版权声明:路漫漫其修远兮,吾将上下而求索。 https://blog.csdn.net/Happy_Sunshine_Boy/article/details/86740475
文章目录
1. HDFS整体运行机制
- hdfs:分布式文件系统
- hdfs有着文件系统共同的特征:
- 有目录结构,顶层目录是:/
- 系统中存放的就是文件
- 系统可以提供对文件的:创建、删除、修改、查询、移动等功能
- hdfs跟普通的单机文件系统有区别:
- 单机文件系统中存放的文件,是在一台机器的操作系统中
- hdfs的文件系统会横跨N多台机器
- 单机文件系统中存放的文件,是在一台机器的磁盘上
- hdfs文件系统中存放的文件,是落在N多机器的本地单机文件系统中(hdfs是一个基于linux本地文件系统之上的文件系统)
- hdfs的工作机制:
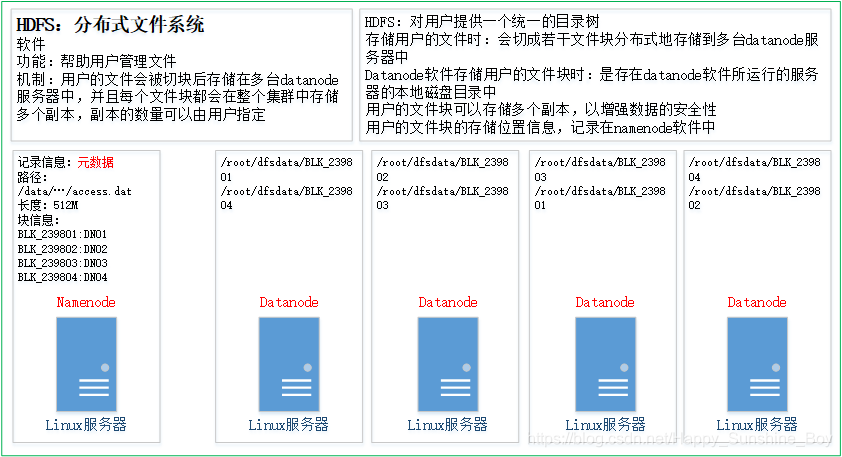
- 客户把一个文件存入hdfs,其实hdfs会把这个文件切块后,分散存储在N台linux机器系统中(负责存储文件块的角色:data node)<准确来说:切块的行为是由客户端决定的>
- 一旦文件被切块存储,那么,hdfs中就必须有一个机制,来记录用户的每一个文件的切块信息,及每一块的具体存储机器(负责记录块信息的角色是:name node)
- 为了保证数据的安全性,hdfs可以将每一个文件块在集群中存放多个副本(到底存几个副本,是由当时存入该文件的客户端指定的,默认是3个副本)
- 综述:一个hdfs系统,由一台运行了namenode的服务器,和N台运行了datanode的服务器组成!
2. HDFS的核心工作原理
2.1 什么是元数据?
- hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置datanode)
2.2 元数据由谁负责管理?
- NameNode
2.3 namenode把元数据记录在哪里?
- namenode的实时的完整的元数据存储在内存中;
- namenode还会在磁盘中(df.namenode.name.dir)存储内存元数据在某个时间点上的镜像文件;
- namenode会把引起元数据变化的客户端操作记录在edits日志文件中;
2.4 综述
- Secondary namenode 会定期从namenode上下载fsimage镜像和新生成的edits日志文件,然后加载到fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合);
- 整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传给namenode
- 上述过程被称为:checkpoint操作
- 提示:Secondary namenode 每次做checkpoint操作时,都需要从namenode上下载上次的fsimage镜像文件吗?
- 第一次checkpoint需要下载,以后就不需要下载了,因为自己的机器上已经有了fsimage镜像文件。

3. 安装HDFS集群的具体步骤
3.1 集群节点规划
| 组件 | 描述 |
|---|---|
| 操作系统 | Centos7.5 |
| Hadoop | 3.1.1 |
| OracleJDK8 | JDK 1.8.0_77 |
| X86 | X86-64 |
| Hostname | IP | Functions | 内存 | 磁盘 |
|---|---|---|---|---|
| hdp-01 | 192.168.121.61 | namenode | 2G | 50G |
| hdp-02 | 192.168.121.62 | datanode | 2G | 50G |
| hdp-03 | 192.168.121.63 | datanode | 2G | 50G |
| hdp-04 | 192.168.121.64 | datanode | 2G | 50G |
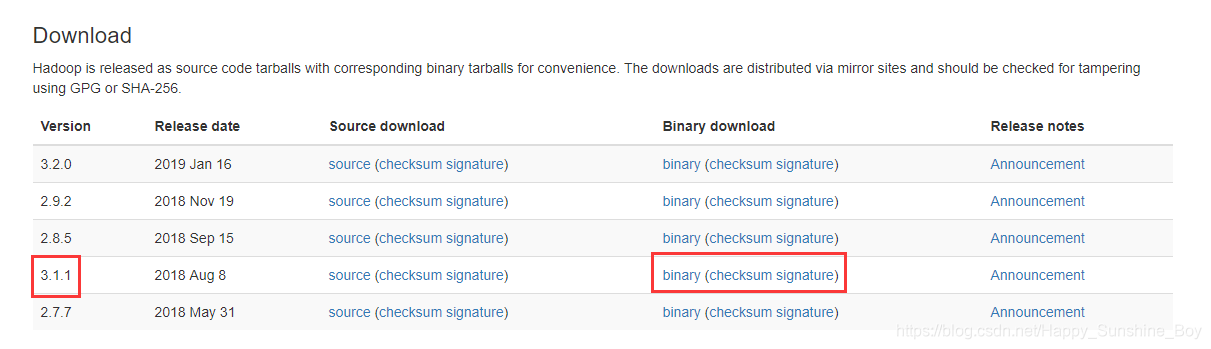
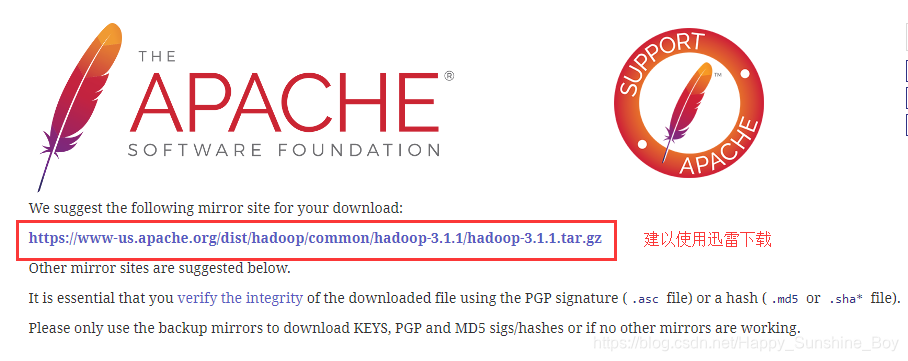
- Hadoop下载,使用迅雷下载,速度较快:https://hadoop.apache.org/releases.html
3.2 搭建hdp-01虚拟机
- 虚拟机搭建 => 静态IP配置 => 防火墙设置 => 设置hosts => 设置阿里镜像源 => 安装时间同步服务ntp => 安装jdk => 关闭Selinux和THP等 过程参照 Apache Ambari-2.7.3+Centos7离线安装–虚拟机安装
- 设置hosts:vi /etc/hosts

- 设置hostname:hostnamectl set-hostname hdp-01
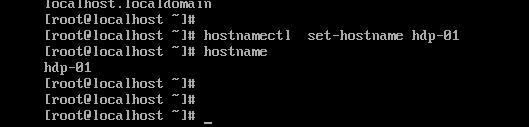
- 上传hadoop安装包到hdp-01
- 新建文件:mkdir /usr/hadoop
- 解压hadoop:tar -zxvf hadoop-3.1.1.tar.gz -C /usr/hadoop/
3.3 hdp-01虚拟机修改配置文件
| 要点 | 核心配置参数 |
|---|---|
| 1 | 指定hadoop的默认文件系统为:hdfs |
| 2 | 指定hdfs的namenode节点为哪台机器 |
| 3 | 指定namenode软件存储元数据的本地目录 |
| 4 | 指定datanode软件存放文件块的本地目录 |
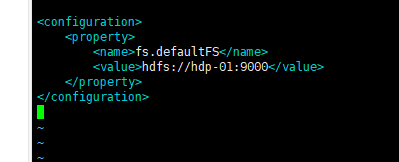
- 1.指定hadoop的默认文件系统为:hdfs
- 编辑文件:vim /usr/hadoop/hadoop-3.1.1/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-01:9000</value>
</property>
</configuration>
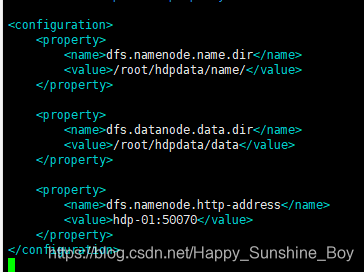
- 编辑文件:vim /usr/hadoop/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
- 2.指定hdfs的namenode节点为哪台机器
- 3.指定namenode软件存储元数据的本地目录
- 4.指定datanode软件存放文件块的本地目录
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hdpdata/name/</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hdpdata/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hdp-01:50070</value>
</property>
</configuration>
- 配置Hadoop路径:vim /etc/profile

- source /etc/profile
3.4 克隆虚拟机hdp-01
- 克隆虚拟机hdp-01 => hdp-02/3/4 => 修改静态IP => 设置hostname => 配置hdp-01 => hdp-02/3/4的免密登录 等 操作步骤参考: Apache Ambari-2.7.3+Centos7离线安装–虚拟机克隆
3.5 在hdp-01节点启动namenode进程
- 首先,初始化namenode的元数据目录
- 要在hdp-01上执行hadoop的一个命令来初始化namenode的元数据存储目录
- 创建一个全新的元数据存储目录
- 生成记录元数据的文件fsimage
- 生成集群的相关标识:如:集群id——clusterID
hadoop namenode -format
- 然后,启动namenode进程(在hdp-01上)
hdfs --daemon start namenode # 打开
hdfs --daemon stop namenode # 关闭
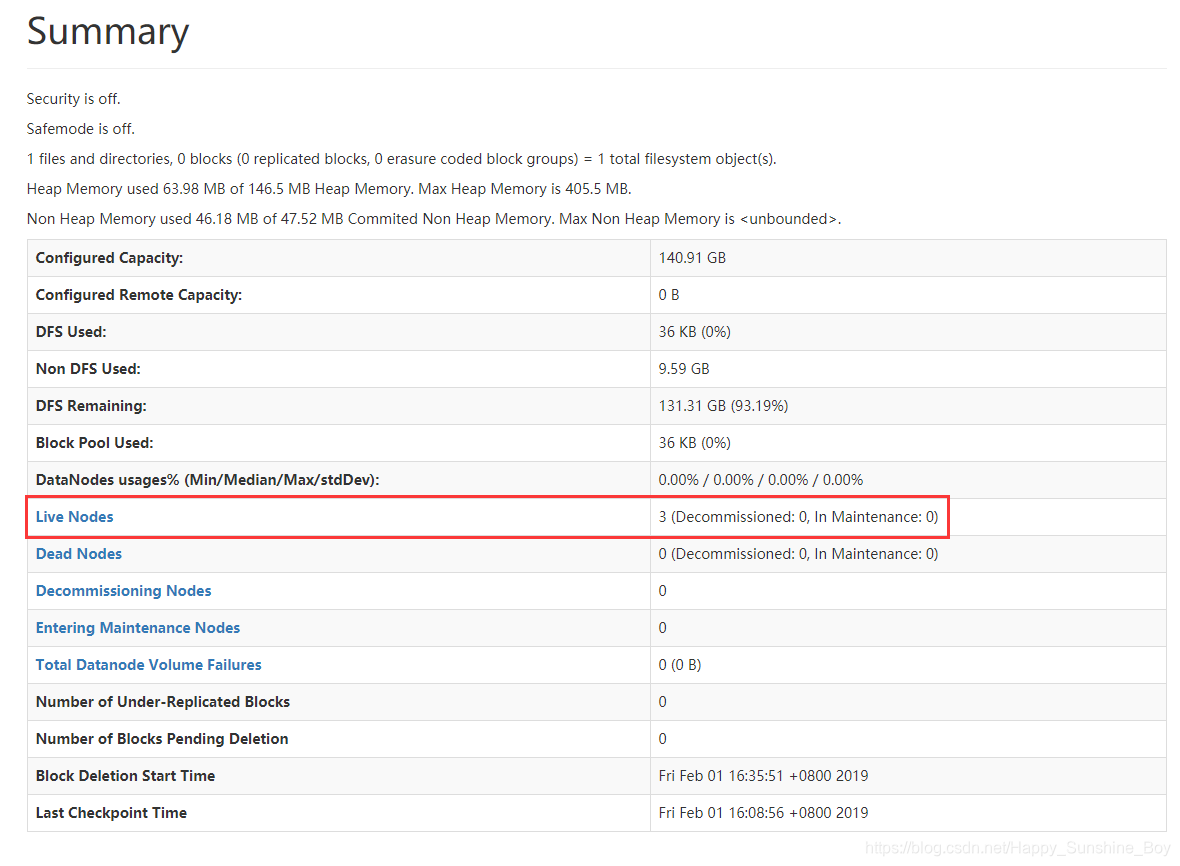
- 启动完后,首先用jps查看一下namenode的进程是否存在
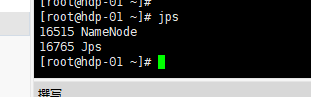
- 然后,在windows中用浏览器访问namenode提供的web端口:50070
http://hdp-01:50070
- 然后,启动众datanode们(在任意地方):
hdfs --daemon start datanode # 打开
hdfs --daemon stop datanode # 关闭