Scrapy中XPath选择器的基本用法
1、前言
本文是作为爬虫项目实战一:基于Scrapy+MongDB爬取并存储糗事百科用户信息的补充,所以本文的网页选择也是基于糗事百科展开。XPath主要使用在XML文档中选择节点,同时XPath也适用于HTML。网页中,标签元素的关系有:先辈节点、父节点、子节点、同级节点、后辈节点。XPath用法很多,这里不会全部列出来,主要是列出来了,上篇blog中使用过的一些方法进行总结。如果不对之处,还望批评指正。想更详细了解用法,请参考W3CSchool XPath教程和官方文档
注意以下代码截图都是基于糗事百科网址(https://www.qiushibaike.com/hot/page/1/),同时测试代码实在Pycharm中进行,通过配置scrapy settings中的请求中添加User-Agent字段,然后在Pycharm的Terminal终端输入scrapy shell https://www.qiushibaike.com/hot/page/1/ 命令进入交互模式进行。
如下图:

2、多级定位和跳级定位标签元素
1. 多级定位
从根节点开始选择定位,通常是以"/"开头,返回所有匹配的子节点选择器列表。
例如:我要定位下面的body标签。

那么多级定位的写法应该是:r = response.xpath(’/html/body’),这里找到了一个,所以返回的是包含一个选择器元素的列表。

再比如,r = response.xpath(’/html/body/div’),这里会返回包含5个选择器元素的列表,第一个div没有被捕获,可能是因为里面涉及到了js,具体原因自己还没有弄明白。(有知道的大佬,希望能评论告知)。


2. 跳级定位
不用从根节点匹配,而是全局匹配,有匹配的结果返回一个选择器列表。通常是以"//"开头。
见下面的示例,注意这个时候会全局去匹配,所以它会去子孙节点中寻找符合调节的标签,全部返回。因此需要准确定位的话,最好先加上一些属性进行定位,后面会讲到。

3. 利用属性更加准确的定位标签
每个html元素都有很多属性,如id、class、title、href、text等,这些属性往往具有很强的特殊性,结合元素多级定位或跳级定位会更准确高效,比如:定位body标签下的id="header"的div标签。
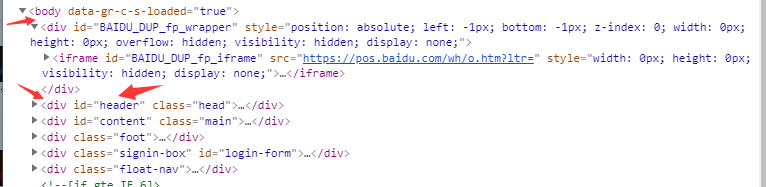
语法就是:r = response.xpath(’//body/div[@id=“header”]’),结果如下。

4. 提取定位标签中的text信息
首先准确定位到要提取text的标签,然后在后面加上"/text()"即可,调用get()方法或者getall()方法获得。
语法:r = response.xpath(’//head/title/text()’).get()
这是提取head标签下的title节点中的文本信息。

我们再提取第一个用户发表的段子信息。
r = response.xpath(’//div[@class=“col1”]/div’)[0].xpath(’./a/div[@class=“content”]/span/text()’).get()
.xpath(’./a/div[@class=“content”]/span/text()’).get()中的./div代表当前节点下的div节点,依次类推。


结果我们看到之匹配了第一句,后面的没有匹配。所以这里我们采用getall()方法。
r = response.xpath(’//div[@class=“col1”]/div’)[0].xpath(’./a/div[@class=“content”]/span/text()’).getall()

Ps:注意要检查是否是准确定位,写这篇总结时,发现原来的匹配方式:r = response.xpath(’//div[@class=“col1”]/div’)[0].xpath(’./a/div/span/text()’).getall()会全部两个a标签下div标签中所有span节点的text。(这里重新加载了网页)


综上,在多级选取和跳级选取中要多配合属性等来达到准确定位,其次要注意多余匹配情况的发生,检查结果是否准确!
更精确的提取:
r = response.xpath(’//div[@class=“col1”]/div’)[0].xpath(’./a/div[@class=“content”]/span’)[0].xpath(’./text()’).getall().

5. 提取定位标签中的属性信息
我们要提取div标签中的class属性值,首先定位到相应的标签,然后在后面加上“/@classs”,调用get()方法或者getall()方法获得。


之后这个字符串经过切片等处理,提取出来性别。