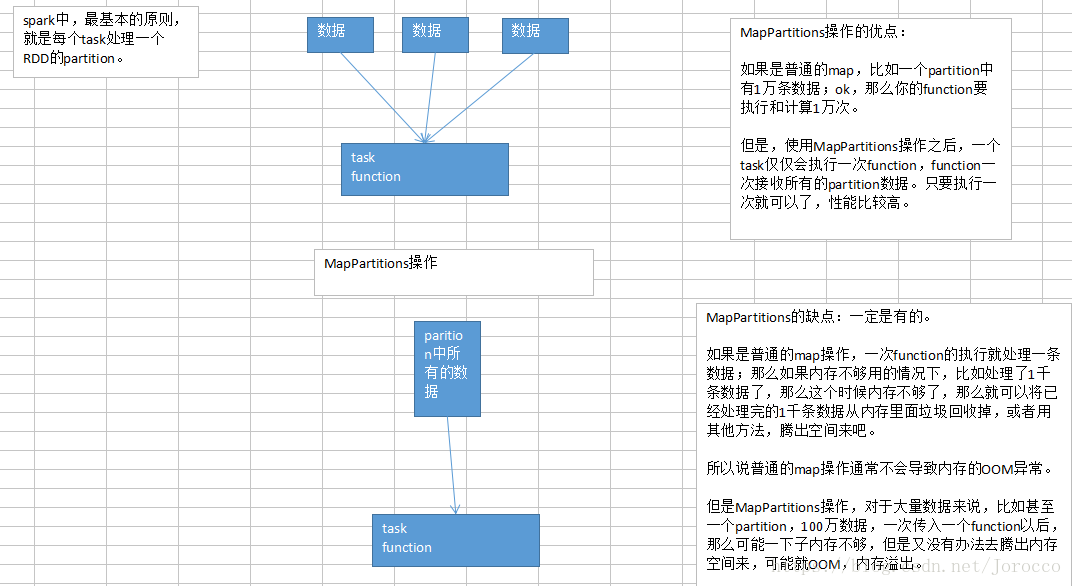
什么时候比较适合用MapPartitions系列操作,就是说,数据量不是特别大的时候,都可以用这种MapPartitions系列操作,性能还是非常不错的,是有提升的。比如原来是15分钟,(曾经有一次性能调优),12分钟。10分钟->9分钟。
但是也有过出问题的经验,MapPartitions只要一用,直接OOM,内存溢出,崩溃。
在项目中,自己先去估算一下RDD的数据量,以及每个partition的量,还有自己分配给每个executor的内存资源。看看一下子内存容纳所有的partition数据,行不行。如果行,可以试一下,能跑通就好。性能肯定是有提升的。
但是试了一下以后,发现,不行,OOM了,那就放弃吧。
//采用mapPartitions替代map优化性能
return actionRDD.mapPartitionsToPair(new PairFlatMapFunction<Iterator<Row>,String,Row>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(Iterator<Row> iterator) throws Exception {
List<Tuple2<String,Row>>list=new ArrayList<Tuple2<String,Row>>();
while(iterator.hasNext()) {
Row row=iterator.next();
list.add(new Tuple2<String, Row>(row.getString(2),row));
}
return list;
}
});10.2 算子调优之filter过后使用coalesce减少分区数量
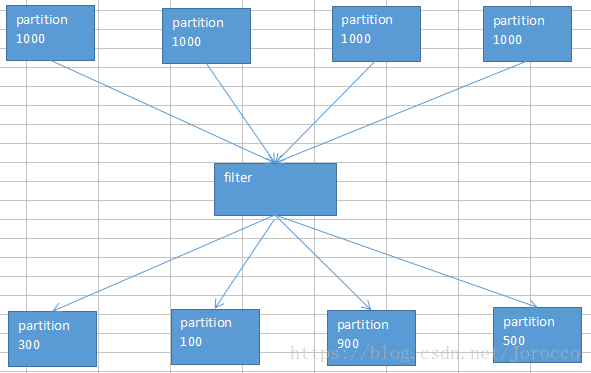
默认情况下,经过了这种filter之后,RDD中的每个partition的数据量,可能都不太一样了。(原本每个partition的数据量可能是差不多的)
问题:
1、每个partition数据量变少了,但是在后面进行处理的时候,还是要跟partition数量一样数量的task,来进行处理;有点浪费task计算资源。
2、每个partition的数据量不一样,会导致后面的每个task处理每个partition的时候,每个task要处理的数据量就不同,这个时候很容易发生什么问题?数据倾斜。。。。
比如说,第二个partition的数据量才100;但是第三个partition的数据量是900;那么在后面的task处理逻辑一样的情况下,不同的task要处理的数据量可能差别达到了9倍,甚至10倍以上;同样也就导致了速度的差别在9倍,甚至10倍以上。
这样的话呢,就会导致有些task运行的速度很快;有些task运行的速度很慢。这,就是数据倾斜。
针对上述的两个问题,我们希望应该能够怎么样?
1、针对第一个问题,我们希望可以进行partition的压缩吧,因为数据量变少了,那么partition其实也完全可以对应的变少。比如原来是4个partition,现在完全可以变成2个partition。那么就只要用后面的2个task来处理即可。就不会造成task计算资源的浪费。(不必要,针对只有一点点数据的partition,还去启动一个task来计算)
2、针对第二个问题,其实解决方案跟第一个问题是一样的;也是去压缩partition,尽量让每个partition的数据量差不多。那么这样的话,后面的task分配到的partition的数据量也就差不多。不会造成有的task运行速度特别慢,有的task运行速度特别快。避免了数据倾斜的问题。
有了解决问题的思路之后,接下来,我们该怎么来做呢?实现?
coalesce算子
主要就是用于在filter操作之后,针对每个partition的数据量各不相同的情况,来压缩partition的数量。减少partition的数量,而且让每个partition的数据量都尽量均匀紧凑。
从而便于后面的task进行计算操作,在某种程度上,能够一定程度的提升性能。
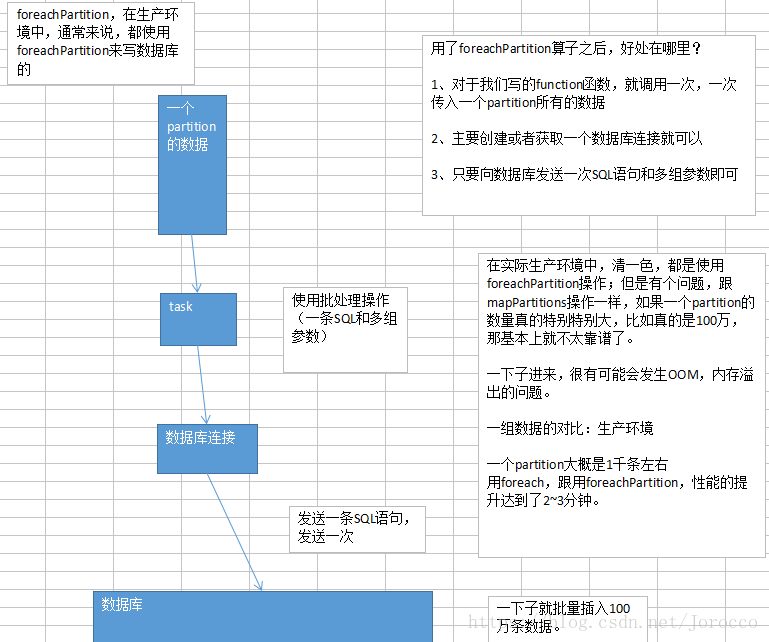
10.3 算子调优之使用foreachPartition优化写数据库性能
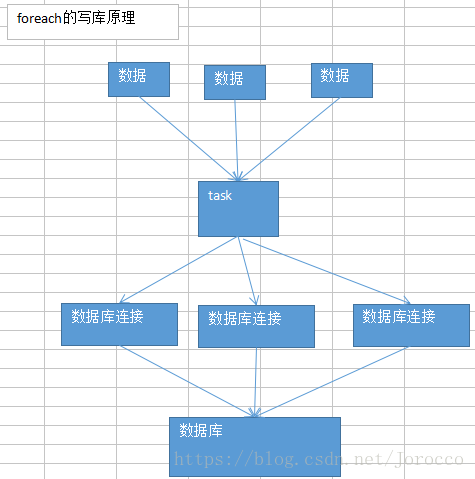
默认的foreach的性能缺陷在哪里?
首先,对于每条数据,都要单独去调用一次function,task为每个数据,都要去执行一次function函数。
如果100万条数据,(一个partition),调用100万次。性能比较差。
另外一个非常非常重要的一点
如果每个数据,你都去创建一个数据库连接的话,那么你就得创建100万次数据库连接。
但是要注意的是,数据库连接的创建和销毁,都是非常非常消耗性能的。虽然我们之前已经用了数据库连接池,只是创建了固定数量的数据库连接。
你还是得多次通过数据库连接,往数据库(MySQL)发送一条SQL语句,然后MySQL需要去执行这条SQL语句。如果有100万条数据,那么就是100万次发送SQL语句。
以上两点(数据库连接,多次发送SQL语句),都是非常消耗性能的。
/*
* 使用foreachPartition取代foreach优化写数据库性能
*
* */
extractSessionDetailRDD.foreachPartition(
new VoidFunction<Iterator<Tuple2<String,Tuple2<String,Row>>>>(){
private static final long serialVersionUID = 1L;
@Override
public void call(
Iterator<Tuple2<String, Tuple2<String, Row>>> iterator)
throws Exception {
List<SessionDetail>sessionDetails=new ArrayList<SessionDetail>();
while(iterator.hasNext()) {
Tuple2<String,Tuple2<String,Row>>tuple=iterator.next();
Row row=tuple._2._2;
SessionDetail sessionDetail=new SessionDetail();
sessionDetail.setTaskid(taskid);
sessionDetail.setUserid(row.getLong(1));
sessionDetail.setSessionid(row.getString(2));
sessionDetail.setPageid(row.getLong(3));
sessionDetail.setActionTime(row.getString(4));
sessionDetail.setSearchKeyWord(row.getString(5));
sessionDetail.setClickCategoryId(row.getLong(6));
sessionDetail.setClickProductId(row.getLong(7));
sessionDetail.setOrderCategoryIds(row.getString(8));
sessionDetail.setOrderProductIds(row.getString(9));
sessionDetail.setPayCategoryIds(row.getString(10));
sessionDetail.setPayProductIds(row.getString(11));
sessionDetails.add(sessionDetail);
}
ISessionDetailDAO sessionDetatilDAO=DAOFactory.getSessionDetailDAO();
sessionDetatilDAO.insertBatch(sessionDetails);
}
});10.4 算子调优之使用repartition解决Spark SQL低并行度的性能问题
并行度:之前说过,并行度是自己可以调节,或者说是设置的。
1、spark.default.parallelism
2、textFile(),传入第二个参数,指定partition数量(比较少用)
咱们的项目代码中,没有设置并行度,实际上,在生产环境中,是最好自己设置一下的。官网有推荐的设置方式,你的spark-submit脚本中,会指定你的application总共要启动多少个executor,100个;每个executor多少个cpu core,2~3个;总共application,有cpu core,200个。
官方推荐,根据你的application的总cpu core数量(在spark-submit中可以指定,200个),自己手动设置spark.default.parallelism参数,指定为cpu core总数的2~3倍。400~600个并行度。600。
承上启下
你设置的这个并行度,在哪些情况下会生效?哪些情况下,不会生效?
如果你压根儿没有使用Spark SQL(DataFrame),那么你整个spark application默认所有stage的并行度都是你设置的那个参数。(除非你使用coalesce算子缩减过partition数量)
问题来了,Spark SQL,用了。用Spark SQL的那个stage的并行度,你没法自己指定。Spark SQL自己会默认根据hive表对应的hdfs文件的block,自动设置Spark SQL查询所在的那个stage的并行度。你自己通过spark.default.parallelism参数指定的并行度,只会在没有Spark SQL的stage中生效。
比如你第一个stage,用了Spark SQL从hive表中查询出了一些数据,然后做了一些transformation操作,接着做了一个shuffle操作(groupByKey);下一个stage,在shuffle操作之后,做了一些transformation操作。hive表,对应了一个hdfs文件,有20个block;你自己设置了spark.default.parallelism参数为100。
你的第一个stage的并行度,是不受你的控制的,就只有20个task;第二个stage,才会变成你自己设置的那个并行度,100。
问题在哪里?
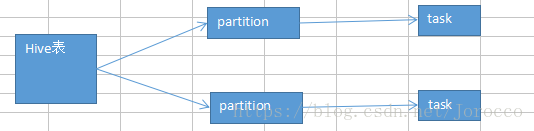
Spark SQL默认情况下,它的那个并行度,咱们没法设置。可能导致的问题,也许没什么问题,也许很有问题。Spark SQL所在的那个stage中,后面的那些transformation操作,可能会有非常复杂的业务逻辑,甚至说复杂的算法。如果你的Spark SQL默认把task数量设置的很少,20个,然后每个task要处理为数不少的数据量,然后还要执行特别复杂的算法。
这个时候,就会导致第一个stage的速度,特别慢。第二个stage,1000个task,刷刷刷,非常快。
解决上述Spark SQL无法设置并行度和task数量的办法,是什么呢?
repartition算子,你用Spark SQL这一步的并行度和task数量,肯定是没有办法去改变了。但是呢,可以将你用Spark SQL查询出来的RDD,使用repartition算子,去重新进行分区,此时可以分区成多个partition,比如从20个partition,分区成100个。
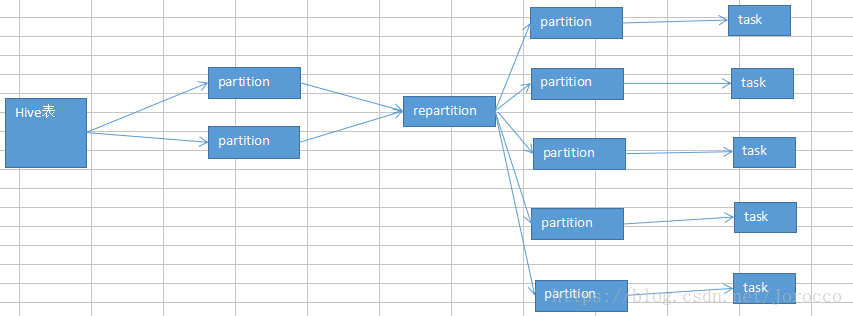
然后呢,从repartition以后的RDD,再往后,并行度和task数量,就会按照你预期的来了。就可以避免跟Spark SQL绑定在一个stage中的算子,只能使用少量的task去处理大量数据以及复杂的算法逻辑。
/*
* 这里就很有可能发生SparkSQL低并行度问题
* 比如说,Spark SQL默认就给第一个stage设置了20个task,但是根据你的数量以及算法的复杂度
* 实际上,需要1000个task去并行执行
*
* 所以说,在这里就可以对Spark SQL刚刚查询出来的RDD执行repartition重分区操作
*
*
* */
// return actionDF.javaRDD().repartition(1000);//此处由于是本地模式不存在这个问题,生产模式下则可能10.5 算子调优之reduceByKey
总结:
reduceByKey在什么情况下使用呢?
1、非常普通的,比如说,就是要实现类似于wordcount程序一样的,对每个key对应的值,进行某种数据公式或者算法的计算(累加、类乘)
2、对于一些类似于要对每个key进行一些字符串拼接的这种较为复杂的操作,可以自己衡量一下,其实有时,也是可以使用reduceByKey来实现的。但是不太好实现。如果真能够实现出来,对性能绝对是有帮助的。(shuffle基本上就占了整个spark作业的90%以上的性能消耗,主要能对shuffle进行一定的调优,都是有价值的)