1.收敛速度慢
解决:
- 设置合理的初始化权重w和偏置b
模型训练本质上就是调整w和b的过程,好的开始是成功的一半。(为什么不0初始化?哪三种常用的初始化方法?https://blog.csdn.net/weixin_43167121/article/details/88176101) - 优化学习率
学习率太小,会增加迭代次数,加大训练时间。但学习率太大,容易越过局部最优点,降低准确率。
所以应当一开始学习率大一些,从而加速收敛。训练后期学习率小一点,从而稳定的落入局部最优解。使用Adam,Adagrad等自适应优化算法,就可以实现学习率的自适应调整,从而保证准确率的同时加快收敛速度。 - 网络节点输入值正则化 batch normalization
神经网络训练时,每一层的输入分布都在变化。不论输入值大还是小,我们的学习率都是相同的,这显然是很浪费效率的。而且当输入值很小时,为了保证对它的精细调整,学习率不能设置太大。那有没有办法让输入值标准化得落到某一个范围内,比如[0, 1]之间呢,这样我们就再也不必为太小的输入值而发愁了。
当然有!可以对每一个mini-batch数据内部进行标准化,使他们规范化到[0, 1]内。这就是Batch Normalization。 它在每个卷积层后,使用一个BN层,从而使得学习率可以设定为一个较大的值。 - 采用更先进的网络结构,减少参数量
训练速度慢,归根结底还是网络结构的参数量过多导致的。减少参数量,可以大大加快收敛速度。
1)使用小卷积核来代替大卷积核。VGGNet全部使用3x3的小卷积核,来代替AlexNet中11x11和5x5等大卷积核。
2)1x1卷积核的使用。1x1的卷积核可以说是性价比最高的卷积了,没有之一。它在参数量为1的情况下,同样能够提供线性变换,relu激活,输入输出channel变换等功能。VGGNet创造性的提出了1x1的卷积核。
3)全局平均池化代替全连接层。这个才是大杀器!
AlexNet和VGGNet中,全连接层几乎占据了90%的参数量。inceptionV1创造性的使用全局平均池化来代替最后的全连接层,使得其在网络结构更深的情况下(22层,AlexNet仅8层),参数量只有500万,仅为AlexNet的1/12
2.过拟合问题
过拟合在机器学习中广泛存在,指的是经过一定次数的迭代后,模型准确度在训练集上越来越好,但在测试集上却越来越差。究其原因,就是模型学习了太多无关特征,将这些特征认为是目标所应该具备的特征。
- 输入增强,增大样本量
可以使用输入增强方法。对样本进行旋转,裁剪,加入随机噪声等方式,可以大大增加样本数量和泛化性。
也可以收集更多且更全的样本。 - dropout,减少特征量
使用dropout,将神经网络某一层的输出节点数据随机丢弃,从而减少特征量。这其实相当于创造了很多新的随机样本。一般在神经网络的全连接层使用dropout。
3.线性模型的局限性
线性模型的特点是,任意线性模型的组合仍然是线性模型。不论我们采用如何复杂的神经网络,它仍然是一个线性模型。然而线性模型能够解决的问题毕竟是有限的,所以必须在神经网络中增加一些非线性元素。
解决:
- 激活函数的使用
在每个卷积后,加入一个激活函数,已经是通用的做法。激活函数,如relu,tanh,sigmod都是非线性函数。
相比于tanh和sigmod,relu的优点有:
1)计算速度快,容易收敛。relu就是一个取max的函数,没有复杂的运算,故计算速度很快。
2)不会梯度消失。x>0时,relu的梯度为1。
4.梯度弥散, 无法使用更深的网络
- relu代替sigmoid激活函数
- 残差网络
大名鼎鼎的resNet将一部分输入值不经过正向传播网络,而直接作用到输出中。这样可以提高原始信息的完整性了,从而在反向传播中,可以指导前面几层的参数的调整了。如下图所示。
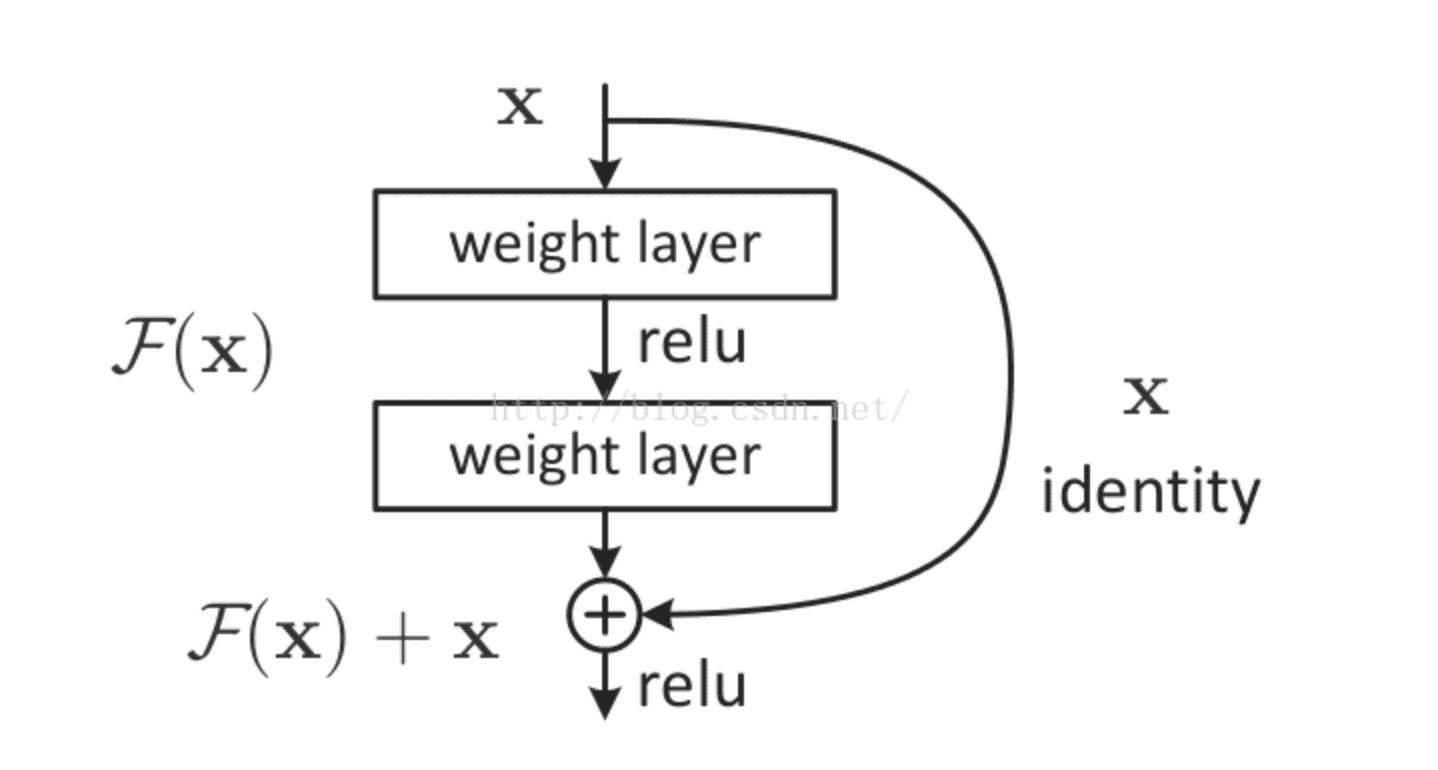
使用了残差网络的resNet,将网络深度提高到了152层,大大提高了模型的泛化性,从而提高了预测准确率