- HDFS中数据流的读写
- HDFS的HA机制
- HDFS的Federation机制
HDFS中数据流的读写
什么是RPC?
RPC(Remote Procedure Call)——远程过程调用,是一种协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。
hadoop的整个体系结构就是构建在RPC之上的,Hadoop在其内部实现了一个基于IPC模型的RPC(见org.apache.hadoop.ipc)。因为hadoop内部采用了master/slave架构,那么其内部通信和与客户端的交互就是必不可少的了。
RPC实现流程
一个典型的RPC框架主要包括以下几个部分:
通信模块:两个相互协作的通信模块实现请求–应答协议。
代理程序:客户端和服务器端均包含代理程序。
调度程序:调度程序接受来自通信模块的请求消息,并根据其中的标志选择一个代理程序处理。
一个RPC请求从发送到获取处理结果,所经历的步骤如下:
1、客户程序以本地方式调用系统产生的Stub程序;
2、该Stub程序将函数调用信息按照网络通信模块的要求封装成消息包,并交给通信模块发送到远程服务器端;
3、远程服务器端接收到此消息后,将此消息发送给相应的Stub程序;
4、Stub程序拆封消息,形成被调过程要求的形式,并调用对应的函数;
5、被调用函数按照所获参数执行,并将结果返回给Stub程序;
6、Stub将此结果封装成消息,通过网络通信模块逐级地传送给客户程序;
Hadoop RPC基本框架
Hadoop RPC主要对外提供两种接口:
public static VersionedProtocol getProxy/waitForProxy(): 构造一个客户端代理对象(该对象实现了某种协议),用于向服务器端发送RPC请求;
public static Server getServer(): 为某个协议(实际上是Java接口)实例构造一个服务器对象,用于处理客户端发送的请求;
Hadoop RPC使用方法:
1、定义RPC协议。RPC协议是客户端和服务器端之间的通信接口,他定义了服务器端对外提供的服务接口。如以下代码所示,我们定义了一个ClientProtocol通信接口,他声明了两个方法:echo()和add()需要注意的是,hadoop中所有自定义RPC接口都需要继承VersionedProtocol 接口,他描述了协议的版本信息。
interface ClientProtocol extends org.apach.hadoop.ipc.VersionedProtocol {
//版本号。默认情况下,不同版本号的RPC Client和Server之间不能相互通信
public static final long versionID = 1L;
String echo(String value) throws IOException;
int add(int v1,int v2) throws IOException;
}
2、实现RPC协议。Hadoop RPC协议通常是一个Java接口,用户需要实现接口,如以下代码所示,对ClientProtocol接口进行简单的实现:
public static class ClientProtocolImpl implements ClientProtocol {
public long getProtocolVersion(String protocol , long clientVersion){
return ClientProtocol.versionID;
}
public String echo(String value) throws IOException {
return value;
}
public int add(int v1,int v2) throws IOException{
return v1+v2;
}
}
3、构造并启动RPC Server。直接使用new RPC.Builder(conf)构造一个RPC Server,并调用函数start()启动该Server:
public class MyServer {
public static final String ADDRESS="localhost";
public static final int PORT = 2454;
public static void main(String[] args)throws Exception {
final Server server = new RPC.Builder(new Configuration()).setProtocol(ClientProtocol.class)
.setInstance(new ClientProtocolImpl()).setBindAddress(ADDRESS).setPort(MyServer.PORT)
.setNumHandlers(5).build();
server.start();
}
}
其中,setBindAddress和setPort分别表示服务器的host和监听端口号,而setNumHandlers表示服务器端处理请求的线程数目,到此为止,服务器处理监听状态,等待客户端请求到达。
4、构造RPC Client,并发送RPC请求。使用静态方法getProxy()构造客户端代理对象,直接通过代理对象调用远程端的方法,具体如下所示:
public class MyClient {
public static void main(String[] args) throws Exception {
ClientProtocol proxy = (ClientProtocol) RPC.getProxy(
ClientProtocol.class, 1L, new InetSocketAddress(
MyServer.ADDRESS, MyServer.PORT), new Configuration());
final int result = proxy.add(3, 5);
String r = proxy.echo(result+"");
System.out.println(r);
}
}
经过以上四步,我们便利用Hadoop RPC搭建了一个非常高效的客户机/服务器网络模型。
RPC Server
Hadoop RPC的实现主要在org.apache.hadoop.ipc
Server:RPC Server实现了一种抽象的RPC服务,同时提供Call队列。
RPC Server结构:
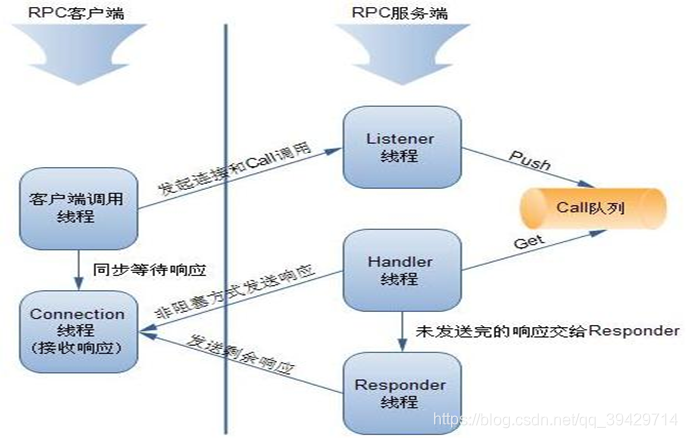
Server.Listener:RPC Server的监听者,用来接收RPC Client的连接请求和数据,其中将数据封装成CALL后PUSH到CALL队列中。
Server.Handler:RPC Server的CALL处理者,和Server.Listener通过CALL队列交互。
Server.Responder:RPC Server响应者,Server.Handler按照异步非阻塞的方式向RPC Client发送响应,如果有未发送出去的数据,交由Server.Responder来处理完成。
Server.Connection:RPC Server数据的接收者。提供接收数据,解析数据包的功能。
Server.Call:持有客户端的Call信息。
RPC Server作为服务的提供者主要有两部分组成:接收Call调用和处理Call调用。
接收Call调用负责接收来自RPC Client的调用请求,编码成Call对象放入到Call队列中,这一过程有Server.Listener完成。具体步骤如下:
1.Listener线程监听RPC Client发过来的数据
2.当有数据可以接收时,调用Connection的readAndProcess方法
3.Connection边接受数据边处理数据,当接到一个完整的Call包,则构建一个Call对象,PUSH到Call 队列中,有Handler来处理Call队列中的所有Call
处理完的Call调用负责处理Call队列中的每一个调用请求,由Handler线程来完成。
4.Handler线程监听Call队列,如果Call队列非空,按FIFO规则从Call队列中取出Call
5.将Call交给RPC.Server来处理
6.借助JDK提供的Method,完成对目标方法的调用,目标方法由具体的业务逻辑实现
7.返回响应。Server.Handler按照异步非阻塞的方式向RPC Client发送响应,如果有未发送出的数据,则交由Server.Responder来完成。
完整的交互过程如下图所示:
RPC Client
RPC Client 结构:
Client.ConnectionId:到RPC Server对象连接的标识。
Client.Call:Call调用信息。
Client.ParallelResults:Call响应。
RPC.Invoker: 对InvocationHandler的实现,提供invoke方法,实现RPC Client对RPC Server对象的调用。
RPC.Invocation:用来序列化和反序列化RPC Client的调用信息。(主要应用JAVA的反射机制和InputStream/OutputStream)
RPC Client主要流程
- RPC Client发起RPC Call,通过JAVA反射机制
转化为对Client.call调用
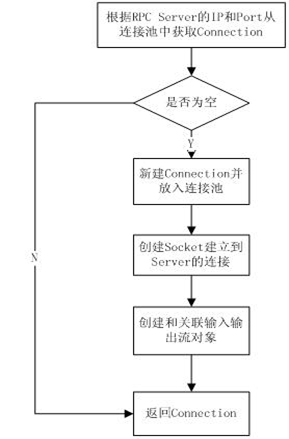
2.调用getConnection得到与RPC Server的链接,
每一个RPC Client都维护一个HashMap结构的
到RPC Server的连接池。如图所示:
3.通过Connection将序列化后的参数发送到RPC
服务端
4.阻塞方式等待RPC服务端返回响应。
RPC实现模型
需要详细说的是RPC在服务端的模型,它由一系列实体组成,分别负责调用的整个流程,如图所示:
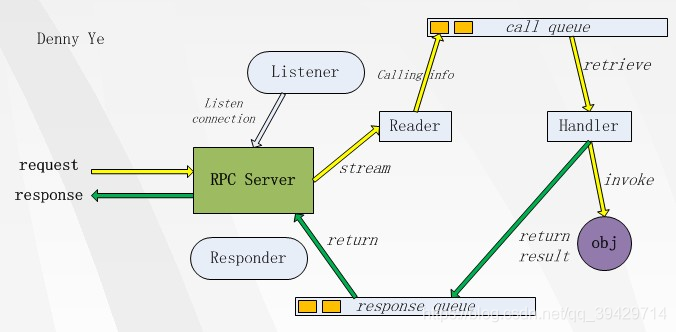
Listener
监听RPC server的端口,如果客户端有连接请求到达,它就接受连接,然后把连接转发到某个Reader,让Reader去读取那个连接的数据。如果有多个 Reader的话,当有新连接过来时,就在这些Reader间顺序分发。
Reader
Reader的职责就是从某个客户端连接中读取数据流,然后把它转化成调用对象(Call),然后放到调用队列(call queue)里
Handler
真正做事的实体。它从调用队列中获取调用信息,然后反射调用真正的对象,得到结果,然后再把此次调用放到响应队列(response queue)里
Responder
它不断地检查响应队列中是否有调用信息,如果有的话,就把调用的结果返回给客户端。
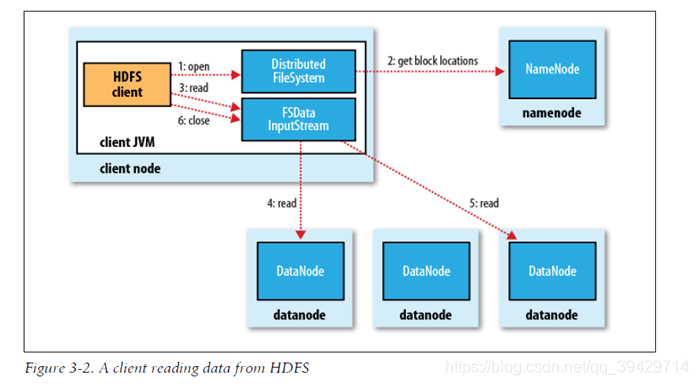
文件读取流程
1、使用HDFS提供的客户端Client,向远程的Namenode发起RPC请求;
2、Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的DataNode地址;
3、客户端Client会选取离客户端最近的DataNode来读取block;如果客户端本身就是DataNode,那么将从本地直接获取数据;
4、读取完当前block的数据后,关闭当前的DataNode链接,并为读取下一个block寻找最佳的DataNode;
5、当读完列表block后,且文件读取还没有结束,客户端会继续向Namenode获取下一批的block列表;
6、读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
客户端及读取HDFS中的数据的流程图,如下图所示:
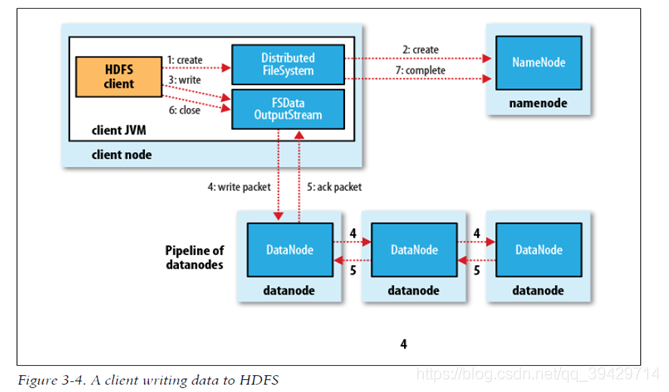
文件写入流程
1、使用HDFS提供的客户端Client,向远程的Namenode发起RPC请求
2、Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
3、当客户端开始写入文件的时候,客户端会将文件切分成多个packets,并在内部以数据队列“data queue(数据队列)”的形式管理这些packets,并向Namenode申请blocks,获取用来存储replicas的合适的datanode列表,列表的大小根据Namenode中replication的设定而定;
4、开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
5、最后一个datanode成功存储之后会返回一个ack packet(确认队列),在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
6、如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。
7、客户端完成数据的写入后,会对数据流调用close()方法,关闭数据流;
8、只要写入了dfs.replication.min的复本数(默认为1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标复本数(dfs.replication的默认值为3),因为namenode已经知道文件由哪些块组成,所以它在返回成功前只需要等待数据块进行最小量的复制。
客户端将数据写入HDFS的流程图,如下图所示:
文件的一致模型
文件系统的一致模型(coherency model)描述了对文件读/写的数据可见性,HDFS为性能牺牲了一些POSIX要求,因此一些操作与你期望的可能不同。
在创建一个文件之后,希望它能在文件系统的命名空间中立即可见,例如:path p = new path(“p”);
Fs.create§;
assertThat(fs.exists§, is(true));
但是,写入文件的内容并不保证能立即可见,即使数据流已经刷新并存储。所以文件长度显示为0:
path p = new path(“p”);
OutputStream out = fs.create§;
Out.write(“content”.getBytes(“UTF - 8”));
Out.flush();
assertThat(fs.getfIleStatus§.getLen(), is(0L));
一旦写入的数据超过一个块的数据,新的读取者就能看见第一个块。对于之后的块也是这样。总之,它始终是当前正在被写入的块时,其他读取者是看不见它的。
HDFS提供一个方法来强制所有的缓存与数据节点同步, 即对FSDataOutputStream调用sync()方法。当sync()方法返回成功后,对所有新的reader而言,HDFS能保证文件中到目前为止写入的数据均可见且一致:
Path p = new path(“p”);
FSDataOutputStream out = fs.create§;
Out.write(“content”.getBytes(“UTF - 8”));
Out.flush();
Out.sync();
assertThat(fs.getFileStatus§.getLen(),is(((long)”content”.length())));
该类操作类似于Unix中的fsync系统调用——为一个文件描述符提交缓冲数据,例如:利用Java API写入一个本地文件,我们肯定能够看到刷新流和同步之后的内容。
在HDFS中关闭一个文件其实还执行了一个隐含的sync()。
应用设计的重要性
这个一致模型与具体设计应用程序的方法有关。如果不调用sync(),那么一旦客户端或系统发生故障,就可能失去一个块的数据。对很多应用来说,这是不可接受的,所以我们应该在适当的地方调用sync(),例如在写入一定的记录或字节之后。尽管sync()操作被设计为尽量减少HDFS负载,但它仍然有开销,所以在数据健壮性和吞吐量之间就会有所取舍。应用依赖就比较能接受,通过不同的sync()频率来衡量应用程序,最终找到一个合适的平衡。
HDFS的HA机制
HDFS 的HA 功能通过配置Active/Standby 两个NameNodes 实现在集群中对NameNode 的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode 很快的切换到另外一台机器。
HA的集群架构
1、在一个典型的HDFS(HA) 集群中,使用两台单独的机器配置为NameNodes 。在任何时间点,确保NameNodes 中只有一个处于Active 状态,其他的处在Standby 状态。其中ActiveNameNode 负责集群中的所有客户端操作,StandbyNameNode 仅仅充当备机,保证一旦ActiveNameNode 出现问题能够快速切换。
2、为了能够实时同步Active和Standby两个NameNode的元数据信息(实际上editlog),需提供一个共享存储系统,可以是NFS、QJM(Quorum Journal Manager)或者Bookeeper,Active Namenode将数据写入共享存储系统,而Standby监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与Active NameNode保持基本一致,如此这般,在紧急情况下standby便可快速切为active namenode。
3、为了实现快速切换,Standby 节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标,DataNode 需要配置NameNodes 的位置,并同时给他们发送文件块信息以及心跳检测。
HA架构图
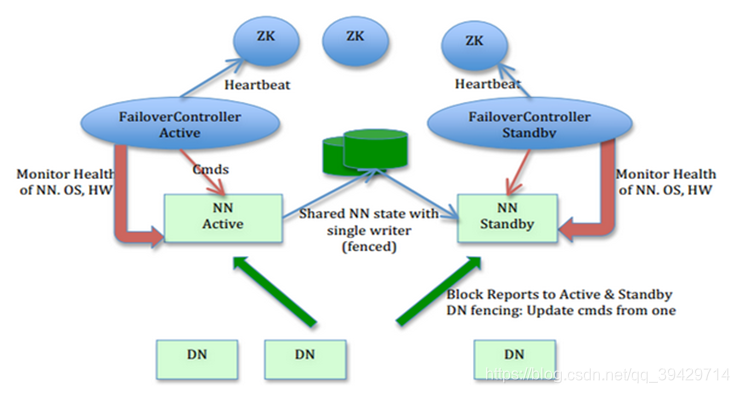
注意:Secondary NameNode。它不是HA,它只是阶段性的合并edits和fsimage,以缩短集群启动的时间。当NameNode失效的时候,Secondary NN并无法立刻提供服务,Secondary NN甚至无法保证数据完整性:如果NN数据丢失的话,在上一次合并后的文件系统的改动会丢失。
HDFS的Federation机制
为什么要有Federation机制呢?
前面说了在Hadoop 2.0之前,HDFS的单NameNode设计带来诸 多问题,包括单点故障、内存受限,制约集群扩展性和缺乏隔离机制(不同业务使用同一个NameNode导致业务相互影响)等,为了解决这些问题,除了用基于共享存储的HA解决方案我们还可以用HDFS的Federation机制来解决这个问题。
什么是Federation机制?
HDFS Federation是指HDFS集群可同时存在多个NameNode,这些NameNode分别管理一部分数据,且共享所有DataNode的存储资源。
这种设计可解决单NameNode存在的以下几个问题:
(1)HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再像1.0中那样由于内存的限制制约文件存储数目。
(2)性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
(3)良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
需要注意的,HDFS Federation并不能解决单点故障问题,也就是说,每个NameNode都存在在单点故障问题,你需要为每个namenode部署一个backup namenode以应对NameNode挂掉对业务产生的影响。
Federation架构图,如下所示:
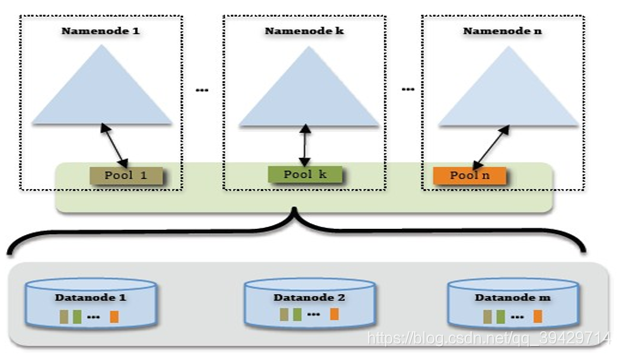
1、为了水平扩展namenode,federation使用了多个独立的namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
2、一个block pool由属于同一个namespace的数据块组成,每个datanode可能会存储集群中所有block pool的数据块。
3、每个block pool内部自治,也就是说各自管理各自的block,不会与其他block pool交流。一个namenode挂掉了,不会影响其他namenode。
4、某个namenode上的namespace和它对应的block pool一起被称为namespace volume。它是管理的基本单位。当一个namenode/nodespace被删除后,其所有datanode上对应的block pool也会被删除。当集群升级时,每个namespace volume作为一个基本单元进行升级。
多命名空间管理
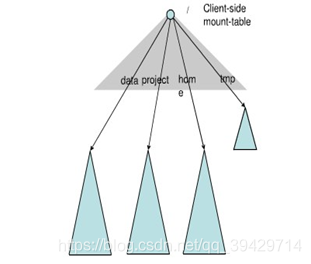
Federation中存在多个命名空间,如何划分和管理这些命名空间非常关键。在Federation中并采用“文件名hash”的方法,因为该方法的locality非常差,比如:查看某个目录下面的文件,如果采用文件名hash的方法存放文件,则这些文件可能被放到不同namespace中,HDFS需要访问所有namespace,代价过大。为了方便管理多个命名空间,HDFS Federation采用了经典的Client Side Mount Table。
如图所示,下面四个深色三角形代表一个独立的命名空间,上方浅色的三角形代表从客户角度去访问的子命名空间。各个深色的命名空间Mount到浅色的表中,客户可以访问不同的挂载点来访问不同的命名空间,这就如同在Linux系统中访问不同挂载点一样。这就是HDFS Federation中命 名空间管理的基本原理:将各个命名空间挂载到全 局mount-table中,就可以做将数据到全局共享; 同样的命名空间挂载到个人的mount-table中,这 就成为应用程序可见的命名空间视图。
Federation不足之处
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。
总结
1、了解RPC的实现流程及模型
2、要重点掌握文件读取和写入的流程图,理解每一步的做了什么,是什么样的一个流程。
3、掌握HDFS的HA机制(NN的单点故障),了解HA集群的架构以及HA机制的具体流程。
4、了解HDFS的Federation机制,Federation架构以及Federation多命名空间的管理。