本章小结
本章讨论分类问题。分类的⽬标是将输⼊变量x分到K个类别
中的某⼀类。最常见的情况是,类别互不相交,每个输⼊被分到唯⼀一个类别中。因此输⼊空间被划分为不同的决策区域,它的边界被称为决策边界或者决策⾯。在本章中,考虑分类的线性模型的,即决策面是输⼊向量x的线性函数,因此被定义为D维输⼊空间中的(D − 1)维超平⾯(附录部分会对这个做解释)。如果数据集可以被线性决策⾯精确地分类,那么这个数据集是线性可分的。
对于概率模型来说,在⼆分类情况下,最⽅便的表达⽅式是⼆元表⽰⽅法,即⽬标变量
,其中t = 1表⽰类别
,⽽t = 0表⽰类别
,我们可以把t的值看成分类结果为
的概率,这个概率只取极端的值0和1。多类情况下(K > 2),一般使⽤“1-of-K”编码规则,t是⼀个长度为K的向量,如果类别为
,那么t的所有元素
中,只有
等于1,其余都等于0。例如,如果我们有5个类别,那么来⾃第2个类别的模式给出的⽬标向量为
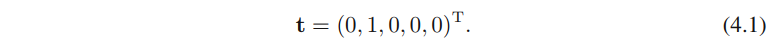
本章介绍三种分类方法(正如在1.5.4节中所介绍的):
- 判别函数法:直接把输入向量x分到具体的类别中
- 概率生成式方法:分为推断和决策两个阶段。推断阶段对类先验概率 和类条件概率 分别建模,再根据贝叶斯定理 得出类的后验概率。决策阶段使用类的后验概率分布进⾏最优决策。
- 概率判别式方法:分为推断和决策两个阶段。推断阶段直接对 建模,决策阶段使用类的后验概率分布进⾏最优决策。
后面的4.1-4.3小节分别对三种分类方法进行介绍。
附录
问题整理
- 分类的线性模型的中,为什么决策面是D维输⼊空间中的(D − 1)维超平⾯?
在线性模型中,决策面为 。x的维度是D,则 即是D维输⼊空间中的(D − 1)维超平⾯。
后续工作
4.4、4.5两节还未完全看完。